
Kaggleの中でも特に有名な課題として「Titanic : Machine Learning from Disaster」(意訳:タイタニック号:災害からの機械学習)があります。先日に「Kaggleとは?機械学習初心者が知っておくべき3つの使い方」にて、初心者向けのKaggleの利用のコツをまとめましたが、今回はKaggleで公開されている実際のデータセットを使って、機械学習で予測を作って投稿してみましょう。
この記事の概要と対象者
今回のKaggle紹介記事では、Kaggle初心者向けに公開されているデータセットを使って「タイタニックの生存者予測」をPythonを使って行います。Pythonはある程度使えるけど・・機械学習を触ったことが無い、とりあえず機械学習をやってみたい、という方に向けた記事です。(機械学習中〜上級者の方には、物足りない内容です)
このチュートリアルで使うもの
- Python 3.X
- Pandas
- Numpy
- scikit-learn
行う内容
- データセットの確認
- データセットの事前処理
- 「決定木」予測その1
- 「決定木」予測その2
- まとめ
Pythonを使ってデータを読み込むところから、実際に機械学習のモデルを作成・予測してKaggleへデータを投稿するところまで、手順をまとめています。ぜひ、ご自身のパソコンを使って同じ手順を踏んでみてください。
また、私は便宜上、jupyter notebookを使用しています。pythonを直接叩いても当然処理は可能ですが、プログラムの保存・共有も簡単ですし、「セルコーディング」と呼ばれるセル単位でメモやコーディングが可能なメリットもあります。機械学習をやっている肩であれば、使っている人も多いので、まだ導入されていない方がいれば、是非この機会にインストールしてみてください。
https://jupyter.readthedocs.io/en/latest/install.html (リンク先英語)
まずはデータセットの確認&事前処理
機械学習では「データセットが9割の仕事を占める」と言われているくらい、データセットの確認や事前処理が非常に重要な意味合いを持ちます。では、実施にKaggleからデータをダウロードして、今回使うデータの内容を確認して行きましょう。
Kaggle無料会員登録&CSVダウンロード
Kaggleの利用には無料会員登録が必要となります。まだアカウントをお持ちでいない方は、こちらから登録をしましょう。
登録が完了したら、Kaggleタイタニックのデータページへ移動をお願いします。こちらのページにて今回使う下記のCSVのダウロードをしましょう。
- train.csv (59.76 KB)
- test.csv(27.96 KB)
Kaggleタイタニックの課題ですが、実施のコンペティション(コンペ課題)とは異なり、Kaggle側が用意した機械学習初心者向けの課題となっています。ですので、提供されているデータも非常に作りは単純で、またファイルサイズも小さいことから、とても扱いやすいデータとなっています。
また、全て英語での説明となりますが、「Data」のページでは提供されているデータセットの詳細の説明も記載されています。コンペへ参加をする場合は、必ずこのDataページの説明を熟読しましょう。
CSVを読み込んで内容を確認しましょう
今回のチュートリアルではNumpyとPandasを使いますので、インポートをして、先ほどダウロードした「train.csv」と「test.csv」をデータフレーム形式で読み込みましょう。csvの格納先のディレクトリは各自、指定をしてから読み込みをしましょう。
|
1 2 3 4 5 6 7 8 |
import pandas as pd import numpy as np train = pd.read_csv("../ディレクトリを指定/train.csv") test = pd.read_csv("../ディレクトリを指定/test.csv") |
各csvに何が含まれているか、まずは確認をしてみましょう。
|
1 2 3 4 |
train.head() |

Pandasのhead()を使うと、データフレームの最上部5段がデフォルトで表示されます。つまり、上の表は「train.csv」のカラム名と最上部5段の情報となります。各カラムの簡単な説明をは以下の通りです。
- PassengerId – 乗客識別ユニークID
