何かを「正しい」と判断するとき、読者の皆様は何を根拠としますか。例えば、経験を元にする場合、一度だけの経験では偶然の可能性も考えられます。これが複数の経験からの判断であれば、少しは信憑性が増すと思います。一度の結果では信憑性が薄くとも、多くの結果を得られればある程度の精度で判断できる材料となります。
機械学習も同様です。様々な特徴量を扱う機械学習では、予測モデル(以下:モデル)の評価が本当に「正しい」のかを判断することは難しい問題です。特に、過学習などの問題は機械学習の技術が発展している近年でも残り続けています。
本稿では、機械学習を扱う上で重要な交差検証(クロスバリデーション )について解説します。前半ではデータ分割の基本と、交差検証の定義を解説をします。後半では実際のデータセットを用いて交差検証の実装を行います。交差検証は様々な場面で紹介されていますが、実際に学ぶと詰まるポイントが多いようにも感じます。そのため、本稿では初学者の方でも理解できるように、できる限り直感的に解説していきます。
この記事の目次
データ分割
交差検証の内容に入る前に、データ分割(Data Split)について解説します。この概念は交差検証を理解する上で必要なものです。もし、データ分割について少しでも不安のある方は必ず確認するようにしてください。本稿の主題はあくまで交差検証ですので、データ分割の解説は基礎的な部分のみを扱います。
訓練・検証・テストの定義
訓練データ(train data)、検証データ(validation data)、テストデータ(test data)の定義について解説します。本稿では基本的に以下の定義を使用します。しかし、解説の中で用途が変化する場合があります。その際は都度解説しています。読者の皆様は一旦以下の定義を確認しておいてください。
- 訓練データ:モデルの学習に使用されるデータです。学習データとも呼ばれることもあります。
- 検証データ(データセットが1つの場合):モデルのハイパーパラメータの調整に使用するデータです。
- 検証データ(コンペティションの場合):手元でモデルの評価を確認するためのデータです。
- テストデータ:訓練データを用いて構築されたモデルの評価に使用されます。コンペティションで提出(サブミット)を行うデータです。
ハイパーパラメータ(英語:Hyperparameter)とは機械学習アルゴリズムの挙動を設定するパラメータをさします。ハイパーパラメータの基本的な内容に関しては本稿で扱うと長くなってしまうため省略しています。過去にAIマガジンでハイパーパラメータに関する記事が存在します。本稿でのハイパーパラメータもこの記事をベースとしています。これらの知識に関して不安のある方は以下の記事を読まれることをお勧めします。(参考:ハイパーパラメータとは?チューニングの手法を徹底解)
訓練・テストデータの役割
機械学習は与えられたデータセットからモデルを作成します。次に、モデルが未知のデータに対してどの程度の精度を持つかを評価します。そのため、与えられたデータセットを訓練データとテストデータに分割する必要があります。図1はデータ分割を示しています。

図1のようにデータ分割を行うことで、モデルの評価を行うことができます。当然ですが、使用された訓練データはテストデータとして扱うことはできません。モデルは訓練データを用いて学習していますので、同じデータに対する評価を行いえば精度は必然的に高くなるからです。
検証データの役割
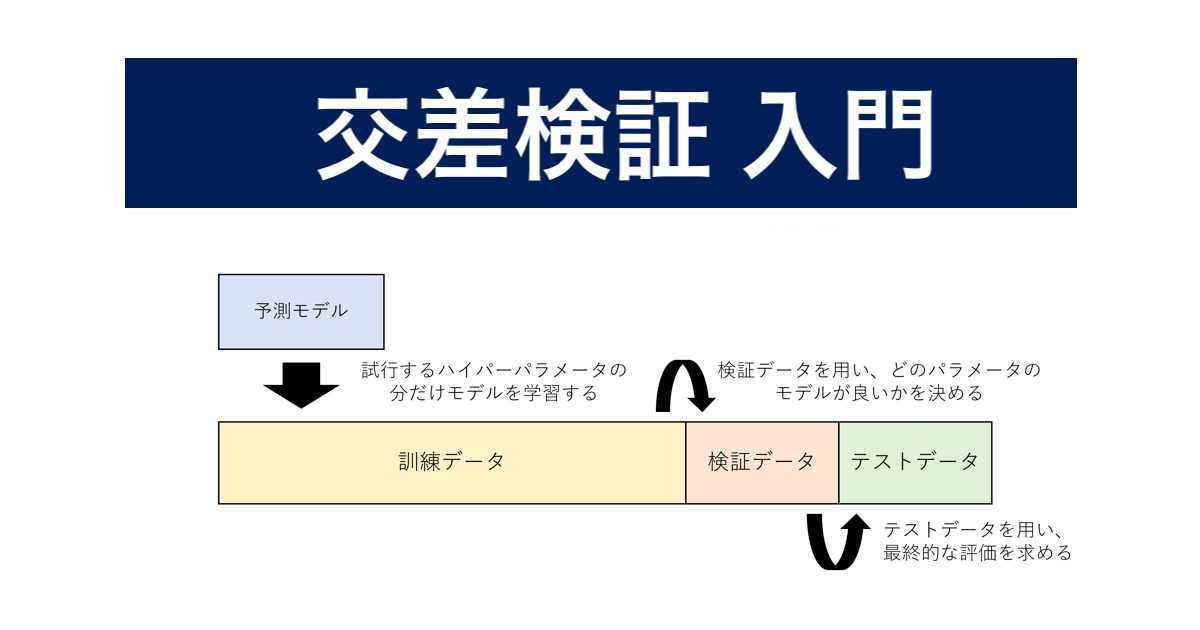
定義でも述べた通り検証データはハイパーパラメータの調整に使用されます。サポートベクターマシン(以下:SVM)やランダムフォレスト(Random Forest)のような、モデル自体の重みの他にハイパーパラメータを持つモデルは、訓練データだけでは最適化することができません。その時に登場するのが検証データです。図2は検証データも使用する場合のデータ分割を示しています。

