何かを「集める」という作業は非常に大変です。特に画像などに関しては数枚程度であればすぐに集まりますが、数百枚、数千枚となってくると手作業ではかなり大変です。また、一般的に出回らないような画像であれば収集の制限はさらに厳しくなることが予想されます。
機械学習、特にディープラーニングによる画像認識では大量の画像データを必要とする場合が多いです。時にその量は数万枚や数十万枚(またはそれ以上)に登る場合もあります。有名なCelebAのデータセットには202,599枚もの有名人の顔画像が用意されています。しかし、全てのデータセットがこれほどの量を保持しているわけではありません。そのため、私たちは現状で用意できるデータセットからデータ数を増やす手段を考える必要があります。(参考:CelebA Dataset)
その手段の1つとして、本稿では、Data Augmentation(読み:データ・オーギュメンテーション、訳:データ拡張)について解説していきます。前半では「Data Augmentationの基礎知識」、中盤では「Data Augmentationの各変換の実装」、後半では実際のデータセットを用いて「ニューラルネットワークによる分類」を行います。Data Augmentationは機械学習を使用して画像認識を学びたいと考えている方にとってはとても重要な技術になりますので、しっかりとした基礎知識と実装スキルを身につけましょう。
この記事の目次
前提知識
Data Augmentationの内容は機械学習で画像を扱う上では一部分でしかありません。そのため本稿を読まれる際には、画像認識の大枠や用語などの基礎知識(ディープラーニングやCNNなど)があることが望ましいです。それらの基礎知識だけでも非常に解説が長くなってしまうため、本稿では詳細には記載しません。もし、これらの知識に不安がある方は以下の記事を先に読まれることをお勧めします。本稿でも以下の記事で扱われている内容を前提に解説を進めていきます。
Data Augmentationとは
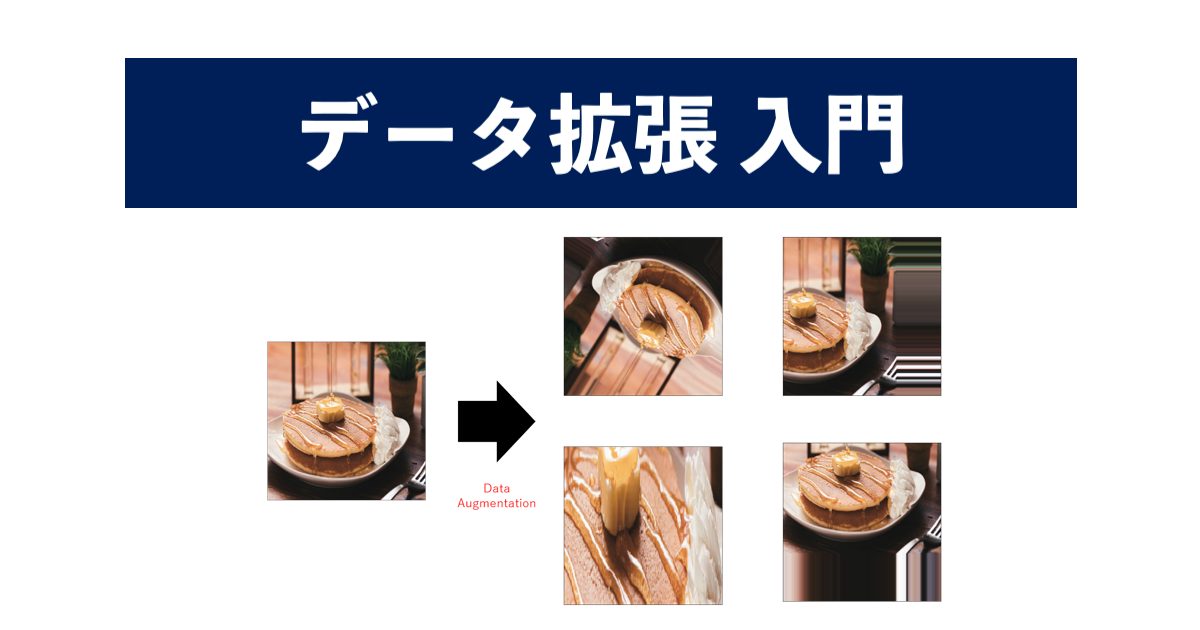
Data Augmentation(データ拡張)とは、学習用の画像データに対して「変換」を施すことでデータを水増しする手法です。この「変換」には様々な種類が存在します。その種類についてはこの後、実装を踏まえて解説します。まずはData Augmentationを適用した画像を確認してみましょう。それぞれの写真がどのように変換されているのかに注目してください。なお本稿で使用されている画像に関しては以下のサイトから引用しています。(参考:フリー写真素材ぱくたそ)

図1にはパンケーキが表示され、図2〜5では図1のパンケーキが少し変化した状態で表示されていることが分かると思います。図2では回転、図3では左移動、図4では拡大、図5では上移動と変化しています。このように1枚の画像から4枚の画像に変換され実質5枚の画像が存在しています。これがData Augmentationによる画像の水増しです。
本来、Data Augmentationには画像を「変換」する手法だけでなく、「生成」する手法も存在します。例としてはGAN(Generative Adversarial Networks)などの技術を利用したものです。しかし、これらの内容は高度な専門的知識が必要である上、本稿内に収めることが難しい内容なため、記載しません。今後、本稿でのData Augmentationは画像の「変換」を指します。皆様が学習を進めていく中で興味がでてきた方は是非調べて見てください。(参考:敵対的生成ネットワーク Wikipedia)
Data Augmentationの必要性
本節ではData Augmentationの必要性について解説していきます。可能な限り直感的な理解ができるよう、画像を用いて解説していきます。必要性については主に以下の点が挙げられます。
- データ数の増加
- 過学習への対策
データ数の増加
近年のニューラルネットワーク(特にCNN)による画像認識技術はとても進歩しています。同時に、開発されたモデルの中にはとても深い層をもつものもあります。そういったモデルの中には多くのパラメータを有するものもあり、学習のために大量のデータが必要とされる場合があります。しかし、データによっては必要な数を用意できない場合もあります。特に医療系などのプライバシーに関わるようなデータは比較的集めにくい現状があります。少ないデータ数でも学習を行えるようにするためにData Augmentationは必要なのです。実際に画像がどのように増えて見えるのかに関してはこのあとの「Data Augmentation一覧」で確認できます。
過学習への対策
もう一つは過学習への対策です。過学習に関する詳細は本稿では省きますが、簡単に述べると「学習用データに機械学習モデルが適合しすぎることにより、テストデータに対する適合率が下がる」ことを指します。私たちが画像認識のモデルを作成する根本的な目的は、学習したモデルを用いて、未知のデータを正しく分類・評価することです。そのため、どれだけ学習用データに対して高精度のモデルが完成したとしても、テストデータに対して精度が低ければ意味がありません。どのような例が考えられるのか、画像を使用しながら解説します。仮定する目的は「犬と猫を分類すること」とします。与えられる学習用データセットには図6、図7のような犬と猫の画像が存在しているとします。

上の画像は左が猫、右が犬の画像です。猫は左に、犬は右に体を向けています。もし、学習用データセット内の全ての犬猫が同じ体の向きだった場合、起こりうる問題として次のことが挙げられます。
- 左向きの犬を「猫」と予測する可能性がある
- 右向きの猫を「犬」と予測する可能性がある
これは学習したモデルが、犬と猫を体の向きで判断するように学習してしまった場合に起こりうる問題です。極端な例ではありますが、テスト時に逆向きの犬猫が与えられる可能性はあります。この問題に対して、Data Augmentationは比較的有効です。この問題の根本は「学習用データセット内の犬猫の向きが同じ」であることです。つまり、犬と猫が左右両方を向いている画像があれば解決する可能性が高くなります。そこで、学習用データセットにData Augmentationを適用し、犬猫の画像を反転させた画像を加えます。