- Survived – 生存フラグ(0=死亡、1=生存)
- Pclass – チケットクラス
- Name – 乗客の名前
- Sex – 性別(male=男性、female=女性)
- Age – 年齢
- SibSp – タイタニックに同乗している兄弟/配偶者の数
- parch – タイタニックに同乗している親/子供の数
- ticket – チケット番号
- fare – 料金
- cabin – 客室番号
- Embarked – 出港地(タイタニックへ乗った港)
以上が訓練データとして提供されている項目となります。さらに各変数の簡単な説明も記載をしておきます。
pclass = チケットクラス
1 = 上層クラス(お金持ち)
2 = 中級クラス(一般階級)
3 = 下層クラス(労働階級)
Embarked = 各変数の定義は下記の通り
C = Cherbourg
Q = Queenstown
S = Southampton
では、次に test.csv も内容を簡単に確認してみましょう。
|
1 2 3 4 |
test.head() |
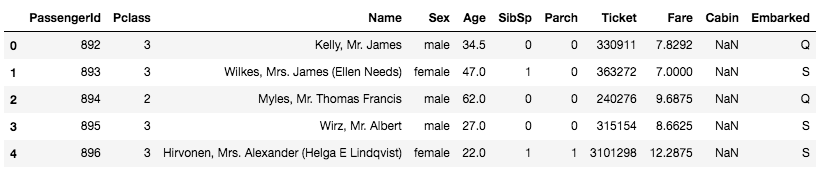
こちらの test には、Survivedのカラムが無いのが確認できます。他のカラムは train と同様です。つまり、 train の乗客の情報と「Survived(生存したかどうか)」の答えを機械学習して、 test で提供されている乗客情報を元に、生存したか死亡したかの予測を作るのが課題ということです。
train と test の簡単な統計情報とサイズも確認しておきましょう。|
1 2 3 4 5 6 7 8 |
test_shape = test.shape train_shape = train.shape print(test_shape) print(train_shape) |
|
1 2 3 4 5 |
(418, 11) (891, 12) |
次にpandasのdescribe()を使って、各データセットの基本統計量も確認しておきましょう。
|
1 2 3 4 5 |
test.describe() train.describe() |
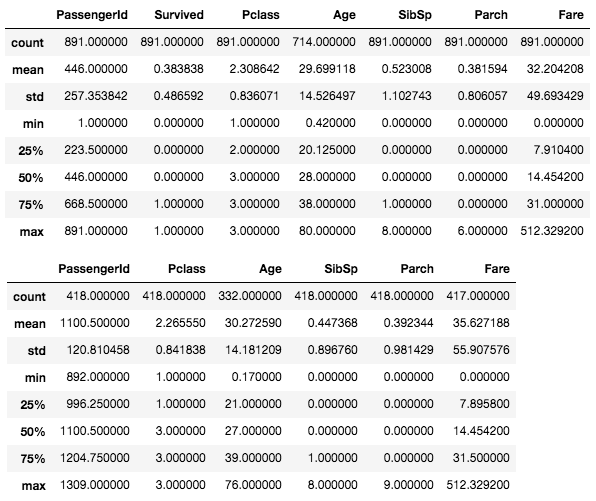
上記表の上が train で下が test の統計量情報となります。
各データのshapeを確認した通り、両データ共に「PassengerId」はTrain=891カウント、test=418カウントと一致していますね。どうやら「Age」など一部のカラムでカウント数が少ない=つまり欠損データがあるようです。
次は両データセットの欠損データを確認していきましょう。
データセットの欠損の確認
提供されている(または使う)データセットで100%データが揃っていることの方が珍しいくらいです。どこかのデータが欠損してたり、信用性が低いため使えなかったりする場合がほとんどです。
dataframeの欠損データをisnull()で探して、カラム毎に返す関数kesson_table()を作って、 train と test のデータフレームの欠損を確認しましょう。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
def kesson_table(df): null_val = df.isnull().sum() percent = 100 * df.isnull().sum()/len(df) kesson_table = pd.concat([null_val, percent], axis=1) kesson_table_ren_columns = kesson_table.rename( columns = {0 : '欠損数', 1 : '%'}) return kesson_table_ren_columns kesson_table(train) kesson_table(test) |
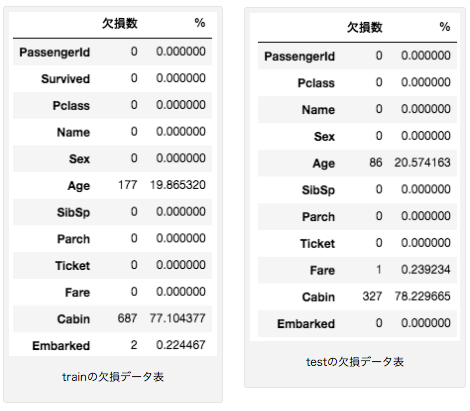
左が train で右が test の欠損データを表しています。思ったよりもしっかりとしたデータではありますが、特に「Age」と「Cabin」の2つの項目で欠損が多いですね。
では、欠損データを含めたデータの事前処理を次は行なっていきましょう!