図2ではデータセットが3分割されています。まず、訓練データで各パラメータに対するモデルの学習を行います。次に、検証データで各パラメータで学習したモデルの評価を行い、最も適切なパラメータを持つモデルを選択します。最後に、選択されたモデルを用いて、テストデータに対する評価を行います。図3にはハイパーパラメータの調整の流れが示されています。
よくある疑問として、検証データとテストデータは同一ではダメなのかというものがあります。結論からするとダメです。ハイパーパラメータは検証データに対するモデルの評価によって決定されます。よって、最終的に決定されたハイパーパラメータは検証データのみに適合された可能性が存在します。そのため、最終的な評価はテストデータを利用して行うことが求められます。
本稿ではグリッドサーチ(Grid Search)と呼ばれるハイパーパラメータの探索法を基準としています。ハイパーパラメータの探索方法にはいくつかの手法が存在します。先ほど紹介したこちらの記事に解説されています。確認してみてください。
コンペティションでの注意点
データ分割を理解する上でkaggleなどのデータ分析コンペティション(以下:コンペティション)との違いに注意してください。定義自体が曖昧なため、完璧に理解するのは難しいかもしれません。しかし、本稿を読み進める上でも注意してください。まず、データセットの提供には主に2つの形式があります。
- 全てラベルが存在する状態で与えられる場合(研究など)
- ラベルが存在するデータと存在しないデータが別々に与えられる場合(コンペティションなど)
まず、研究などではデータセット全てにラベルがある状態で提供される場合が多いです。そこからデータを分割し、機械学習モデルの学習から評価までを行います。対してコンペティションなどでは、データがあらかじめ分割された状態で提供される場合が多いです。例としてはtrain.csvで学習した予測モデルを用いてtest.csvの予測値をサブミットするなどが挙げられます。このとき、test.csvの方にはラベルはありません。サブミット時に初めて評価がわかります。図4は両者の違いを示しています。
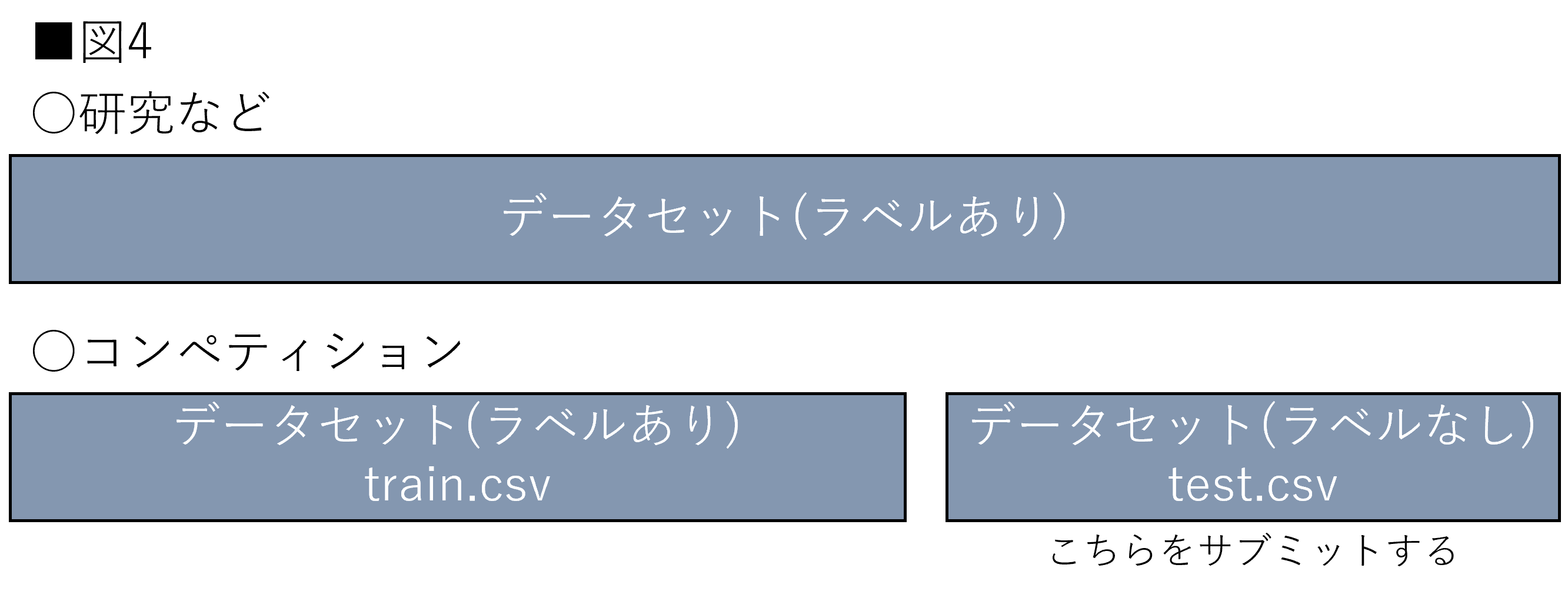
コンペティションの場合、検証・テストデータの区別が曖昧になります。筆者の肌感では、test.csvがテストデータと呼ばれることが多いように思います。そのため、本稿ではtest.csvなどはテストデータとし、train.csvで分割されたデータに関しては、訓練データと検証データとしています。本稿での解説が他の記事と異なる可能性があります。本稿を他の記事と比較される際は言葉の定義に違いがないかをよく確認するようにしてください。
交差検証(クロスバリデーション )
それでは交差検証(Cross-Validation)について解説していきます。交差検証とはデータの解析と評価を交差させることで、より正確な推定値を求める手法です。交差検証の定義はこれだけなのですが、実際の使われ方にはいくつかの種類が存在します。しかし、大きな違いではないので一度理解できれば対応できると思います。
モデルの汎化性能を評価する交差検証
こちらが筆者の知る限り最も一般的な交差検証です。前節ではモデルを評価するためにデータ分割を行うと解説しました。しかし、2分割での評価を1度行っただけでは、そのテストデータが偶然予測しやすかった可能性が存在します。そこで、訓練データとテストデータを交差させ、それぞれの評価の平均を取得することでより正しい推定値を獲得します。この交差検証は主に研究などの1つのデータセットで学習から評価までを行わなければならない場合に用いられます。図5は5分割の交差検証を示しています。