図8と図9の犬と猫の画像は図6と図7を反転させたものです。これによりモデルは学習用データセット内の画像に加えて、反転した画像も学習に使用できます。これでテスト時の画像で左右どちらの犬猫の画像が与えられたとしても、正しく分類できる確率は比較的高くなります。この考えはデータセットの規模が大きい場合にも適用できます。数が多いことと、データの質が高いことは別です。データ数が多くても、今回の仮定のように学習用データに「偏った特徴」が含まれていることもあります。
ここまでData Augmentationの必要性について解説してきました。今回の例はかなり極端なものでしたが、大まかな概要は掴むことができたと思います。冒頭でも述べたように、機械学習で画像認識の分野を扱いたい方にとってData Augmentationはとても重要な技術です。しかし、日常的に使用していると「なぜ」行なっているかを見失う場合があります。しっかりと必要性を理解した上で実装するように心がけましょう。
Data Augmentationの注意点
本節ではData Augmentationを使用する際の注意点について解説していきます。前節ではData Augmentationの必要性について記載してきましたが、常に有効であるとは限りません。有効でないData Augmentationとしては以下の点が挙げられます。
- データセットに合わない変換
- 過学習
データセットに合わない変換
Data Augmentationは画像に対して様々な変換を施すことで、データを水増しします。しかし、考えなしで闇雲に変換すれば良いわけではありません。前節で述べたように、有効なData Augmentationを適用することは重要ですが、変換によっては逆にモデルの精度を下げる可能性もあります。次の画像にはいくつかのData Augmentationの適用例を示しています。画像を確認しながら適用されている変換が有効であるかを考えてみてくだい。