データセットの事前処理
データセットの事前処理が一番重要ですが、今回はあくまでKaggle初心者向けチュートリアルですので、基本的なことを行なっていきます。このチュートリアルで行う内容としては・・
(1) 欠損データを代理データに入れ替える
(2) 文字列カテゴリカルデータを数字へ変換
の2つの事前処理を行なっていきましょう!
では、まずは欠損データへ代わりとなる代理データを入れていきましょう。
まずは train から綺麗にしていきましょう。先に確認しましたが、 train では「Age」「Embarked」「Cabin」の3カラムに欠損データがありましたね。今回のチュートリアルでは「Cabin」は予測モデルで使わないので、「Age」と「Embarked」の2つの欠損データを綺麗にしていきましょう。
まず「Age」ですが、シンプルに train の全データの中央値(Median)を代理として使いましょう。(代理データで何を使うか、どのような処理を加えるかは非常に重要かつ大きな議論ではありますが、ここはシンプルに考えて進めます)
次に「Embarked」(出港地)ですが、こちらも2つだけ欠損データが train に含まれています。他のデータを確認すると「S」が一番多い値でしたので、代理データとして「S」を使いましょう。
|
1 2 3 4 5 6 7 8 |
train["Age"] = train["Age"].fillna(train["Age"].median()) train["Embarked"] = train["Embarked"].fillna("S") kesson_table(train) |
各カラムでfillna()を使って代理となるデータを入れておきましょう。先ほど作ったkesson_table()で年のため欠損データがないかどうか確認をしましょう。Cabinは今回は使いませんので欠損データがあっても大丈夫ですが、「Age」「Embarked」の欠損は埋まりましたね。
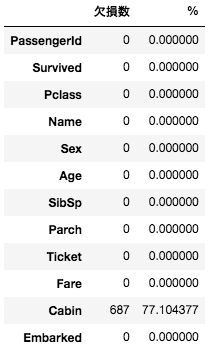
trainの欠損データを代理データで埋めました
欠損データの処理が終わりましたので、次はカテゴリカルデータの文字列を数字に変換しましょう。今回の予想で使う項目で文字列を値として持っているカラムは「Sex」と「Embarked」の2種類となります。Sexは「male」「female」の2つのカテゴリー文字列、Embarkedはは「S」「C」「Q」の3つの文字列となります。これらを数字に変換しましょう。
|
1 2 3 4 5 6 7 8 9 10 |
train["Sex"][train["Sex"] == "male"] = 0 train["Sex"][train["Sex"] == "female"] = 1 train["Embarked"][train["Embarked"] == "S" ] = 0 train["Embarked"][train["Embarked"] == "C" ] = 1 train["Embarked"][train["Embarked"] == "Q"] = 2 train.head(10) |
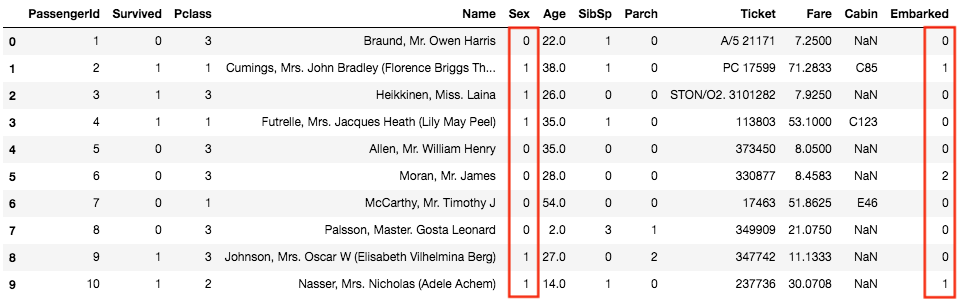
上記の通り、SexとEmbarkedに入っていた文字列の値が、数字へ変換されていることが確認できます。これで train の前処理は終わりましたが、次は test も同様の処理を行わないといけません。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