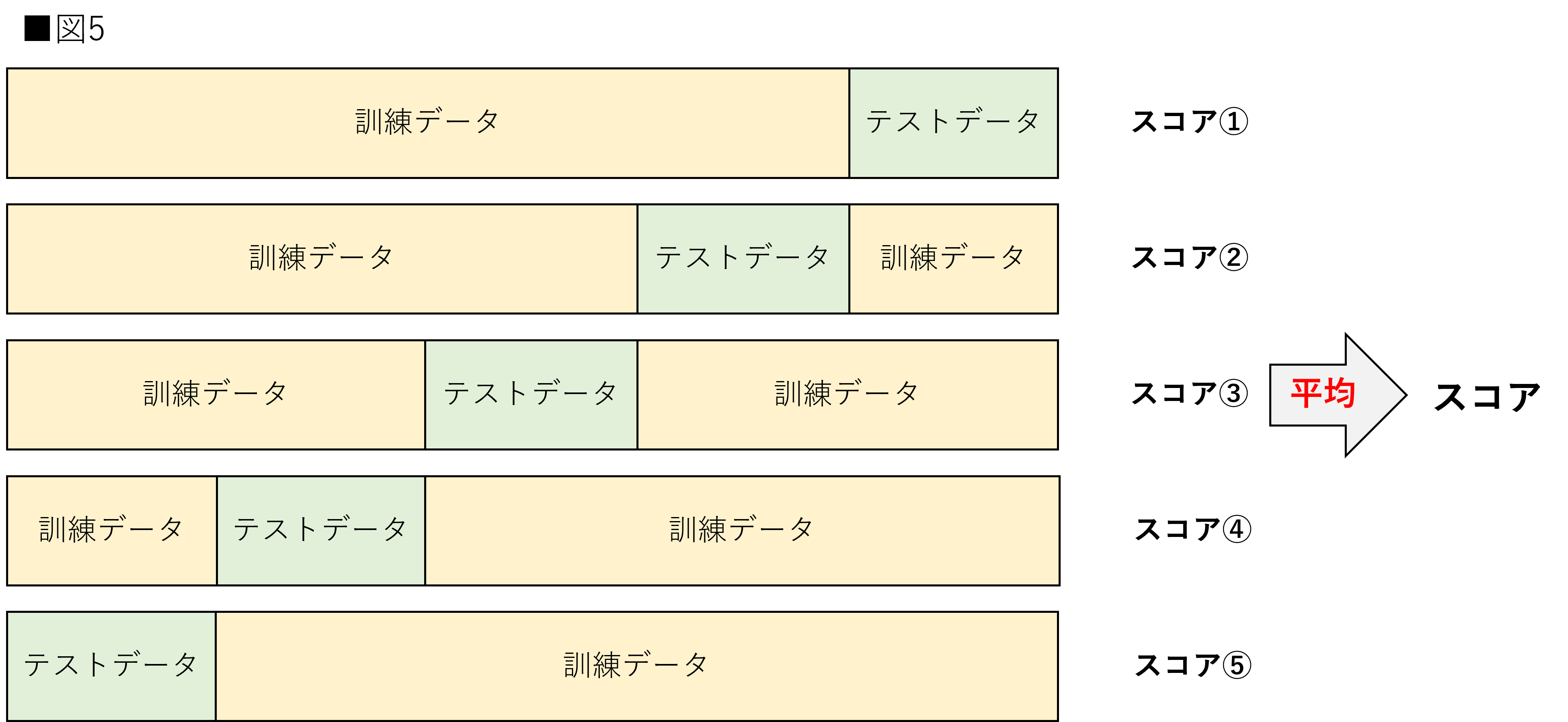
全てのデータが一度は訓練・テストデータ両方に使われていることがわかると思います。これにより、テストデータが偶然に予測しやすいなどの状態を避けることができます。注意点としては各fold毎にモデルは作り直す必要があることです。各foldの訓練データの中には、他のfoldのテストデータの情報が含まれています。1つのモデルを使用した場合、2fold目以降はテストデータを知っている状態で学習を行うことになります。それでは交差検証の意味がなくなりますので注意してください。
ハイパーパラメータチューニングのための交差検証
次にハイパーパラメータチューニングのための交差検証です。ハイパーパラメータの調整には検証データを用います。そのため、1つの検証データだけでは、最適な値か判断できない場合があります。そのため、交差検証を用いて一番評価の良いハイパーパラメータに調整します。
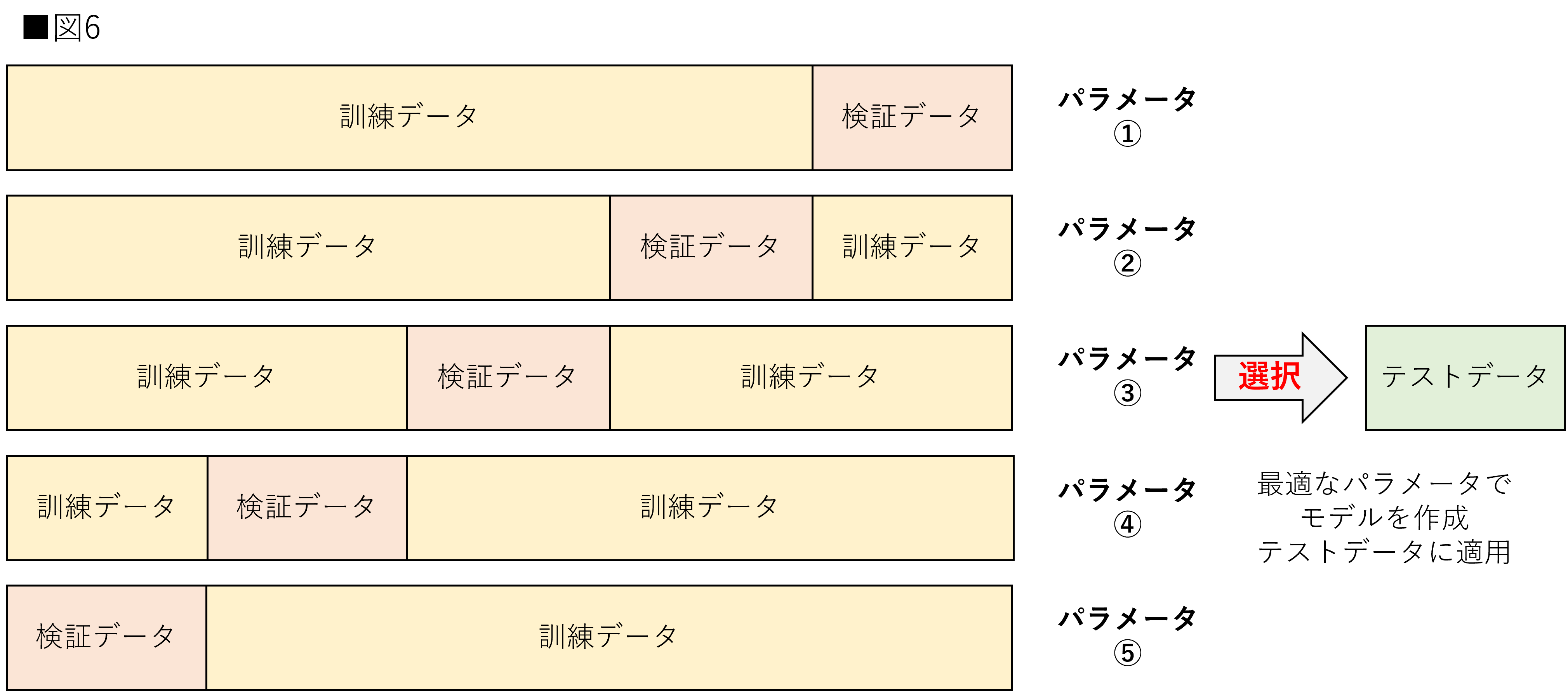
図6は図5と違う点が存在します。まずはテスト交差検証とは別にテストデータが存在する点です。この理由は図3の時と同様です。今回の交差検証は各foldの検証データに対して、最も良い評価であるハイパーパラメータを探索しています。つまり、検証データに対する評価の平均では、実際よりも高く見積もられる可能性があります。そのため、テストデータが別で用意することが前提になります。
コンペティションで行われる交差検証
最後にコンペティションで用いられる交差検証についてです。あくまで一例ですので、全ての分析者がこの方法を用いるわけではありません。コンペティションの内容によっても変化します。各コンペティションでの最適な交差検証は、ディスカッションなどを参考にしながら進めるようにしてください。
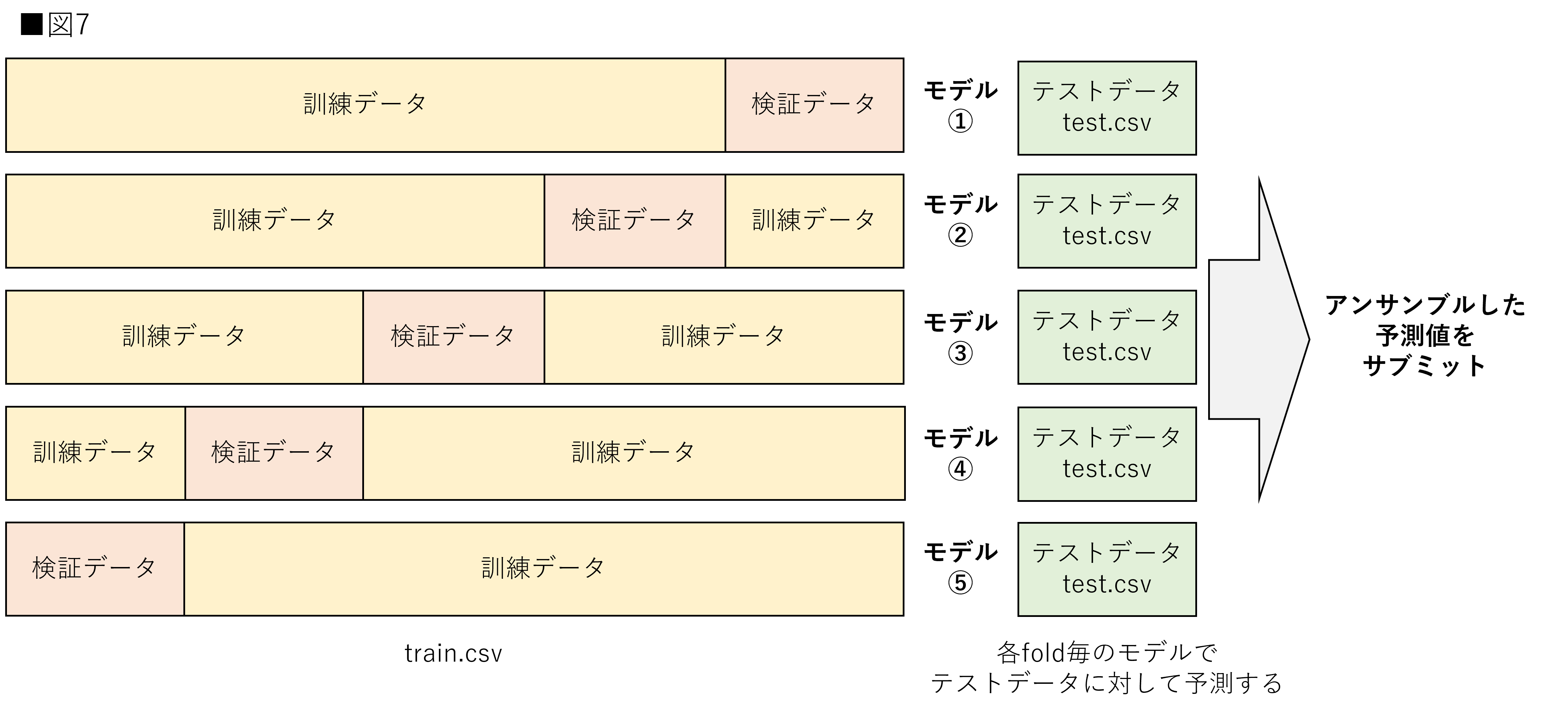
交差検証自体はハイパーパラメータの調整の時と大きな違いはありません。違いはモデルの保存が必要ということです。コンペティションではテストデータのラベルが存在しないため、交差検証時に各foldのモデルを保存します。同じテストデータに対して各モデルでアンサンブルした予測値をサブミットします。サブミット数には制限がある場合もあります。そのため、ある程度までは訓練データと検証データを用いた交差検証でモデルの良し悪しを判断します。
交差検証の種類
ここまで、交差検証の概要について解説してきました。ここからは交差検証の種類について解説します。ここでいう種類とはデータ分割の仕方を指します。データ分割の仕方を間違えるとテストデータや検証データに対する予測が正確に行われない可能性があります。各交差検証の必要性については各節で解説します。また、本節では理解しやすいように、訓練データとテストデータのみで解説を進めます。コンペティションなどに応用したい方はテストデータを検証データと思っていただければ問題ありません。
本稿はGoogle Colabを用いて実装していきます。ライブラリをそのままインポートすれば同じように実装可能です。是非、ご自身でも実装してみてください。Google Colabを使用したことがない方は下記の記事を参考にしてください。(参考:Google Colabの知っておくべき使い方 – Google Colaboratoryのメリット・デメリットや基本操作のまとめ)
先に今回使用するデータセットの作成をします。データセットについてですが、dataには通常の文字列、labelには目的変数、groupにはdataが属しているグループが示されています。細かくはコード内に記載してありますので確認してください。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