まずは図10〜図12の電車の画像を見てみます。ここでは電車の種類が何かを分類する機械学習モデルを作成すると仮定します。図11は電車がズームされており、図12は電車が回転されています。まず図11に関してですが、電車を撮影する際のズームのレベル感は撮影者に委ねられる場合が多いです。そのため、撮影者によっては引いた写真を撮る人もいれば、フレームいっぱいに撮影する方もいるかもしれません。そのため図11は比較的有効そうです。逆に図12は画像が回転され、電車が逆さまになっています。電車を逆さまに撮る方は少ないと考えられますし、事故でなければ電車が逆さまになる現場を目にすることはほとんどないと思われます。電車の種類を考えるのであれば、逆さまの写真はそれほど有効ではなさそうです。
次に、図13〜図15の数字の画像を見てみます。ここでは数字が0〜9の数字に分類する機械学習モデルを作成すると仮定します。図18は数字が少し回転しており、図19は数字が反対になっています。図14は少なめの回転ですので、撮影の状況によっては考慮できるレベルです。そのため有効と考えられます。逆に、図15は数字が反対になっていますが、4の数字をこの形で書くことはありません。数字の分類に対しては有効とは考えにくいです。
当然ですが、本当に有効か有効でないかは、実際にモデルで分類を行い、評価をしない限りは判断できません。しかし図12や図15など明らかに違和感のある画像に変換しない(または気づく)ことは重要です。有効でないData Augmentationはモデルの精度を著しく下げてしまう場合もあるので注意しましょう。
過学習
もう一つの注意点は過学習です。「Data Augmentationの必要性」ではData Augmentationは過学習を防ぐために有効であると記載しましたが、逆もあります。学習用データに「似た特徴」を与えてしまう可能性があることです。画像の変換によって増えた画像はある程度似た画像になります。そのため、モデルがそれらの画像に過剰に適合すると、過学習を引き起こす可能性があります。Data Augmentationは少ないデータ数でも学習を可能にするための手段として有効です。しかし、過学習を避けながら、複雑なモデルを使用する場合や高精度の評価を得たい場合には質のいいデータがある程度存在することが望ましいです。
ここまでData Augmentationの注意点について解説してきました。「Data Augmentationの必要性」と合わせて理解することができたでしょうか。実際、このような欠点に関する理解は様々なデータセットで練習し、実践を積むことが最も効果的です。本稿の後半でも実際のデータセットを用いますので、そちらも参考にしながら学習を進めてみてください。興味のある方はkaggleなどのデータ分析コンペティションなどのデータセットを使用してみるのも1つの手だと思います。(参考:kaggleとは?)
Data Augmentationのタイミング
本節ではData Augmentationが実際に適用されるタイミングについてお伝えします。今後Data Augmentationを実装していく際は、keras(本稿でも使用)やPyTorch(以下の記事を参考)を使うことが多くなるかと思います。その際に感じるのが、Data Augmentationがどのタイミングで行われているか分かりにくいということです。さらに、その部分が分からないまま学習を進めるとData Augmentationを間違えて理解してしまう可能性があります。少し難しい部分もありますので、図を用いながら可能な限り直感的に理解できるように解説していきます。(参考:PyTorch 入門!人気急上昇中のPyTorchで知っておくべき6つの基礎知識)
オフライン拡張
1つ目はオフライン拡張(Offline Augmentation)です。オフライン拡張はデータセットに存在する画像自体にData Augmentationを適用し、単純に画像の枚数を増やす手法です。Data Augmentationを初めて聞いた方が真っ先に湧くイメージだと思います。図16はオフライン拡張の内容を示しています。
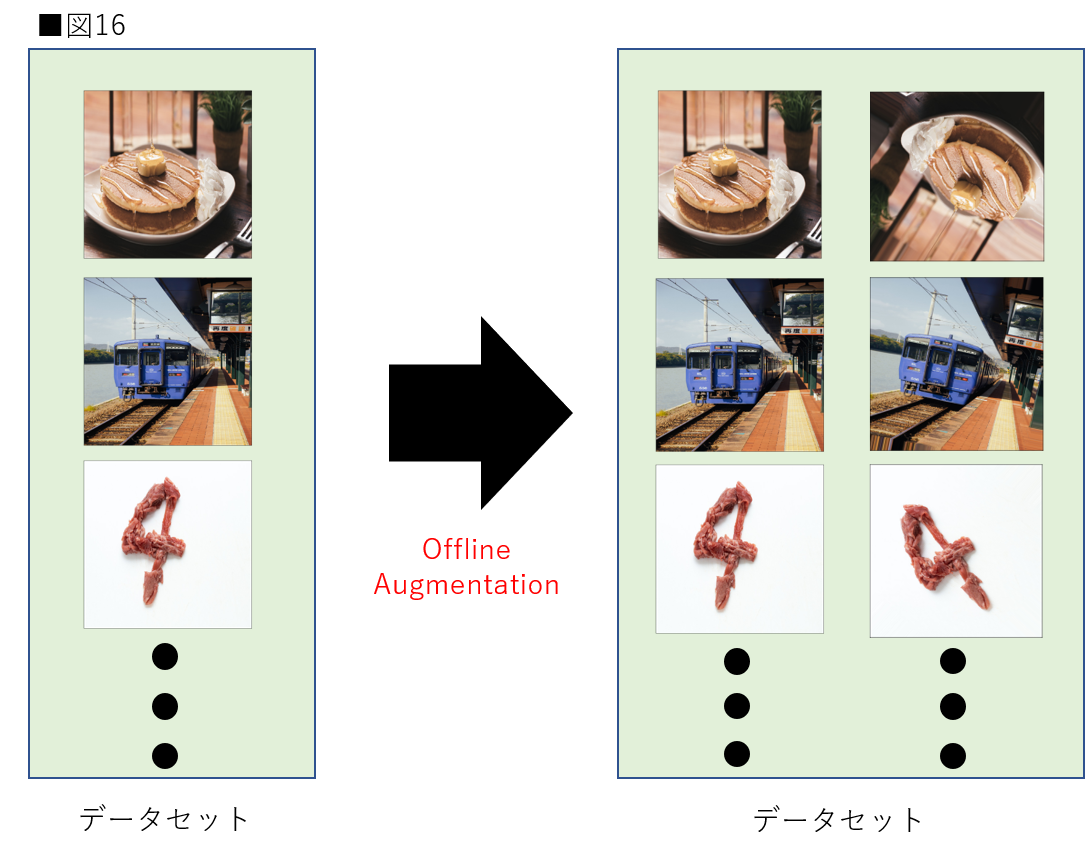
図16はデータセット内の各画像に対して回転の変換を加えた場合です。各画像1枚ずつの変換画像が出来上がるため、データセットは2倍になっています。これがオフライン拡張です。比較的小さなデータセットの場合に適応される場合があります。筆者自身はこの手法を扱った経験はありませんが、データ分析コンペティションなどで用意されたデータセットの中で既にオフライン拡張が行われていた経験はあります。
オフライン拡張には注意点があります。それはデータセット自体の容量が単純に増加するという点です。大量のデータを扱うディープラーニングでは、学習に必要なデータセットの容量はとても大きくなります。特に画像などのデータセットを扱う場合にはテーブルデータなどに比べて容量も大きくなりやすいです。オフライン拡張を行うということは画像データの増加に比例して容量も増加します。そのため、大容量のデータを保存できる領域が必須になります。保存領域には限りがあるのが一般的ですので、オフライン拡張でデータ数を増やす際には注意しなければなりません。
オンライン拡張
2つ目はオンライン拡張(Online Augmentation)です。記事によってはオンザフライ拡張(On-the-fly Augmentation)とも呼ばれていますが本稿ではオンライン拡張という言葉を使用します。オンライン拡張はオフライン拡張に比べて比較的一般的です。図17はオンライン拡張の手順を示しています。図と解説を照らしわあせながら理解しましょう。
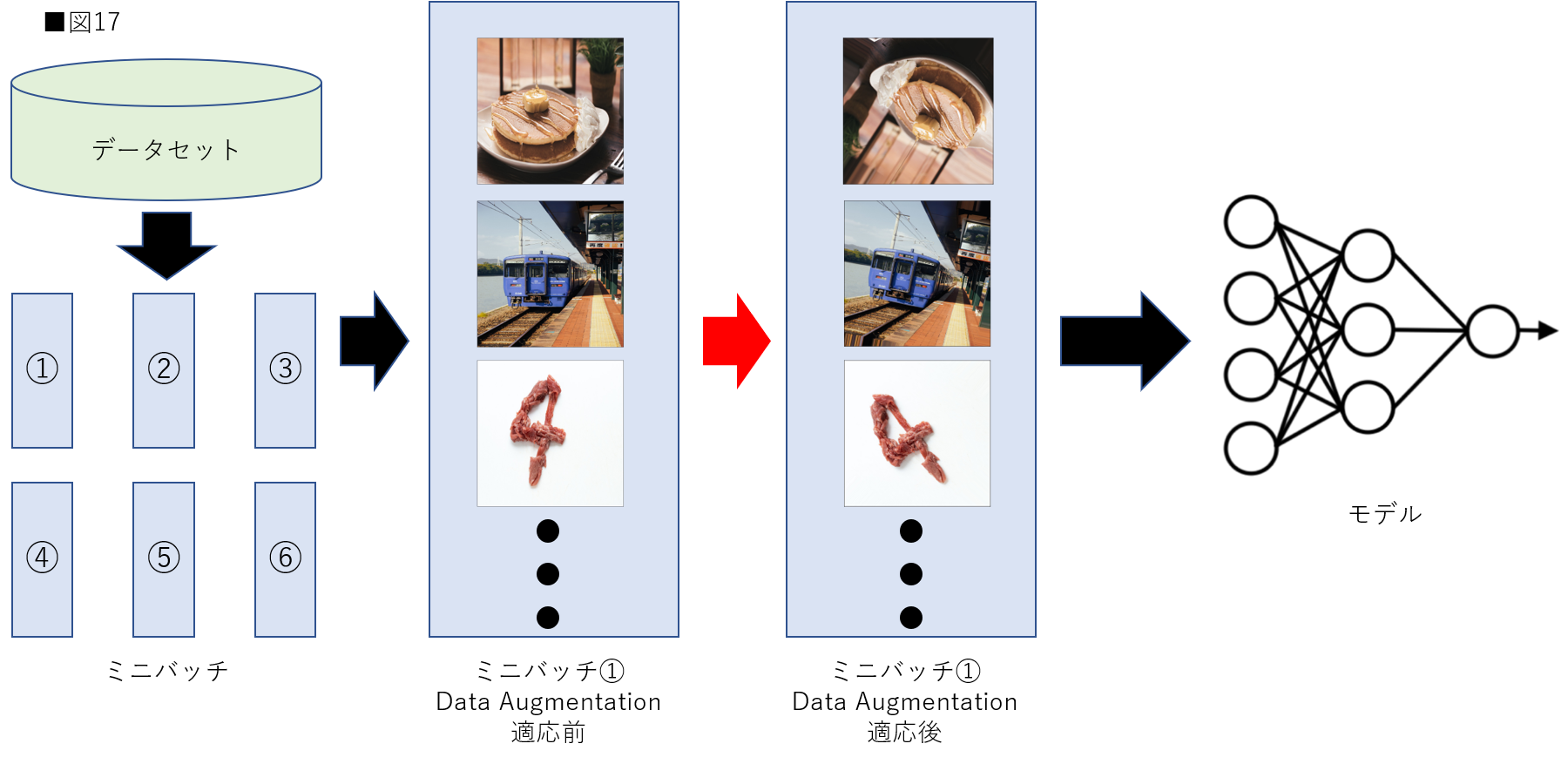
オンライン拡張を理解するためにはミニバッチ学習という言葉を理解する必要があります。簡単に記載すると、データセットを複数に分割したものを使用して学習を行うことです。一般的にディープラーニングではモデルを学習させる際にデータセットを複数のミニバッチに分割し、ミニバッチごとに学習を行います。オンライン拡張は、モデルに入力するミニバッチに対してData Augmentationを適用します。
オンライン拡張ではデータセット自体の容量は増えません。オフライン拡張ではData Augmentationをランダムに設定してもデータ数は指定した数にしかなりませんが、オンライン拡張であれば学習毎にランダムな画像が生成されます。エポックを複数にして学習を行えば、同じミニバッチでも違う画像を使用することができます。これにより、モデルからするとより多くの画像を学習に使用することができることになります。
ここまで、Data Augmentationについて解説してきました。深い内容ですので、一度読んだだけで完全に理解するのは難しいかもしれません。そういった方は本稿を一通り読んでいただき、実装まで確認した上でもう一度本節を読み直していただくことをお勧めします。
Data Augmentation一覧
本節ではData Augmentationにおける画像変換の一覧を解説とともに実装します。様々な変換がありますが、1つ1つ順番に見ていくことで実際のデータセットに適応させる際もイメージがつきやすくなります。特にパラメータが存在する変換は値によって変換の度合いが決まります。Data Augmentationを使いこなすためにも、確実に理解しておきましょう。
実装はkerasと呼ばれるニューラルネットワークのライブラリを用います。Google Colabを用いて実装していきます。ライブラリをそのままインポートすれば同じように実装可能です。是非、ご自身でも実装してみてください。Google Colabを使用したことがない方は下記の記事を参考にしてください。(参考:Google Colabの知っておくべき使い方 – Google Colaboratoryのメリット・デメリットや基本操作のまとめ)
最初の設定しとして、Google Colabの上部タブから「ランタイム」の「ランタイムの変更」を選択してください。そこから、「ハードウェアアクセラレータ」を「GPU」に変更してください。本節では使用しませんが、次節で使用するため、現段階で変更しておきます。変更ができたら、まずは必要なライブラリをインポートします。
|
1 2 3 4 5 6 7 8 9 |
#[IN]: #必要なライブラリのインポート import numpy as np import matplotlib.pyplot as plt from keras.preprocessing import image from keras.preprocessing.image import ImageDataGenerator,array_to_img,img_to_array |
画像の準備
まずはGoogle Colab上に画像を読み込みます。本稿と同じ画像(パンケーキの画像)を使用したい方は以下のサイトから利用規約に同意した上で画像をダウンロードしてください。アップロードが完了したら「パスをコピー」を選択してコード上に貼り付けてください。画像に関してはkerasのload_imgメソッドを用いて640×640にリサイズさせたものを読み込みます。(参考:フリー写真素材ぱくたそ(利用規約))
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
#[IN]: #アップロードされた画像を読み込み img = image.load_img("/content/ogasuta458A8104_TP_V4.jpg", target_size=(640, 640)) #画像をnumpy配列に変換する img = np.array(img) #表示画像のサイズを設定 plt.figure(figsize = (10, 10)) #軸を表示しない plt.xticks(color = "None") plt.yticks(color = "None") plt.tick_params(bottom = False, left = False) #表示 plt.imshow(img) |