test["Age"] = test["Age"].fillna(test["Age"].median()) test["Sex"][test["Sex"] == "male"] = 0 test["Sex"][test["Sex"] == "female"] = 1 test["Embarked"][test["Embarked"] == "S"] = 0 test["Embarked"][test["Embarked"] == "C"] = 1 test["Embarked"][test["Embarked"] == "Q"] = 2 test.Fare[152] = test.Fare.median() test.head(10) |
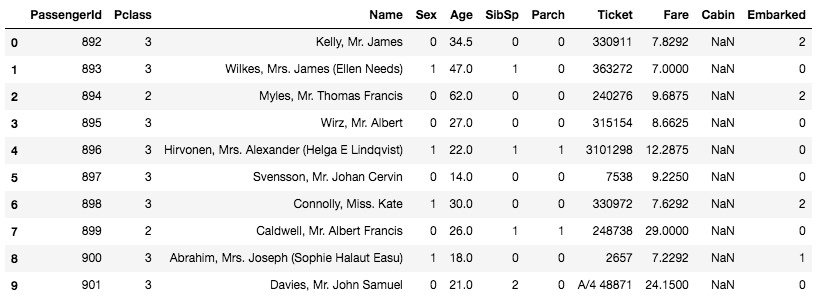
同様に「Age」へは中央値(Median)の代入、また文字列の値(AgeとEmbarked)は数字に変換しました。さらに、 test では、「Fare」に一つだけ欠損がありましたので、こちらも年齢と同様に中央値(Median)を代理で入れています。念のためhead()でデータの中身も確認をしておきましょう。
予測モデル その1 「決定木」
データの確認、事前処理も終わりましたので、とうとう本題の予測モデルを作って、実際に予測をしてみましょう!本記事では予測モデル「決定木」を異なるデータで訓練して、結果を比較してみようと思います。
「決定木」ですが、scikit-learnとNumpyを使えば非常に簡単に作成することが可能です。
まず初めに作る予測モデル「その1」ですが「Pclass」「Sex」「Age」「Fare」の4つの項目を使って「Survived(生存可否)」を予測してみましょう。別の言い方で表すと、タイタニックに乗船していた客の「チケットクラス(社会経済的地位)」「性別」「年齢」「料金」のデータを元に生存したか死亡したかを予測するとも言えます。
では実際に作ってみましょう。
まず、scikit-learnのインポートを行いましょう。
|
1 2 3 4 5 |
# scikit-learnのインポートをします from sklearn import tree |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
# 「train」の目的変数と説明変数の値を取得 target = train["Survived"].values features_one = train[["Pclass", "Sex", "Age", "Fare"]].values # 決定木の作成 my_tree_one = tree.DecisionTreeClassifier() my_tree_one = my_tree_one.fit(features_one, target) # 「test」の説明変数の値を取得 test_features = test[["Pclass", "Sex", "Age", "Fare"]].values # 「test」の説明変数を使って「my_tree_one」のモデルで予測 my_prediction = my_tree_one.predict(test_features) |
まず決定木で使うTargetとFeatureの値を train から取得して格納しておきます。
次にscikit-learnの「DecisionTreeClassifier()」を使って「my_tree_one」という決定木モデルを作成しました。
最後に事前に綺麗に処理をしておいた test から train で使ったFeatureと同様の項目の値を「test_features」へ入れて、predict()を使って予測をしました。
予測されたデータを確認してみましょう。
|
1 2 3 4 5 |
# 予測データのサイズを確認 my_prediction.shape |
|
1 2 3 4 |
(418,) |
|
1 2 3 4 5 |
#予測データの中身を確認 print(my_prediction) |