#[IN]: #ライブラリのインポート import numpy as np import pandas as pd #データの準備 all = dict( #分割する文字列 data = ["0","1","2","3","4","5","6","7","8","9"], #目的変数 label = [1,1,1,1,1,0,0,0,0,0], #dataが所属するグループ group = [1,0,1,0,1,0,1,0,1,0], ) #DataFrameを作成 df = pd.DataFrame(data = all) #各列を抽出 data = df["data"] label = df["label"] group = df["group"] |
ホールドアウト
ホールドアウト(Holdout)法は最もシンプルな方法です。本稿では交差検証と一緒に解説していますが、実際には交差検証には含まれません。これはホールドアウト法が交差を行なっていないためです。ホールドアウト法はデータセット全体をランダムに分割することで行えます。交差検証は分割した分だけ学習時間が長くなる傾向があるため、短い時間で判断する場合にはホールドアウト法は有効です。実装も非常に簡単ですので、初学者の方にオススメです。

実装はscikit-learnに用意されているtrain_test_split()を使用しします。train_test_split()はデータと目的変数を与え、引数を指定することで指定した割合で分割することができます。今回は2割をテストデータとします。重要な引数に関しては以下に記載します。詳細については公式ドキュメントを参照してください。(参考:scikit-learn公式:train_test_split)
- train_size:訓練データの割合
- test_size:テストデータの割合
- shuffle:シャッフルの有無
- random_state:シード値
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
#[IN]: #train_test_splitのインポート from sklearn.model_selection import train_test_split #データ分割 train_x, test_x, train_y, test_y = train_test_split(data, label, train_size = 0.8 ,test_size = 0.2, shuffle = True, random_state = 0) #訓練データの確認 print(train_x.values) print(train_y.values) #テストデータの確認 print(test_x.values) print(test_y.values) |
|
1 2 3 4 5 6 7 8 |
#[OUT] ['4' '9' '1' '6' '7' '3' '0' '5'] [1 0 1 0 0 1 1 0] ['2' '8'] [1 0] |
K分割交差検証(K-Fold Cross-Validation)
K分割交差検証(以下K-Fold)は最も一般的な交差検証です。データをK個に分割し、K-1個を訓練データ、1個をテストデータとします。データを交差させながらK回行い、得られた結果の平均値を求めます。前節で解説したように、モデルの評価の正しい推定値を得るために使用されます。図9はK-Foldを示しています。
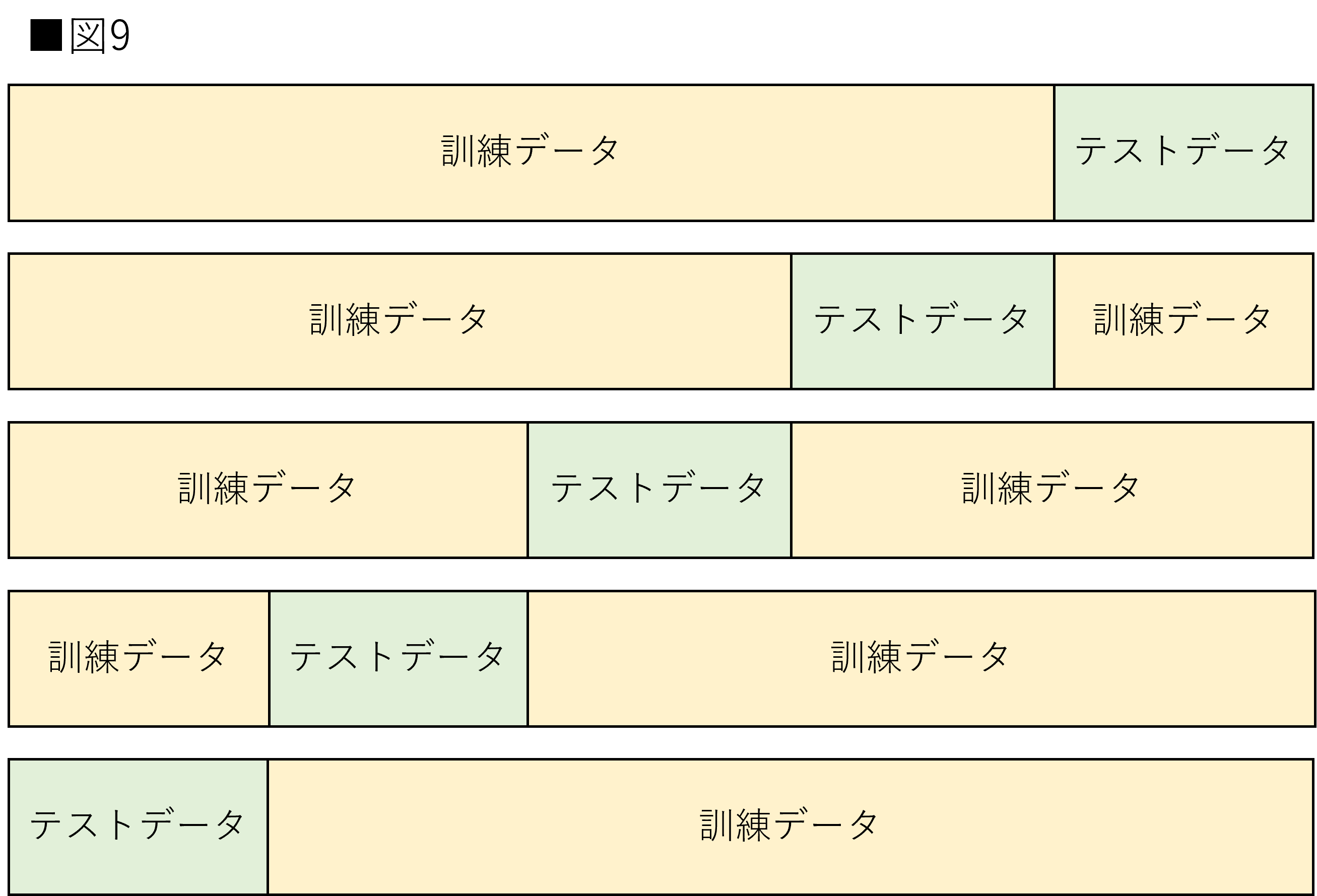
実装はscikit-learnに用意されているKFold()を使用しします。KFold()は分割数を引数に指定することができます。交差検証は、split()メソッドをfor文で扱うことで実装できます。for文内のtrainとtestは分割された際のindex値です。今回は5分割で実装します。重要な引数に関しては以下に記載します。詳細については公式ドキュメントを参照してください。(参考:scikit-leanr公式:KFold)