ImageDataGeneratorクラスについて
各変換に必要なImageDataGeneratorクラスについて解説します。ImageDataGeneratorはkerasが持つData Augmentationを行うためのクラスです。本稿ではこちらを用いてData Augmentationを実装していきます。ImageDataGeneratorクラスには様々な画像の変換がまとめて実装できるようになっています。以下のコードはImageDataGeneratorクラスのデフォルト引数になります。この中の引数の内、比較的よく使うものを中心に解説していきます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
#[IN]: #○がついている引数を本稿では扱う ImageDataGenerator( featurewise_center = False,#○ samplewise_center = False,#○ featurewise_std_normalization = False,#○ samplewise_std_normalization = False,#○ zca_whitening = False, zca_epsilon = 1e-06, rotation_range = 0,#○ width_shift_range = 0.0,#○ height_shift_range = 0.0,#○ brightness_range = None,#○ shear_range = 0.0,#○ zoom_range = 0.0,#○ channel_shift_range = 0.0,#○ fill_mode = "nearest",#○ cval = 0.0,#○ horizontal_flip = False,#○ vertical_flip = False,#○ rescale = None,#○ preprocessing_function = None,#○ data_format = None, validation_split = 0.0, dtype = None, ) |
|
1 2 3 4 5 |
#[OUT]: <keras.preprocessing.image.ImageDataGenerator at 0x7f5a4e97f810> |
ImageDataGeneratorのメソッド
ImageDataGeneratorクラスはメソッドを使用してデータを受け取り、Data Augmentationを適用します。適用するときのメソッドは与えられるデータ形式によります。データに合わせて利用してください。本稿では画像はnumpyの配列として与えられているので、flowメソッドを使用します。これらのメソッドにも引数があります。また、他のメソッドも存在しますが、本稿の目的とは少しずれてしまうため、主要なメッソド以外は記載しません。ImageDataGeneratorクラスの他のメソッドに興味がある方はkerasの公式ドキュメントを参考にしてみてください。(参考:keras公式:ImageDataGenerator)
- flowメソッド→numpyのデータを受け取り、データのバッチを返す(本稿で使用)
- flow_from_dataframeメソッド→pandasのデータフレームを受け取り、データのバッチを返す
- flow_from_directryメソッド→ディレクトリ内のパスを受け取り、データのバッチを返す
画像表示の準備
ここから、表示したパンケーキの画像に対して、様々な変換を行っていきます。実際に画像処理を行う前に、画像表示用の関数を定義しておきます。本稿では各変換に対して6枚の変換後の画像が表示されるようにします。これは変換がランダムで行われるため、1枚では変換していない画像が表示されてしまう可能性があるためです。flowメソッドのseed値は固定していますので、表示される6枚の画像は何度同じセルを実行しても同様のものになります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
#[IN]: #画像表示用の関数を定義 def show(datagen, img): #表示サイズを設定 plt.figure(figsize = (10, 5)) #画像をbatch_sizeの数ずつdataに入れる #本稿は画像が一枚のため同じ画像がdataに入り続けることになる for i, data in enumerate(datagen.flow(img, batch_size = 1, seed = 0)): #表示のためnumpy配列からimgに変換する show_img = array_to_img(data[0], scale = False) #2×3の画像表示の枠を設定+枠の指定 plt.subplot(2, 3, i+1) #軸を表示しない plt.xticks(color = "None") plt.yticks(color = "None") plt.tick_params(bottom = False, left = False) #画像を表示 plt.imshow(show_img) #6回目で繰り返しを強制的に終了 if i == 5: return |
次にパンケーキの画像配列(img)に次元を1つ追加します。これはこの後使用するImageDataGeneratorクラスの入力が4次元である必要があるためです。現在imgの配列は640×640×3(縦×横×チャンネル数)になっています。これを1×640×640×3にします。この「1」は「データセット内の何番目の画像ですか?」という情報です。今回のデータセットには画像が1枚しかないと仮定するので1を追加します。
|
1 2 3 4 5 6 7 8 9 10 |
#[IN]: #パンケーキの画像配列の形 print(img.shape) #配列に次元を追加 img_cake=img[np.newaxis, :, :, :] #次元追加後の配列の形 print(img_cake.shape) |
|
1 2 3 4 5 6 |
#[OUT]: (640, 640, 3) (1, 640, 640, 3) |
画像の回転(rotation_range)
最初の変換は、画像の回転です。その名の通り画像を回転させます。まず、確認していただきたいのは画像の出力が同じではないことです。「オンライン拡張」でも少し触れましたが、同じバッチでも違う変換が行われています。そのため、1枚の画像が6枚になっているように見えると思います。これらがモデルが学習している画像ということです。これは他の変換でも同様ですので、よく理解しておいてください。画像の回転の引数はrotation_rangeで設定されます。
- int型(180)の場合→指定された角度(-180度〜180度)の範囲でランダムに回転を行います。
|
1 2 3 4 5 6 7 8 |
#[IN]: #-180度〜+180度の間でランダムに回転するImageDataGeneratorを作成 rotation_datagen = ImageDataGenerator(rotation_range = 180) #画像を表示 show(rotation_datagen, img_cake) |

左右平行移動(width_shift_range)
次に、画像の左右平行移動です。引数はwidth_shift_rangeで設定します。width_shift_rangeの引数はいくつか種類がありますので、実装時に迷わないようにしっかりと理解しておきましょう。
- int型(50)の場合→指定されたピクセル(-50〜+50)の範囲で左右にランダムに動かします。
- list型([50,100])の場合→指定されたピクセル(-100,-50,+50,+100)の内、左右にランダムに動かします。
- float型(0.5)の場合→指定された値×画像の横幅(-320〜+320)の範囲で左右にランダムに動かします。
|
1 2 3 4 5 6 7 |
#[IN]: #-320〜+320の間でランダムに左右平行移動するImageDataGeneratorを作成 width_datagen = ImageDataGenerator(width_shift_range = 0.5) show(width_datagen, img_cake) |

上の条件に従って左右平行移動が適用されます。左右平行移動は値によっては画像が枠内からが飛び出す場合があります。その場合、枠内の画像は補間の必要があります。補間の設定に関しては後述しますので、現段階では補間が行われているということを知っておいてください。
上下平行移動(height_shift_range)
次に、画像の左右平行移動です。引数はheight_shift_rangeで設定します。height_shift_rangeの引数はwidth_shift_rangeと同様にいくつかの種類があります。設定の仕方はほぼ同様です。
- int型(50)の場合→指定されたピクセル(-50〜+50)の範囲で上下にランダムに動かします。
- list型([50,100])の場合→指定されたピクセル(-100,-50,+50,+100)の内、上下にランダムに動かします。
- float型(0.5)の場合→指定された値×画像の縦幅(-320〜+320)の範囲で上下にランダムに動かします。
|
1 2 3 4 5 6 7 |
#[IN]: #-320〜+320の間でランダムに上下平行移動するImageDataGeneratorを作成 height_datagen = ImageDataGenerator(height_shift_range = 0.5) show(height_datagen, img_cake) |

拡大と縮小(zoom_range)
次に、画像の拡大と縮小です。引数はzoom_rangeで設定します。zoom_rangeの値だけでは画像がどの程度拡大又は縮小されているか理解しにくいため、実際に複数の値を試してみることをお勧めします。
- float型(0.5)の場合→「1-指定された値」(0.5)〜「1+指定された値」(1.5)の範囲で拡大又は縮小します。
- list型([0.5,1.5])の場合→指定された値(0.5〜1.5)の範囲で拡大又は縮小します。
|
1 2 3 4 5 6 7 |
#[IN]: #0.5〜1.5の間でランダムに拡大又は縮小するImageDataGeneratorを作成 zoom_datagen = ImageDataGenerator(zoom_range = [0.5, 1.5]) show(zoom_datagen, img_cake) |

画像のせん断(shear_range)
次に、画像のせん断です。せん断とは、四角形の画像を平行四辺形に変形する処理です。引数はshear_rangeで設定します。せん断についてより詳しく知りたい方は以下のサイトも参考にしてみてください。引数のshare_rangeにはシアー角度を設定します。(参考:せん断写像 Wikipedia)
- float型(30)の場合→指定されたシアー角度(30度)でせん断します。
|
1 2 3 4 5 6 7 |
#[IN]: #30度の範囲でランダムにせん断するImageDataGeneratorを作成 shear_datagen = ImageDataGenerator(shear_range = 30) show(shear_datagen, img_cake) |

画像の補間方法(fill_mode)
ここまで、画像の回転、平行移動、拡大と縮小、せん断まで解説してきました。画像の回転の際に少し触れましたが、入力画像が枠内に合わない場合の補間方法にはいくつかの種類が存在します。全部で4種類存在しますので、把握しておきましょう。引数はfill_modeで設定します。
- 「nearest」→一番近くの画素値で補間(デフォルト)
- 「constant」→定数で補間
- 「reflect」→反転して補間
- 「wrap」→繰り返しで補間
1.nearest
ImageDataGeneratorにおいてデフォルトで設定されている画像の補間になります。「aaaaaaa|abcd|ddddddd」のように一番近い画素値で外側を補完する方法です。筆者も何か理由がない限りは基本デフォルトであるnearestの補間を使用しています。
|
1 2 3 4 5 6 7 |
#[IN]: #nearestで補間するImageDataGeneratorを作成 nearest_datagen = ImageDataGenerator(width_shift_range = 0.5, fill_mode = "nearest") show(nearest_datagen, img_cake) |