予測をしなくてはいけないデータ数、つまり test のデータ数は418個でしたが、上記の通りmy_predictionも同じ数の予測数が結果として出力されていますね。今回の予測は「0か1(生存か死亡)」でしたが、念のため中身も確認してみると0と1で構成されているのが確認できます。
では、この予測データをCSVへ書き出してKaggleへ早速投稿してみましょう!下記のコードでPassengerIdと予測値を取得してCSVファイルを書き出します。
|
1 2 3 4 5 6 7 8 9 10 11 |
# PassengerIdを取得 PassengerId = np.array(test["PassengerId"]).astype(int) # my_prediction(予測データ)とPassengerIdをデータフレームへ落とし込む my_solution = pd.DataFrame(my_prediction, PassengerId, columns = ["Survived"]) # my_tree_one.csvとして書き出し my_solution.to_csv("my_tree_one.csv", index_label = ["PassengerId"]) |
Python(またはJupyter Notebook)が立ち上がっている場所へ「my_tree_one.csv」が作成されていると思いますので、こちらのファイルをKaggleへ投稿してみましょう。
Kaggleへログインをしてタイタニックページへ移動をすると、上部メニュに「Submit Predictions」という項目がありますので、こちらをクリックしましょう。
同ページの下部にファイルアップローダーがありますので、こちらで先ほど書き出した「my_tree_one.csv」をアップロードして「Make Submission」をクリックしましょう。
投稿をすると次のページへ自動的に遷移します。さて、気になる結果ですが・・
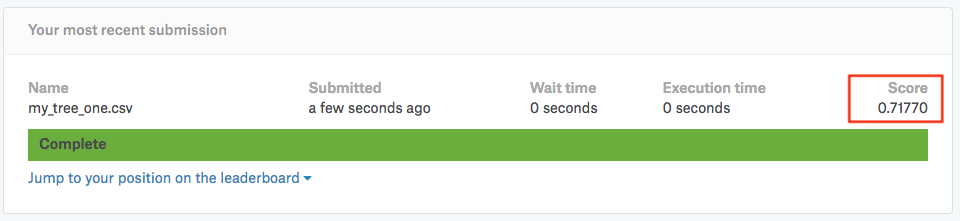
ファイルがKaggleの投稿基準を満たしていると、即座にスコアを計算して表示してくれます。
「my_tree_one」は「チケットクラス(社会経済的地位)」「性別」「年齢」「料金」の4つのデータを用いて「決定木」のモデルを使い予測を行いましたが、結果として「0.71770」のスコアが獲得できました。
Kaggleのスコアはコンペにより異なります。各コンペの「Evaluation」のページに詳細が記載されています。今回予測を行なったタイタニックのコンペでは予測スコアは単純に「Accuracy(正解率)」が使われていますので、今作った「my_tree_one」は約71.8%の確率で正解を予測できましたということになります。
参考までにですが、Kaggleタイタニックのランキングを見てみると「0.71770」のスコアですと、約8600位前後となります。(*このタイタニックの予測課題ですが、実は100%(つまりスコア1.0)を叩き出している強者データサイエンティストもいます。インターネットにその手法も公開されています。)
では、次はこの71.8%のスコアよりももう少し正確なモデルを作って見ましょう!
予測モデル その2 「決定木 + 7つの説明変数」
さて、予測モデルその1では「タイタニックに乗船していた客の「チケットクラス」「性別」「年齢」「料金」のデータを元に生存したか死亡したかを予測」しました。Kaggleで答え合わせをすると「約71.8%」の正解率でした。
では・・この正解率を上げるためにはどうすれば良いでしょうか?
少し考えて見てください
・・・
・・・
色々と試せることはあるかと思いますが、パッと思いつく限りだと、予測モデルの訓練で使うデータに他の変数も加味してみてはどうだろう?!と考えれますよね。
では、「その1」では4つのデータしか予測モデルに反映しませんでしがが、他で使えそうなデータも予測モデルに使って見ましょう!