- n_splits:分割数
- shuffle:シャッフルの有無
- random_state:シード値
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
#[IN]: #KFoldのインポート from sklearn.model_selection import KFold #KFoldの設定 kf = KFold(n_splits = 5, shuffle = True, random_state = 1) #交差検証 for train, test in kf.split(df): print(f"訓練データは:{data[train].values}, テストデータは:{data[test].values}") print(f"訓練ラベルは:{label[train].values}, テストラベルは:{label[test].values}") |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
#[OUT] 訓練データは:['0' '1' '3' '4' '5' '6' '7' '8'], テストデータは:['2' '9'] 訓練ラベルは:[1 1 1 1 0 0 0 0], テストラベルは:[1 0] 訓練データは:['0' '1' '2' '3' '5' '7' '8' '9'], テストデータは:['4' '6'] 訓練ラベルは:[1 1 1 1 0 0 0 0], テストラベルは:[1 0] 訓練データは:['1' '2' '4' '5' '6' '7' '8' '9'], テストデータは:['0' '3'] 訓練ラベルは:[1 1 1 0 0 0 0 0], テストラベルは:[1 1] 訓練データは:['0' '2' '3' '4' '5' '6' '8' '9'], テストデータは:['1' '7'] 訓練ラベルは:[1 1 1 1 0 0 0 0], テストラベルは:[1 0] 訓練データは:['0' '1' '2' '3' '4' '6' '7' '9'], テストデータは:['5' '8'] 訓練ラベルは:[1 1 1 1 1 0 0 0], テストラベルは:[0 0] |
シャッフル分割交差検証(Shuffle-Split Cross-Validation)
シャッフル分割交差検証(以下Shuffle-Split)はK-Foldに少し改良が加えられた交差検証です。Shuffle-Splitの特徴は訓練・テストデータ両方の割合を指定できるところにあります。これによりデータセット全体からサンプルしたデータで交差検証を行うことができます。訓練・テストデータ両方に使用されていないデータが存在したり、逆に同じデータが2回テストデータに使用される場合もあります。データセットのサイズがとても大きい場合などに有効です。図10はShuffle-Splitを示しています。
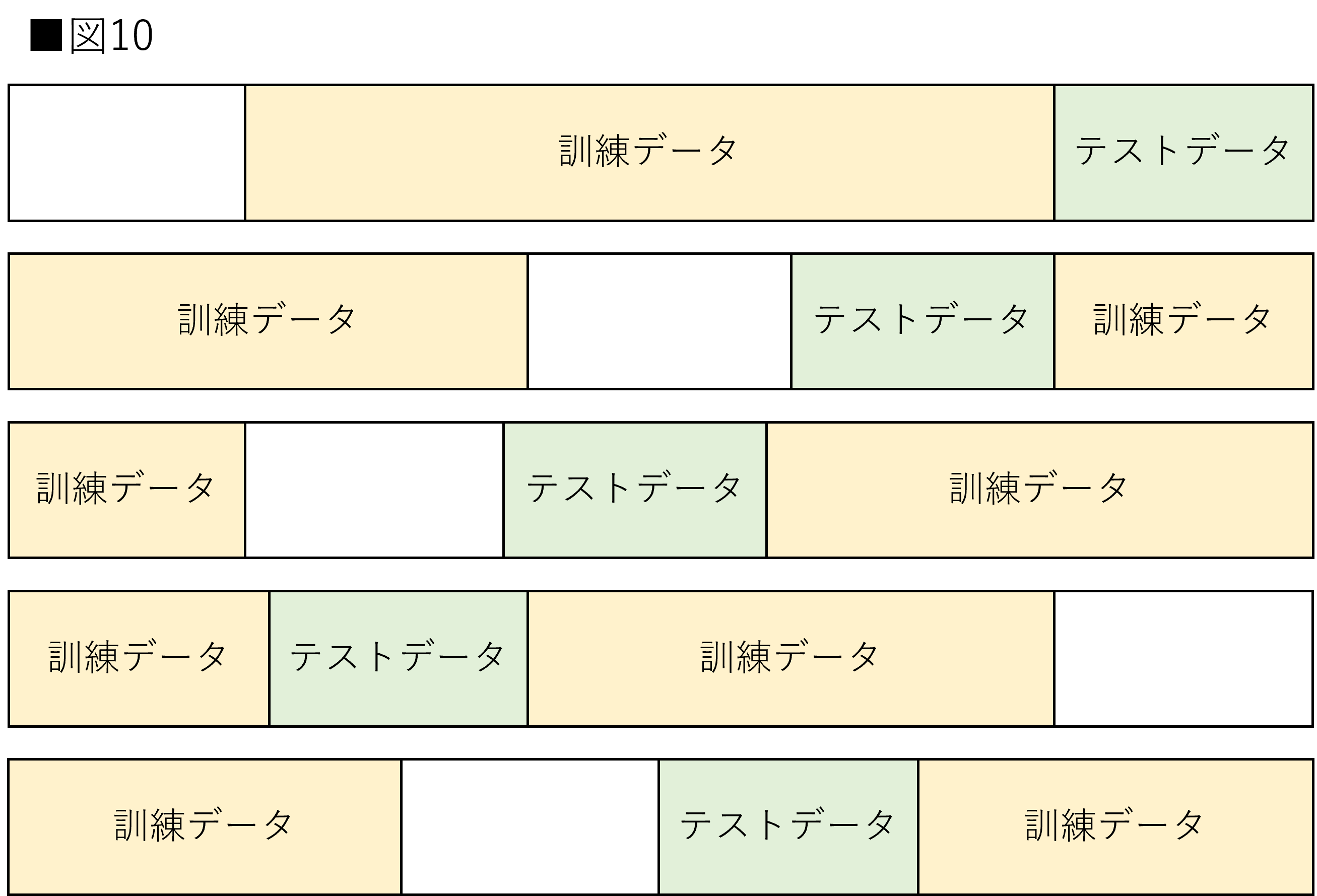
実装はscikit-learnに用意されているShuffleSplit()を使用します。ShuffleSplit()は分割数を引数に指定することができます。for文を使用すること、split()メソッドを使用することはKFold()と同様です。今回は5分割で実装します。また、train_sizeを0.7、test_sizeを0.2として、データセットの一部を使用していません。重要な引数に関しては以下に記載します。詳細については公式ドキュメントを参照してください。(参考:scikit-leanr公式:ShuffleSplit)