2.constant
constantは定数を指定して補間する方法です。「fill_mode = constant」で実装でき、「xxxxxxx|abcd|xxxxxxx」のように画像にかかわらず特定の値で補間できます。今回の実装例では0に設定することで黒にしています。補間する際の値の指定は「cval」引数を追加することで実現できます。補間を黒に設定することで、テストの際など、画像がどの程度傾いているかなど非常にわかりやすく表示することができます。
|
1 2 3 4 5 6 7 |
#[IN]: #constantで補間するImageDataGeneratorを作成 constant_datagen = ImageDataGenerator(width_shift_range = 0.5, fill_mode = "constant", cval = 0) show(constant_datagen, img_cake) |

3.reflect
reflectは画像に対して反転した画素で補間する方法です。「fill_mode = reflect」で実装でき、「abcddcba|abcd|dcbaabcd」のように反転された画像が映ります。筆者はあまり使用した経験はありませんが、条件によっては精度向上が見込める補間方法です。
|
1 2 3 4 5 6 7 |
#[IN]: #reflctで補間するImageDataGeneratorを作成 reflect_datagen = ImageDataGenerator(width_shift_range = 0.5, fill_mode = "reflect") show(reflect_datagen, img_cake) |

4.wrap
wrapは画像に対して繰り返すような画素で補間する方法です。「fill_mode = wrap」で実装でき、「abcdabcd|abcd|abcdabcd」のように反転された画像が映ります。こちらも筆者はあまり使用した経験はありませんが、状況によっては必要になる場面もありますので理解は必要です。
|
1 2 3 4 5 6 7 |
#[IN]: #wrapで補間するImageDataGeneratorを作成 wrap_datagen = ImageDataGenerator(width_shift_range = 0.5, fill_mode = "wrap") show(wrap_datagen, img_cake) |

左右反転(horizontal_flip)
次に、画像の左右反転です。引数はhorizontal_flipで設定します。左右反転は比較的よく使用される変換です。初学者の方でも理解しやすく、筆者も画像処理を行う際に、最初に試すことが多い変換です。実装自体も簡単なので、確実に押さえておきましょう。
- bool型(True)の場合→ランダムに画像を左右反転します。
|
1 2 3 4 5 6 7 |
#[IN]: #ランダムに画像を左右反転するImageDataGeneratorを作成 horizontal_datagen = ImageDataGenerator(horizontal_flip = True) show(horizontal_datagen, img_cake) |

上下反転(vertical_flip)
次に、画像の上下反転です。引数はhorizontal_flipで設定します。画像の向きや性質によっては使うことの多い変換です。使い方は左右反転と全く同じですのですが、上下画像の反転は左右反転に比べて汎用性が低い場合が多ので注意が必要です。
- bool型(True)の場合→ランダムに画像を上下反転します。
|
1 2 3 4 5 6 7 |
#[IN]: #ランダムに画像を上下反転するImageDataGeneratorを作成 vertical_datagen = ImageDataGenerator(vertical_flip = True) show(vertical_datagen, img_cake) |

明るさの調整(Brightness_range)
次に、明るさの調整です。引数はBrightness_rangeで設定します。画像の明るさを変更できるため、画像自体が暗すぎる場合や明るすぎる場合に便利です。後述するチャンネルシフトと非常に似ていますが、扱いに関してはこちらの方が比較的簡単です。
- Tuple型((0.3,0.8))→指定した値の範囲(0.3〜0.8)でランダムに明るさを調整(1.0以下は暗く、1.0以上は明るくなる)
- list型([0.3,0.8])→指定した値の範囲(0.3〜0.8)でランダムに明るさを調整(1.0以下は暗く、1.0以上は明るくなる)
|
1 2 3 4 5 6 7 |
#[IN]: #画像の明るさを0.3〜0.8の間で調整(暗くする) brightness_datagen = ImageDataGenerator(brightness_range = [0.3, 0.8]) show(brightness_datagen, img_cake) |

チャンネルシフト(channel_shift_range)
次はチャンネルシフトです。チャンネルシフトとは画像を構成するRGBのチャンネルの値を変更することです。先ほどの「明るさの調整(Brightness_range)」との違いは、シフト値を指定できる点です。細かくシフト値を指定されたい方にとってはこちらの方が便利です。
|
1 2 3 4 5 6 |
#[IN]: print("画像破裂の形は"+str(img_cake.shape)) print("1ブロックのチャンネルの値は"+str(img_cake[0][0][0])) |
|
1 2 3 4 5 6 |
#[OUT]: 画像破裂の形は(1, 640, 640, 3) 1ブロックのチャンネルの値は[223 163 126] |
上記に表示したのはパンケーキの画像の配列形状と1つのチャンネルの値です。チャンネルの値にはRGBの各値が入っています。チャンネルシフトはこの画素値を変更する変換です。引数はchannel_shift_rangeで設定します。RGBは256階調でプログラム上0〜255で処理されます。その際、画素値の範囲を超えるような値を指定したとしても、画素値は0または255として変換されます。
- float型(100.0)の場合→指定した値(-100〜+100)値でチャンネルの範囲でチャンネルをシフトします。
|
1 2 3 4 5 6 7 |
#[IN]: #-100〜100の間でランダムにチャンネルシフトするImageDataGeneratorを作成 channel_datagen = ImageDataGenerator(channel_shift_range = 100) show(channel_datagen, img_cake) |