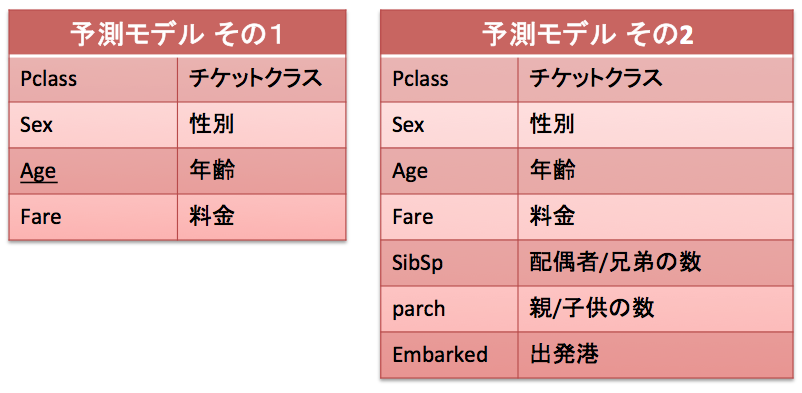
映画「タイタニック」でも家族や子供と一緒に船から脱出を試みるシーンがあったように記憶してますが、これは恐らく生存確率に影響をしそうですよね。また出発港も3つのカテゴリしかありませんが、生存確率に何かしらの影響はあるのでは?と睨んで追加をしてみましょう。
まずはtrainのデータセットから今回追加になった項目の値も追加して「features_two」に取り出しましょう。
また、予測モデルその2では、簡単ではありますが「過学習(Overfitting)」についても考えて見ましょう。その1で作成した決定木のモデルではmax_depthとmin_samples_slitのアーギュメントを指定しませんでしたが、その2のモデルではアーギュメントを設定してみましょう。
|
1 2 3 4 5 6 7 8 9 10 11 |
# 追加となった項目も含めて予測モデルその2で使う値を取り出す features_two = train[["Pclass","Age","Sex","Fare", "SibSp", "Parch", "Embarked"]].values # 決定木の作成とアーギュメントの設定 max_depth = 10 min_samples_split = 5 my_tree_two = tree.DecisionTreeClassifier(max_depth = max_depth, min_samples_split = min_samples_split, random_state = 1) my_tree_two = my_tree_two.fit(features_two, target) |
さて、モデルの作成もできましたので、実際に「my_tree_two」を使って予測をしてみましょう。
|
1 2 3 4 5 6 7 8 9 10 11 |
# tsetから「その2」で使う項目の値を取り出す test_features_2 = test[["Pclass", "Age", "Sex", "Fare", "SibSp", "Parch", "Embarked"]].values # 「その2」の決定木を使って予測をしてCSVへ書き出す my_prediction_tree_two = my_tree_two.predict(test_features_2) PassengerId = np.array(test["PassengerId"]).astype(int) my_solution_tree_two = pd.DataFrame(my_prediction_tree_two, PassengerId, columns = ["Survived"]) my_solution_tree_two.to_csv("my_tree_two.csv", index_label = ["PassengerId"]) |
上記のコードを正しく打ち込んでいれば、「my_tree_two.csv」として新しく作成した決定木による予測のCSVファイルが書き出されているはずです。
では、早速、Kaggleへ戻って結果をアップロードしてみましょう。
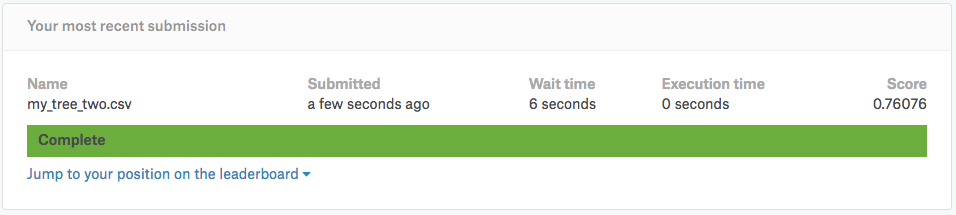
結果は・・スコア「0.76076」でした!つまり、正解確率が約76.0%とすこ〜しだけ改善されています。その1では正解率が約71.8%でしたので、訓練データを増やしたことにより約4%の改善ができました。
まとめ
今回の記事ではKaggle初心者編として、タイタニック号の乗客リストを使った生存予測を行ってみました。簡単な事前データ処理とScikit-learnの決定木を使うことで、思ったよりも簡単に機械学習に触れることが可能です。
英語ばかりで慣れないKaggleではありますが、機械学習を学ぶ人にとっては避けて通れないほど魅力が詰まっています。是非、これを機械にKaggleへの参加をしてみましょう。
codexaでは、機械学習初心者向けのチュートリアルや無料講座や有料チュートリアルも配信しています。Kaggleへ参加される前にPythonの機械学習系ライブラリの操作方法などを身につけてみましょう。
有料チュートリアル


初心者ですがすごく参考になりました!