- n_splits:分割数
- train_size:訓練データの割合
- test_size:テストデータの割合
- random_state:シード値
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
#[IN]: #ShuffleSplitのインポート from sklearn.model_selection import ShuffleSplit #ShuffleSplitの設定 ss = ShuffleSplit(n_splits = 5, train_size = 0.7, test_size = 0.2, random_state = 0) #交差検証 for train, test in ss.split(df): print(f"訓練データは:{data[train].values}, テストデータは:{data[test].values}") print(f"訓練ラベルは:{label[train].values}, テストラベルは:{label[test].values}") |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
#[OUT] 訓練データは:['4' '9' '1' '6' '7' '3' '0'], テストデータは:['2' '8'] 訓練ラベルは:[1 0 1 0 0 1 1], テストラベルは:[1 0] 訓練データは:['1' '2' '9' '8' '0' '6' '7'], テストデータは:['3' '5'] 訓練ラベルは:[1 1 0 0 1 0 0], テストラベルは:[1 0] 訓練データは:['8' '4' '5' '1' '0' '6' '9'], テストデータは:['2' '3'] 訓練ラベルは:[0 1 0 1 1 0 0], テストラベルは:[1 1] 訓練データは:['9' '2' '7' '5' '8' '0' '3'], テストデータは:['6' '1'] 訓練ラベルは:[0 1 0 0 0 1 1], テストラベルは:[0 1] 訓練データは:['7' '4' '1' '0' '6' '8' '9'], テストデータは:['5' '2'] 訓練ラベルは:[0 1 1 1 0 0 0], テストラベルは:[0 1] |
層化K分割交差検証(Stratified K-Fold)
層化K分割交差検証(以下:Stratified K-fold)は目的変数の割合が等しくなるように分割する交差検証です。データセットの目的変数は常に同じ割合であるとは限りません。目的変数の一つが極端に少ない場合、テストデータに目的変数の全種類が存在しない可能性が考えられます。Stratified K-foldはそのような問題を解決します。図11はStratified K-foldを示しています。
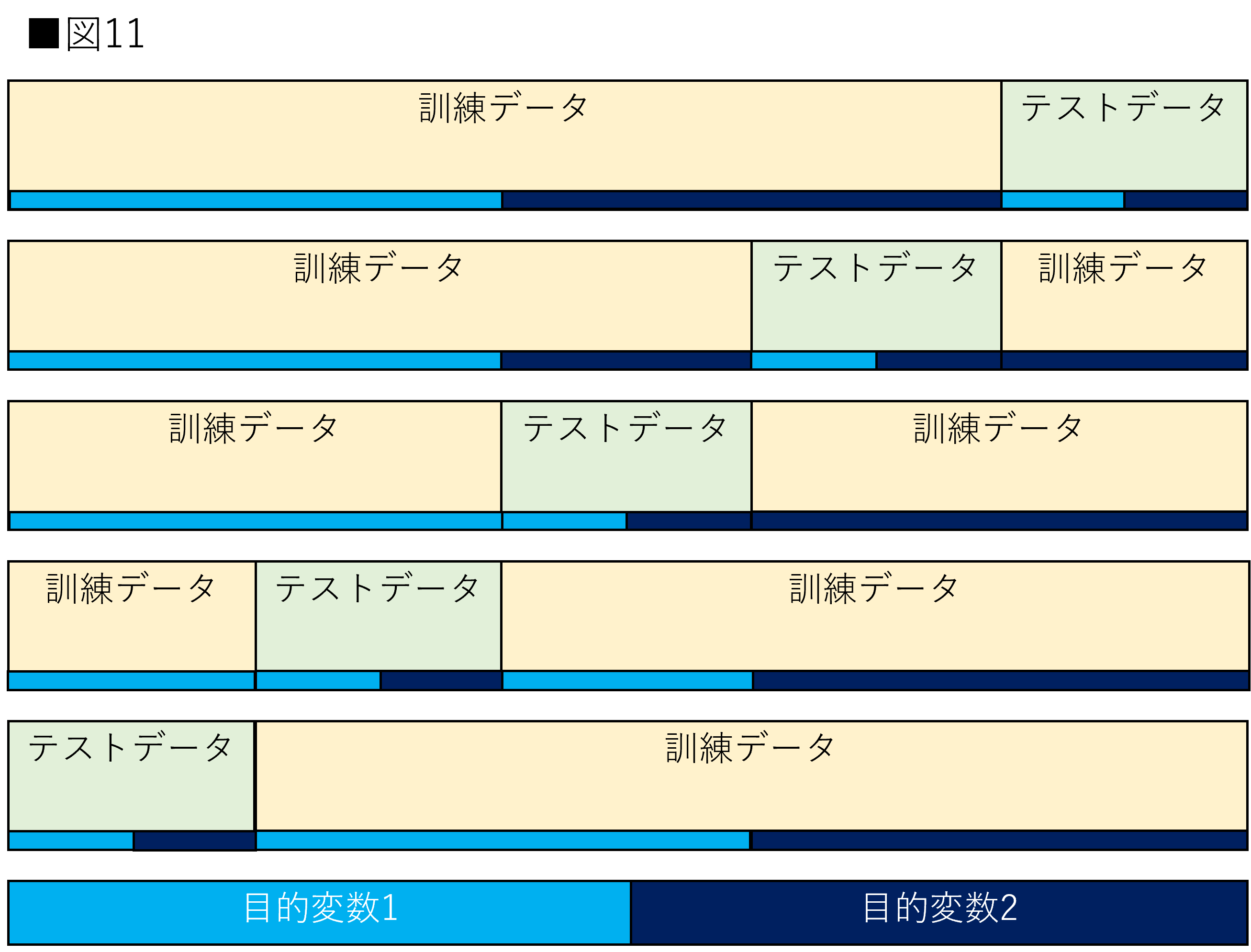
目的変数の割合が5:5である場合を考えます。Stratified K-foldを使用すると訓練・テストデータ共に目的変数の割合が必ず5:5になります。目的変数の割合が9:1であっても同様です。これによって常に訓練とテストの条件を同一にすることができます。筆者も他に制約が存在しない場合はStratified K-foldを使用することが多いです。
実装はscikit-learnに用意されているStratifiedKFold()を使用しします。StratifiedKFold()は分割数を引数に指定することができます。for文を使用すること、split()メソッドを使用することはKFlod()と同様です。StratifiedKFold()ではsplitメソッド使用時に第二引数に目的変数を与えることで、訓練・テストに割り振ってくれます。今回は5分割で実装します。重要な引数に関しては以下に記載します。詳細については公式ドキュメントを参照してください。(参考:scikit-leanr公式:StratifiedKFold)