画素値のリスケーリング(rescale)
次は画素値のリスケーリングです。引数はrescaleで設定します。この値を設定すると他の変換を適応する前に指定した値を乗算します。画素値は通常0〜255の範囲で表されているため、それを0〜1の範囲に収めたい場合などは1/255などを乗算します。画像を元の画素値に戻したい時は、この時乗算した値の逆数を乗算することで元に戻ります。
- 1./255の場合→他の変換を行う前に各画素値を1/255にします。
|
1 2 3 4 5 6 7 |
#[IN]: #各画素値を0〜1に収めるImageDataGeneratorを作成 rescale_datagen = ImageDataGenerator(rescale = 1./255) show(rescale_datagen, img_cake) |
表示される画像はほぼ黒になりましたが、それは画素値が0〜1に収まっているからです。画素値の最大値と最小値を確認すると0〜1に収まっていることが確認できます。
|
1 2 3 4 5 6 7 8 9 10 |
#[IN]: #リスケーリング後の最大の画素値と最小の画素値の確認 for i, data in enumerate(rescale_datagen.flow(img_cake, batch_size = 1)): print(np.max(data[0])) print(np.min(data[0])) if i == 0: break |
|
1 2 3 4 5 6 |
#[OUT]: 1.0 0.015686275 |
データセット全体の平均を0にする(featurewise_center)
次はfeaturewise_centerです。featurewise_centerは与えられたデータセット全体の入力の画素値平均を0にします。画素値のままでは負の値をとることはありませんが、featurewise_centerを使用すると負の値も持った上で画像を表現することができます。これは、ニューラルネットワークなどに対する前処理などに使用できます。画像の平均値を確認するとほぼ0になっていることが確認できます。(平均が0ちょうどにならないのは計算時に生まれる誤差のためです)
- bool型(True)の場合→データセット全体の画素値平均を0にします。
|
1 2 3 4 5 6 7 8 9 10 11 |
#[IN]: #データセット全体の平均を0にするImageDataGeneratorクラスを作成 featurewise_datagen = ImageDataGenerator(featurewise_center = True) featurewise_datagen.fit(img_cake, seed = 0) for i, data in enumerate(featurewise_datagen.flow(img_cake, batch_size = 1)): print(np.mean(data[0])) if i == 0: break |
|
1 2 3 4 5 |
#[OUT]: -0.011399994 |
各サンプルの平均を0にする(samplewise_center)
次はsamplewise_centerです。samplewise_centerは与えられた各サンプルの入力の画素値平均を0にします。用途としてはfeaturewise_centerとほぼ同じですが、他の条件やモデルに合わせて良い方を使用します。こちらも平均値がほぼ0になっていることが確認できます。
- bool型(True)の場合→画像ごとの画素値平均を0にします。
|
1 2 3 4 5 6 7 8 9 10 11 |
#[IN]: #各サンプル毎の平均を0にするImageDataGeneratorクラスを作成 samplewise_datagen = ImageDataGenerator(samplewise_center = True) featurewise_datagen.fit(img_cake, seed = 0) for i, data in enumerate(samplewise_datagen.flow(img_cake, batch_size = 1)): print(np.mean(data[0])) if i == 0: break |
|
1 2 3 4 5 |
#[OUT]: -2.4617513e-05 |
データセット全体の標準偏差を1にする(featurewise_std_normalization)
次はfeaturewise_std_normalizationです。featurewise_std_normalizationは与えられたデータセット全体の入力の標準偏差を1にします。この時、featurewise_centerはTrueにしなければなりません。出力を確認すると大体ですが、平均がほぼ0、標準偏差がほぼ1になっていることが確認できます。
- bool型(True)の場合→データセット全体の標準偏差を1にする
|
1 2 3 4 5 6 7 8 9 10 11 12 |
#[IN]: #データセット全体の平均を0、標準偏差を1にするImageDataGeneratorクラスを作成 featurewise_std_datagen = ImageDataGenerator(featurewise_center = True, featurewise_std_normalization = True) featurewise_std_datagen.fit(img_cake,seed = 0) for i, data in enumerate(featurewise_std_datagen.flow(img_cake, batch_size = 1)): print(np.mean(data[0])) print(np.std(data[0])) if i == 0: break |
|
1 2 3 4 5 6 |
#[OUT]: -0.00016482393 1.0000116 |
各サンプルの標準偏差を1にする(samplewise_std_normalization)
次はsamplewise_std_normalizationです。samplewise_std_normalizationは与えられた各サンプルの入力の標準偏差を1にします。用途としてはfeaturewise_std_normalizationとほぼ同じですが、他の条件やモデルに合わせて良い方を使用します。出力を確認すると大体ですが、平均が0、標準偏差が1になっていることが確認できます。
- bool型(True)の場合→各サンプルの標準偏差を1にする
|
1 2 3 4 5 6 7 8 9 10 11 12 |
#[IN]: #各サンプル毎の平均を0、標準偏差を1にするImageDataGeneratorクラスを作成 samplewise_std_datagen = ImageDataGenerator(samplewise_center = True, samplewise_std_normalization = True) samplewise_std_datagen.fit(img_cake,seed = 0) for i, data in enumerate(samplewise_std_datagen.flow(img_cake, batch_size=1)): print(np.mean(data[0])) print(np.std(data[0])) if i == 0: break |
|
1 2 3 4 5 6 |
#[OUT]: -7.589658e-08 1.0000001 |
関数を使用した前処理(preprocessing_function)
preprocessing_functionは他の各変換が行われる前に適用される関数を指定できる引数です。ImageDataGeneratorだけでもData Augmentationの種類としては十分ですが、それ以外に自作で変換関数などをImageDataGenerator内で適用させることができます。下記の例では直感的に理解できるよう各画素値に127の値を入れています。RGBが全て127であれば灰色の画像が表示されます。自分で画像の変換関数を作りたい方は使ってみてください。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
#[IN]: #前処理関数preを用意 def pre(p): p = 127 return p #画像を全て灰色にするImageDataGeneratorクラスを作成 preprocessing_datagen = ImageDataGenerator(preprocessing_function = pre) show(preprocessing_datagen, img_cake) |

複数の変換の適用
ここまで、各変換を1つずつ適用させてきました。実際のデータセットに対しては複数の変換を適用させることになるので、そちらも確認しておきたいと思います。今回はわかりやすいよう、回転と左右平行移動と拡大縮小の3つの変換を組み合わせたいと思います。下記の画像からどんな画像が生成されているか確認してください。適用した変換は以下になります。
- 「-30度から30度」の範囲でランダムに回転
- 「640×-0.3〜640×0.3」の範囲でランダムに水平平行移動
- 「0.7〜1.3」の範囲でランダムにズーム
|
1 2 3 4 5 6 7 |
#[IN]: #複数の変換を適用するImageDataGeneratorクラスを作成 double_datagen = ImageDataGenerator(rotation_range = 30, width_shift_range = 0.3, zoom_range = 0.3) show(double_datagen, img_cake) |

3種類の変換を組み合わせると6枚の画像は全て違う画像となりました。このように複数の変換を組み合わせれば、それだけ画像のバリエーションも増やすことができます。
ここまでImageDataGeneratorクラスによるData Augmentationは一通り解説が終わりました。様々な画像の変換を行ってきましたが、最も重要なのは「目的のために質の良いData Augmentationを行うこと」です。常にテストデータを想定しながら、どのように画像を増やしたら精度が高まるかを考えることが必要です。
ニューラルネットワークによるCIFAR-10の分類
ここからは実際のデータセットに対してData Augmentationを実装していきます。特に、Data Augmentationを行う場合と行わない場合について比較していきます。実装コードに関してはここから実行しても問題ありません。しかし、ランタイムについては「GPU」が使用されているかどうか確認してください。前節で切り替えている方はそのままで問題ありません。本節は以下の流れで進行します。
- データセットの読み込みと表示
- データの前処理
- モデル構築
- 学習1(Data Augmentationなし)
- 評価1
- 学習2(Data Augmentationあり)
- 評価2
上記の流れの中では、「3.データの前処理」にData Augmentationのコードを記載するのが一般的です。しかし、それではData Augmentationの比較をしにくくなってしまうため、本稿では「5.学習1(Data Augmentationなし)」「7.学習2(Data Augmentationあり)」にそれぞれ必要コードを記載しています。
1.必要なライブラリのインポート
まずは必要なライブラリをインポートします。ライブラリの数が非常に多く感じるかもしれませんが、どれも必須なものばかりです。kerasでニューラルネットを構築する際には、大体これくらいのライブラリは必要になりますので、慣れておきましょう。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
#[IN]: #必要なライブラリのインポート import numpy as np import matplotlib.pyplot as plt %matplotlib inline from keras.models import Model from keras.utils import np_utils from keras.datasets import cifar10 from keras.preprocessing.image import ImageDataGenerator from keras.layers import Input from keras.layers.pooling import MaxPool2D from keras.layers.convolutional import Conv2D from keras.layers.core import Dense, Flatten import tensorflow as tf tf.random.set_seed(0) |
2.データセットの読み込みと表示
次にデータセットをロードします。今回使用するデータはCIFAR-10です。CIFAR10は10種類の物体のカラー写真からなるデータセットです。全体で学習用データが50000枚、テスト用データが10000枚です。10種類のラベルの詳細に関しては以下に記載します。CIFAR-10よりもラベル数が多いCIFAR-100も存在します。興味のある方は以下のサイトから調べてみてください。それではkerasのload_dataメソッドを用いてCIFAR-10をロードします。(参考:THE CIFAR-10/CIFAR-100)
CIFAR-10のラベルリスト
- 「0」→飛行機(airplane)
- 「1」→自動車(automobile)
- 「2」→鳥(bird)
- 「3」→猫(cat)
- 「4」→鹿(deer)
- 「5」→犬(dog)
- 「6」→カエル(flog)
- 「7」→馬(horse)
- 「8」→船(ship)
- 「9」→トラック(truck)
|
1 2 3 4 5 6 |
#[IN]: #cifar10をダウンロード (x_train, y_train),(x_test, y_test) = cifar10.load_data() |
|
1 2 3 4 5 6 7 |
#[OUT]: Downloading data from https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz 170500096/170498071 [==============================] - 11s 0us/step 170508288/170498071 [==============================] - 11s 0us/step |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
#[IN]: #ラベルの設定 labels = np.array([ 'airplane', #飛行機 'automobile',#バイク 'bird', #鳥 'cat', #猫 'deer', #鹿 'dog', #犬 'frog', #カエル 'horse', #馬 'ship', #船 'truck' #トラック ]) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
#[IN]: #画像の表示のための関数 def image_show(x, y, labels): plt.figure(figsize = (13, 10)) for i in range(30): plt.subplot(5, 6, i+1) #軸を表示しない plt.xticks(color = "None") plt.yticks(color = "None") plt.tick_params(bottom = False, left = False) #タイトルをラベルの名前で表示 plt.title(labels[y[i][0]]) #表示 plt.imshow(x[i]) return #画像を表示 image_show(x_train, y_train, labels) |