ただ文字を数値に置換するところはwarningが出てしまうので
train[“Sex”] = train[“Sex”].map({“male” : 0, “female” : 1})
train[“Embarked”] = train[“Embarked”].map({“S” : 0, “C” : 1, “Q” : 2})
のようにしたほうがいいと思いました。
他にも、こっちの方が効率が悪くなりますがlocを使って
test.loc[test[“Sex”]==”male”,”Sex”] = 0
とするやり方もありますよね。
my_tree_one = tree.DecisionTreeClassifier()のところまではうまくいくのですが、my_tree_one.fit(features_one, target)のところからTypeErrorが出てしまいます。
どなたか解決方法わかる方いらっしゃるでしょうか?
my_tree_one = tree.DecisionTreeClassifier()のところまではうまくいったのですが、
my_tree_one = my_tree_one.fit(features_one, target)を実行しようとすると、以下のようなエラーが出てしまいます。どうすれば解決できるのでしょうか?
—————————————————————————
TypeError Traceback (most recent call last)
in
1 my_tree_one = tree.DecisionTreeClassifier()
—-> 2 my_tree_one = my_tree_one.fit(features_one, target)
~\anaconda3\lib\site-packages\sklearn\tree\_classes.py in fit(self, X, y, sample_weight, check_input, X_idx_sorted)
888 “””
889
–> 890 super().fit(
891 X, y,
892 sample_weight=sample_weight,
~\anaconda3\lib\site-packages\sklearn\tree\_classes.py in fit(self, X, y, sample_weight, check_input, X_idx_sorted)
154 check_X_params = dict(dtype=DTYPE, accept_sparse=”csc”)
155 check_y_params = dict(ensure_2d=False, dtype=None)
–> 156 X, y = self._validate_data(X, y,
157 validate_separately=(check_X_params,
158 check_y_params))
~\anaconda3\lib\site-packages\sklearn\base.py in _validate_data(self, X, y, reset, validate_separately, **check_params)
427 # 🙁
428 check_X_params, check_y_params = validate_separately
–> 429 X = check_array(X, **check_X_params)
430 y = check_array(y, **check_y_params)
431 else:
~\anaconda3\lib\site-packages\sklearn\utils\validation.py in inner_f(*args, **kwargs)
71 FutureWarning)
72 kwargs.update({k: arg for k, arg in zip(sig.parameters, args)})
—> 73 return f(**kwargs)
74 return inner_f
75
~\anaconda3\lib\site-packages\sklearn\utils\validation.py in check_array(array, accept_sparse, accept_large_sparse, dtype, order, copy, force_all_finite, ensure_2d, allow_nd, ensure_min_samples, ensure_min_features, estimator)
597 array = array.astype(dtype, casting=”unsafe”, copy=False)
598 else:
–> 599 array = np.asarray(array, order=order, dtype=dtype)
600 except ComplexWarning:
601 raise ValueError(“Complex data not supported\n”
~\anaconda3\lib\site-packages\numpy\core\_asarray.py in asarray(a, dtype, order)
83
84 “””
—> 85 return array(a, dtype, copy=False, order=order)
86
87
TypeError: float() argument must be a string or a number, not ‘method’
サンプルコマンドをそのままコピペで実行しましたが、微妙に正解確率が違ってしまいました。
# 「test」の説明変数を使って「my_tree_one」のモデルで予測
my_prediction = my_tree_one.predict(test_features)
ここでエラーが出るのですが、何がいけないのでしょか?
ブログ投稿から5年ほど経過していると思いますが、本サイト参考にスムーズに実行できました。
ありがとうございました。