- n_splits:分割数
- shuffle:シャッフルの有無
- random_state:シード値
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
#[IN]: #StratifiedKFold from sklearn.model_selection import StratifiedKFold #StratifiedKFoldの設定 skf = StratifiedKFold(n_splits = 5, shuffle = True, random_state = 0) #交差検証 for train, test in skf.split(df, label): print(f"訓練データは:{data[train].values}, テストデータは:{data[test].values}") print(f"訓練ラベルは:{label[train].values}, テストラベルは:{label[test].values}") |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
#[OUT] 訓練データは:['0' '2' '3' '4' '6' '7' '8' '9'], テストデータは:['1' '5'] 訓練ラベルは:[1 1 1 1 0 0 0 0], テストラベルは:[1 0] 訓練データは:['0' '1' '3' '4' '5' '6' '8' '9'], テストデータは:['2' '7'] 訓練ラベルは:[1 1 1 1 0 0 0 0], テストラベルは:[1 0] 訓練データは:['1' '2' '3' '4' '5' '7' '8' '9'], テストデータは:['0' '6'] 訓練ラベルは:[1 1 1 1 0 0 0 0], テストラベルは:[1 0] 訓練データは:['0' '1' '2' '4' '5' '6' '7' '8'], テストデータは:['3' '9'] 訓練ラベルは:[1 1 1 1 0 0 0 0], テストラベルは:[1 0] 訓練データは:['0' '1' '2' '3' '5' '6' '7' '9'], テストデータは:['4' '8'] 訓練ラベルは:[1 1 1 1 0 0 0 0], テストラベルは:[1 0] |
グループK分割交差検証(Group K-Fold)
グループK分割交差検証(以下:Group K-Fold)は訓練・テストデータの両方に同一のグループが含まれることを避ける交差検証です。例えば医療画像などで、同一の患者が訓練・テストデータの間で被らないようにする場合などで使用されます。仮に、同じ患者のデータは他の患者に比べて似る傾向があるとします。訓練データで学習した患者と同一患者をテストデータで予測する場合、他の患者を予測するよりも簡単である可能性があります。図12は医療データの分割の例を示しています。
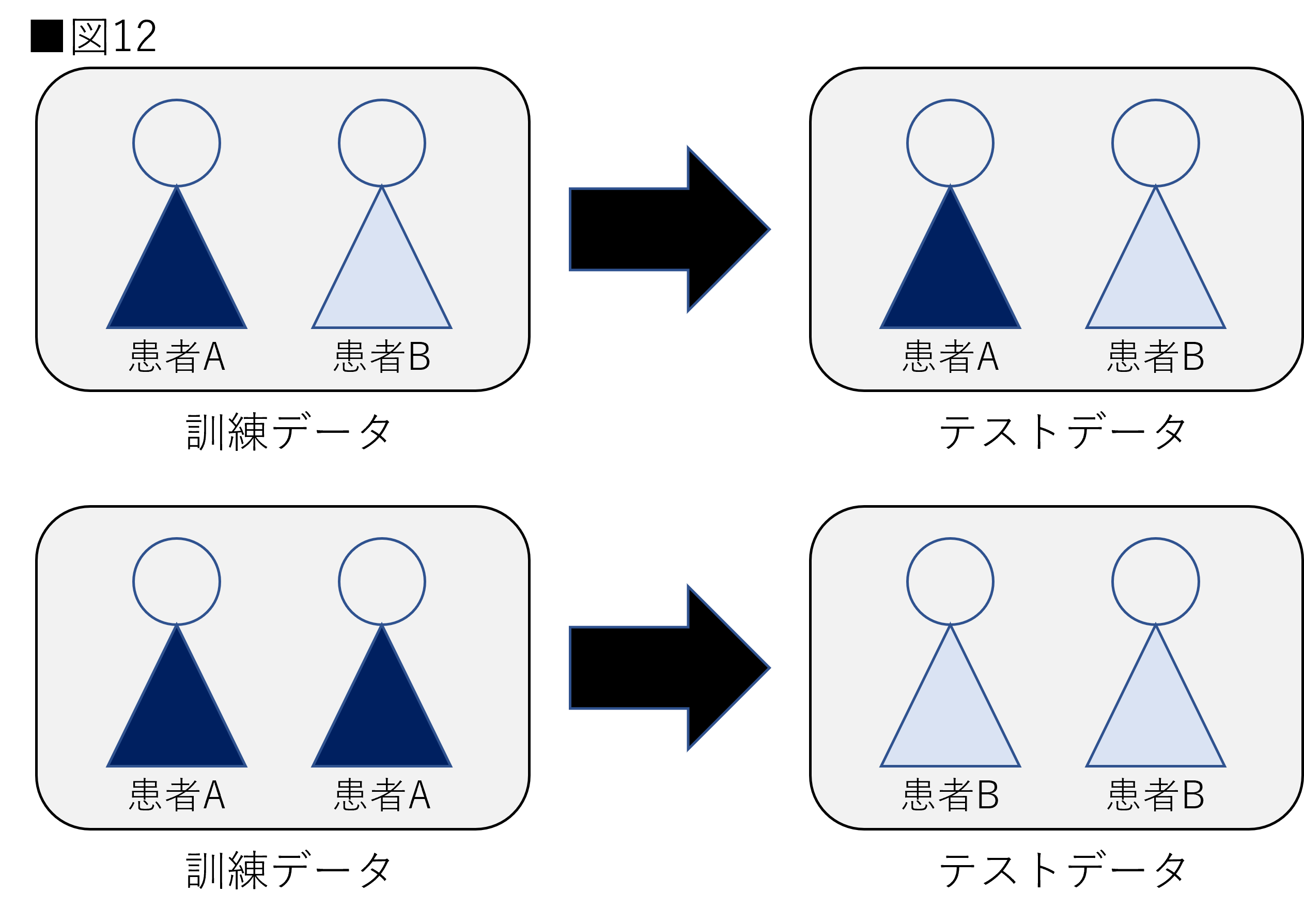
図12を見ると上図は同一患者が訓練とテストに存在しています。例えば病気の陽陰性を判断するモデルを作成する場合、上図では非常に簡単です。なぜなら訓練・テストデータに存在する同一患者は同じ診断結果である可能性が非常に高いためです。これでは正しく評価を行えません。この場合は下図のように、患者を分け、新たな患者が与えられたときに正しく診断できる予測モデルを作成することが求められます。図13はGroup K-Foldを示しています。
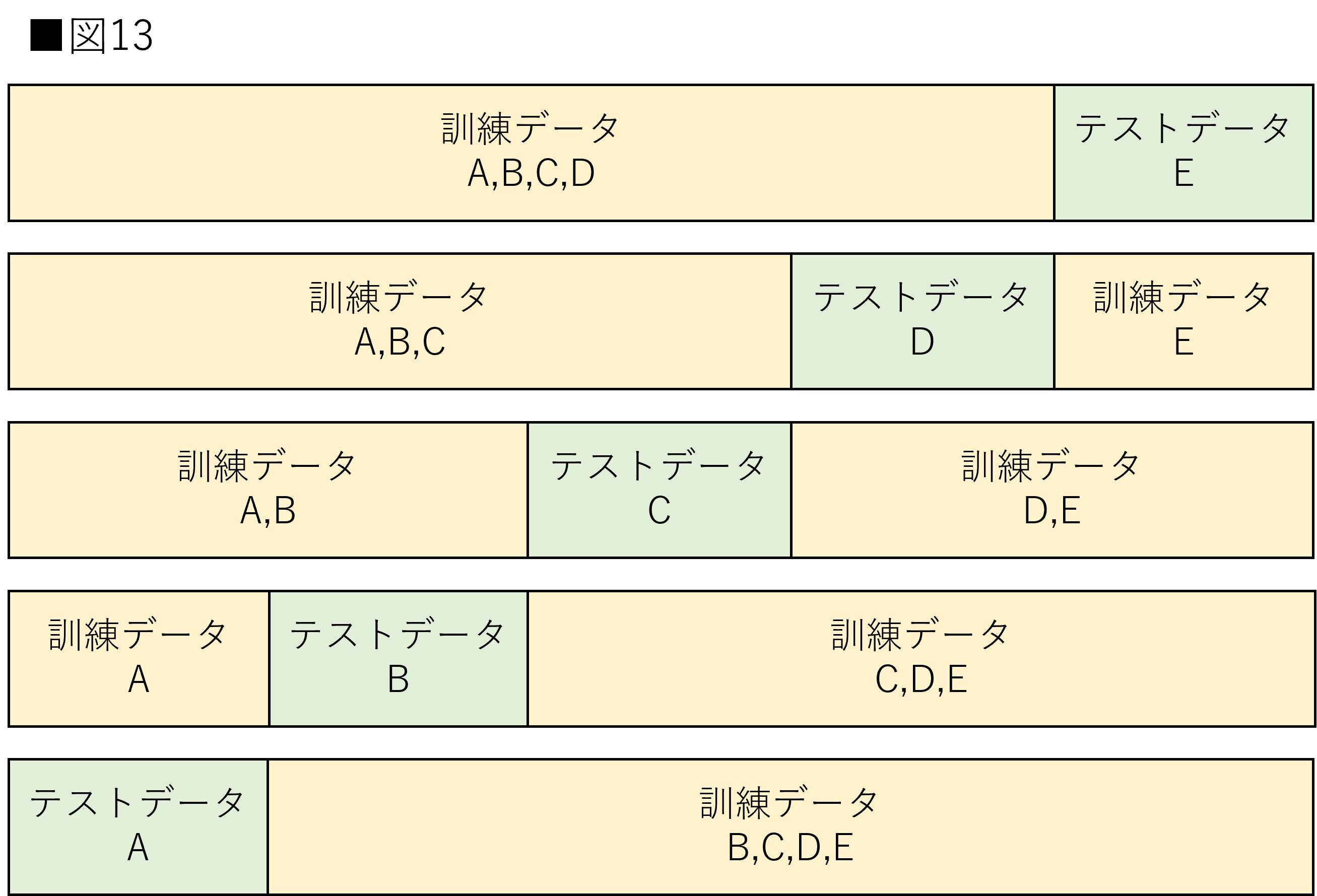