ぱっと見で判断できるものから、一見しただけではわかりにくいものまで様々です。しかし、データセット内にどういう画像が含まれているかは確認できたと思います。このように画像の可視化を行うことはとても重要です。本稿では30枚程度の表示しか行いませんが、例えば画像のラベルごとに表示を行ったり、ラベルの割合を調べたりすることも大切です。この画像は後ほど、Data Augmentationを考える際にも使用します。
3.データの前処理
ラベルはバイナリクラスに変更します。こちらでも述べられていますが、この処理はyの値を10個の数値の配列に変換しています。簡単な図を以下に記載しましたのでイメージをつかんでください。
- y = 5 = [0,0,0,0,1,0,0,0,0,0]
- y = 0 = [1,0,0,0,0,0,0,0,0,0]
|
1 2 3 4 5 6 7 8 |
#[IN]: #ラベルをバイナリクラスにする categorical_y_train = np_utils.to_categorical(y_train, 10) categorical_y_test = np_utils.to_categorical(y_test, 10) print(categorical_y_train[0]) |
|
1 2 3 4 5 |
#[OUT]: [0. 0. 0. 0. 0. 0. 1. 0. 0. 0.] |
4.モデル構築
ここからモデル構築に移ります。今回のモデルは畳み込み(Conv)層が4つ、プーリング(Pooling)層が3つ、全結合(Dense)層が2つです。畳み込み層のカーネルサイズを3×3、画像サイズが変わらないよう(”same”)に設定し、活性化関数にはReLU関数を用いています。またプーリング層にはMaxPoolingを使用しています。全結合層は最終的に出力が10で活性化関数をsoftmaxにしています。
以下の内容は本稿で記載すると収まらないため、深く解説しません。しかし、ニューラルネットワークを構築する上では必須となる内容ですので、ご自身で補うことをお勧めします。ここでは、一旦学習の進み具合にのみ注目してみます。
- 損失関数(loss function)
- 最適化(optimizer)
- 確率的最急降下法(sgt)
- 評価関数(metrics)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
#[IN]: #モデルを構築 inp=Input(shape = (32, 32, 3)) x = Conv2D(64, (3, 3), padding = 'same', activation = "relu", use_bias = True)(inp) x = MaxPool2D(pool_size = (2, 2))(x) x = Conv2D(128, (3, 3), padding = 'same', activation = "relu", use_bias = True)(x) x = MaxPool2D(pool_size = (2, 2))(x) x = Conv2D(256, (3, 3), padding = 'same', activation = "relu", use_bias = True)(x) x = MaxPool2D(pool_size=(2,2))(x) x = Conv2D(512, (3, 3), padding = 'same', activation = "relu", use_bias = True)(x) x = Flatten()(x) x = Dense(512, activation = 'relu', use_bias = True)(x) out = Dense(10, activation = 'softmax', use_bias = True)(x) |
|
1 2 3 4 5 6 7 |
#[IN]: #Data Augmentationを行わない用 normal_model = Model(inputs = inp, outputs = out) normal_model.compile(optimizer = 'adam', loss = 'categorical_crossentropy', metrics = ['accuracy']) |
|
1 2 3 4 5 6 7 |
#[IN]: #Data Augmentationを行う用 augmentation_model = Model(inputs = inp, outputs = out) augmentation_model.compile(optimizer = 'adam',loss = 'categorical_crossentropy', metrics = ['accuracy']) |
5.学習1(Data Augmentationなし)
モデルの構築が完了しましたので、Data Augmentationがない場合の学習を行いたいと思います。Data Augmentationは行いませんが、ニューラルネットワークを使用するため、画像のピクセルを0〜1の間に収めます。そのため、ImageDataGeneratorクラスのスケーリングだけは適用します。テストデータも同様にスケーリングのみを適用します。その後、flowメソッドを使用してデータのバッチを生成します。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
#[IN]: #学習用のImageDataGeneratorクラスの作成 normal_train_datagen = ImageDataGenerator(rescale = 1./255) #学習用のバッチの生成 normal_train_generator = normal_train_datagen.flow(x_train, categorical_y_train, batch_size = 32, seed = 0) #テスト用のImageDataGeneratorクラスの作成 test_datagen = ImageDataGenerator(rescale = 1./255) #テスト用のバッチの生成 test_generator = test_datagen.flow(x_test, categorical_y_test, batch_size = 32, seed=0) |
学習時の条件ですが、バッチサイズを32、エポック数を20 にしています。これらは「7.学習2(Data Augmentationあり)」でも同様の値を使用します。これらの値については決められた値というのは存在しません。経験則やデータセットと相談しながら探っていくことになります。
本稿では、GPU上の乱数に関してはシード値を固定していません。そのため、下記出力と若干異なる出力が表示されると思いますが、基本的には問題ありません。GPUの再現性に興味がある方は別途調べていただくようお願いいたします。
|
1 2 3 4 5 6 |
#[IN]: #学習 normal_result = normal_model.fit(normal_train_generator,steps_per_epoch=len(x_train) / 32, epochs=20) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 |
#[OUT]: Epoch 1/20 1562/1562 [==============================] - 69s 17ms/step - loss: 1.6774 - accuracy: 0.3698 Epoch 2/20 1562/1562 [==============================] - 26s 16ms/step - loss: 0.9568 - accuracy: 0.6592 Epoch 3/20 1562/1562 [==============================] - 26s 16ms/step - loss: 0.7133 - accuracy: 0.7499 Epoch 4/20 1562/1562 [==============================] - 26s 16ms/step - loss: 0.5719 - accuracy: 0.7970 Epoch 5/20 1562/1562 [==============================] - 26s 16ms/step - loss: 0.4447 - accuracy: 0.8434 Epoch 6/20 1562/1562 [==============================] - 26s 16ms/step - loss: 0.3296 - accuracy: 0.8836 Epoch 7/20 1562/1562 [==============================] - 26s 16ms/step - loss: 0.2413 - accuracy: 0.9157 Epoch 8/20 1562/1562 [==============================] - 26s 16ms/step - loss: 0.1898 - accuracy: 0.9334 Epoch 9/20 1562/1562 [==============================] - 26s 16ms/step - loss: 0.1557 - accuracy: 0.9459 Epoch 10/20 1562/1562 [==============================] - 26s 16ms/step - loss: 0.1303 - accuracy: 0.9546 Epoch 11/20 1562/1562 [==============================] - 26s 17ms/step - loss: 0.1130 - accuracy: 0.9618 Epoch 12/20 1562/1562 [==============================] - 26s 17ms/step - loss: 0.1118 - accuracy: 0.9620 Epoch 13/20 1562/1562 [==============================] - 26s 17ms/step - loss: 0.1030 - accuracy: 0.9658 Epoch 14/20 1562/1562 [==============================] - 26s 17ms/step - loss: 0.1103 - accuracy: 0.9630 Epoch 15/20 1562/1562 [==============================] - 26s 17ms/step - loss: 0.0949 - accuracy: 0.9687 Epoch 16/20 1562/1562 [==============================] - 26s 17ms/step - loss: 0.0966 - accuracy: 0.9694 Epoch 17/20 1562/1562 [==============================] - 26s 17ms/step - loss: 0.0983 - accuracy: 0.9678 Epoch 18/20 1562/1562 [==============================] - 26s 17ms/step - loss: 0.0977 - accuracy: 0.9692 Epoch 19/20 1562/1562 [==============================] - 26s 17ms/step - loss: 0.0877 - accuracy: 0.9727 Epoch 20/20 1562/1562 [==============================] - 26s 17ms/step - loss: 0.1009 - accuracy: 0.9677 |
|
1 2 3 4 5 6 7 8 9 10 11 12 |
#[IN]: #accuracyのプロット plt.plot(range(1, 21), normal_result.history['accuracy'], label = "train") #軸ラベル名 plt.xlabel('Epochs') plt.ylabel('Accuracy') #表示 plt.legend() plt.show() |
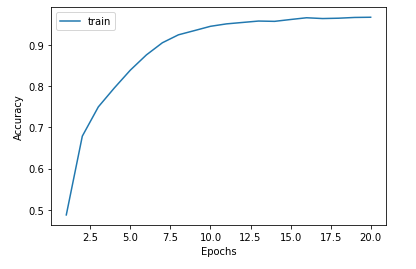
6.評価1
学習データのaccuracyは0.9を上回るほど良い結果を残しています。これは、かなり正確に分類できていると言えます。これと同等の精度がテストデータでも得られれば問題ありません。それではテストデータで評価を行います。評価にはevaluateメソッドを使用し、先ほど作成したtest_generatorを引数に渡してあげます。学習用データとのaccuracyとの差に注目してください。
|
1 2 3 4 5 6 |
#[IN]: #テスト用データを使って評価 normal_evaluate = normal_model.evaluate(test_generator) |
|
1 2 3 4 5 |
#[OUT]: 313/313 [==============================] - 3s 8ms/step - loss: 1.7661 - accuracy: 0.7427 |
学習用データの方のaccuracyは0.9を上回っていたのに対し、テストデータのaccuracyは0.74程度です。これは今回のモデルが過学習を起こしていることを意味します。モデルが学習用データに過度に適合したことにより、テストデータに対する評価が下がってしまっています。つまりData Augmentationを行わないことによって発生しうる事象の一例です。そのため、次はData Augmentationを用いて、この結果を少しでも改善させられるようにしていきます。
7.学習2(Data Augmentationあり)
まずはどのようなData Augmentationが有効かどうか考えて見たいと思います。先ほど表示した30枚の画像と同様の画像を表示して考えます。そして表示した画像から考えられる以下の点を仮説として挙げます。
|
1 2 3 4 5 6 |
#[IN]: #画像の表示 image_show(x_train, y_train, labels) |
- 撮影時の向きはバラバラなので少し回転を加えた方が良さそうである。
- 動物の体の向きは左右バラバラなので左右反転をした方が良さそうである。
- フレーム内の動物の位置はズレているので少し、上下左右にシフトした方が良さそうである。
- 動物の大きさはバラバラなので少しズームをした方が良さそうである。
- 撮影時の明るさがバラバラなので少し色を変えた方が良さそうである。
以上の仮説をData Augmentationとして適用させてみます。「5.学習1」と同様にImageDataGeneratorクラスで変換を定義し、flowメソッドを使用してデータのバッチを生成します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
#[IN]: #学習用のImageDataGeneratorクラスの作成 augmentation_train_datagen = ImageDataGenerator( #回転 rotation_range = 10, #左右反転 horizontal_flip = True, #上下平行移動 height_shift_range = 0.2, #左右平行移動 width_shift_range = 0.2, #ランダムにズーム zoom_range = 0.2, #チャンネルシフト channel_shift_range = 0.2, #スケーリング rescale = 1./255 ) #学習用のバッチの生成 augmentation_train_generator = augmentation_train_datagen.flow(x_train, categorical_y_train, batch_size=32, seed=0) |
学習時の条件も「5.学習1」と同様で、バッチサイズを32、エポック数を20 にしています。
|
1 2 3 4 5 6 |
#[IN]: #学習 augmentation_result = augmentation_model.fit(augmentation_train_generator, steps_per_epoch = len(x_train) / 32, epochs = 20) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 |
#[OUT]: Epoch 1/20 1562/1562 [==============================] - 59s 37ms/step - loss: 1.2971 - accuracy: 0.5997 Epoch 2/20 1562/1562 [==============================] - 58s 37ms/step - loss: 0.9787 - accuracy: 0.6654 Epoch 3/20 1562/1562 [==============================] - 58s 37ms/step - loss: 0.9140 - accuracy: 0.6839 Epoch 4/20 1562/1562 [==============================] - 58s 37ms/step - loss: 0.8811 - accuracy: 0.6970 Epoch 5/20 1562/1562 [==============================] - 58s 37ms/step - loss: 0.8456 - accuracy: 0.7096 Epoch 6/20 1562/1562 [==============================] - 58s 37ms/step - loss: 0.8162 - accuracy: 0.7179 Epoch 7/20 1562/1562 [==============================] - 58s 37ms/step - loss: 0.7918 - accuracy: 0.7260 Epoch 8/20 1562/1562 [==============================] - 58s 37ms/step - loss: 0.7816 - accuracy: 0.7327 Epoch 9/20 1562/1562 [==============================] - 58s 37ms/step - loss: 0.7658 - accuracy: 0.7359 Epoch 10/20 1562/1562 [==============================] - 58s 37ms/step - loss: 0.7422 - accuracy: 0.7423 Epoch 11/20 1562/1562 [==============================] - 58s 37ms/step - loss: 0.7354 - accuracy: 0.7444 Epoch 12/20 1562/1562 [==============================] - 58s 37ms/step - loss: 0.7127 - accuracy: 0.7542 Epoch 13/20 1562/1562 [==============================] - 58s 37ms/step - loss: 0.7111 - accuracy: 0.7512 Epoch 14/20 1562/1562 [==============================] - 58s 37ms/step - loss: 0.6979 - accuracy: 0.7580 Epoch 15/20 1562/1562 [==============================] - 58s 37ms/step - loss: 0.7035 - accuracy: 0.7549 Epoch 16/20 1562/1562 [==============================] - 57s 37ms/step - loss: 0.6813 - accuracy: 0.7645 Epoch 17/20 1562/1562 [==============================] - 57s 36ms/step - loss: 0.6806 - accuracy: 0.7657 Epoch 18/20 1562/1562 [==============================] - 57s 37ms/step - loss: 0.6598 - accuracy: 0.7710 Epoch 19/20 1562/1562 [==============================] - 57s 36ms/step - loss: 0.6572 - accuracy: 0.7722 Epoch 20/20 1562/1562 [==============================] - 57s 36ms/step - loss: 0.6645 - accuracy: 0.7701 |
学習が完了しました。accuracyの推移を見るためにグラフでプロットを行います。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
#[IN]: #accuracyのプロット plt.plot(range(1, 21), augmentation_result.history['accuracy'], label = "train") #軸ラベル名 plt.xlabel('Epochs') plt.ylabel('Accuracy') #表示 plt.legend() plt.show() |
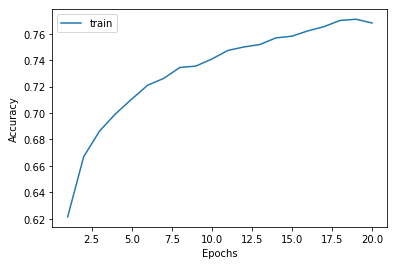
8.評価2
学習データのaccuracyは0.78程度です。これは、先ほどに比べると良い評価を得られていません。この評価を踏まえた上で、テストデータで評価を行います。評価にはevaluateメソッドを使用し、先ほど作成したaugmentation_test_generatorを引数に渡してあげます。学習用データとのaccuracyとの差に注目してください。
|
1 2 3 4 5 6 |
#[IN]: #テスト用データを使って評価 augmentation_evaluate = augmentation_model.evaluate(test_generator) |
|
1 2 3 4 5 |
#[OUT]: 313/313 [==============================] - 3s 8ms/step - loss: 0.6431 - accuracy: 0.7857 |
テストデータのaccuracyも0.78程度になっています。つまり結果的にData Augmentationを行なった方が、行わない場合に比べて評価の高いモデルを作成できたことになります。この要因の一つにData Augmentationによって過学習を抑制できたことが挙げられます。Data Augmentationによって学習用データの画像が水増しされたことにより、モデルは本来用意されている画像数よりも多くの画像を学習に使用しました。それにより、学習用データの難易度も上がりましたが、テストデータに対する適合率も上がりました。結果、テストデータのaccuracyはData Augmentationを行わない場合に比べて上がったと考えられます。
accuracyが上がったことで今回適用したData Augmentationの手法が有効であったと考えられます。このように画像を観察した上で特徴を探りData Augmentationを適用することはどのデータセットでも重要です。本稿を読まれている方々には、是非本稿のコードを利用して様々なData Augmentationの手法を試していただきたいと思います。
まとめ
本稿ではData Augmentationの必要性から実装まで解説しました。画像データは容量も大きいため扱いが難しいですが、視覚的に確認できるため、機械学習の中でも非常に楽しい分野だと思います。本稿が少しでも機械学習を勉強したいと思われている方々の参考になれば幸いです。
CodexaのコースやAIマガジンでは画像認識の内容を含んだものが他にも存在します。興味がある方はそちらも確認してみてください。皆様の受講をお待ちしております。
機械学習 チュートリアル はじめての画像認識
【AIマガジン】OpenCV 入門:画像処理・画像認識・機械学習の実装を徹底解説(全実装コード公開)