図13のアルファベットはグループを表しています。訓練データとテストデータに同じグループが存在しないように分割されます。注意点としてはGroup K-Foldでは各グループが一度はテストデータに含まれることになります。つまり交差検証の回数Kはグループ数以下でなければならない点に注意てしてください。また、グループ毎の数が異なる場合、訓練とテストデータの割合はグループによって変化する場合があります。
実装はscikit-learnに用意されているGroupKFold()を使用しします。GroupKFold()は分割数を引数に指定することができます。for文を使用すること、split()メソッドを使用することはKFlod()と同様です。GroupKFold()ではsplitメソッド使用時にgroups引数にグループの変数を与えることで、訓練・テストに割り振ってくれます。今回は2分割で実装します。重要な引数に関しては以下に記載します。詳細については公式ドキュメントを参照してください。(参考:scikit-leanr公式:GroupKFold)
- n_splits:分割するKの値
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
#[IN]: #GroupKFoldのインポート from sklearn.model_selection import GroupKFold #GroupKFoldの設定 gkf = GroupKFold(n_splits = 2) #交差検証 for train, test in gkf.split(df,groups=group): print(f"訓練データは:{data[train].values}, テストデータは:{data[test].values}") print(f"訓練ラベルは:{label[train].values}, テストラベルは:{label[test].values}") print(f"訓練グループは:{group[train].values}, テストグループは:{group[test].values}") |
|
1 2 3 4 5 6 7 8 9 10 |
#[OUT] 訓練データは:['1' '3' '5' '7' '9'], テストデータは:['0' '2' '4' '6' '8'] 訓練ラベルは:[1 1 0 0 0], テストラベルは:[1 1 1 0 0] 訓練グループは:[0 0 0 0 0], テストグループは:[1 1 1 1 1] 訓練データは:['0' '2' '4' '6' '8'], テストデータは:['1' '3' '5' '7' '9'] 訓練ラベルは:[1 1 1 0 0], テストラベルは:[1 1 0 0 0] 訓練グループは:[1 1 1 1 1], テストグループは:[0 0 0 0 0] |
Stratified K-FoldとGroup K-Foldを合わせたStratifiedGroup KFoldも存在します。StratifiedGroup KFoldはその名の通り2つの機能を合わせた機能を有しています。使い方は他と同様に目的変数とグループの変数を引数に渡してあげるだけです。非常に便利ですので是非使ってみてください。(参考:scikit-learn StratifiedGroupKFold)
時系列交差検証(Time Series Split)
時系列交差検証は時系列に沿った交差検証を行うための方法です。時系列データには1つのデータに対する過去と未来が存在します。仮に、未来のデータを用いて訓練を行なった場合、他の未来データに対する予測も容易になる可能性があります。そのため、時系列に沿った分割を行う必要性があります。時系列交差検証はこれらの問題を解決します。図14は時系列交差検証を示しています。
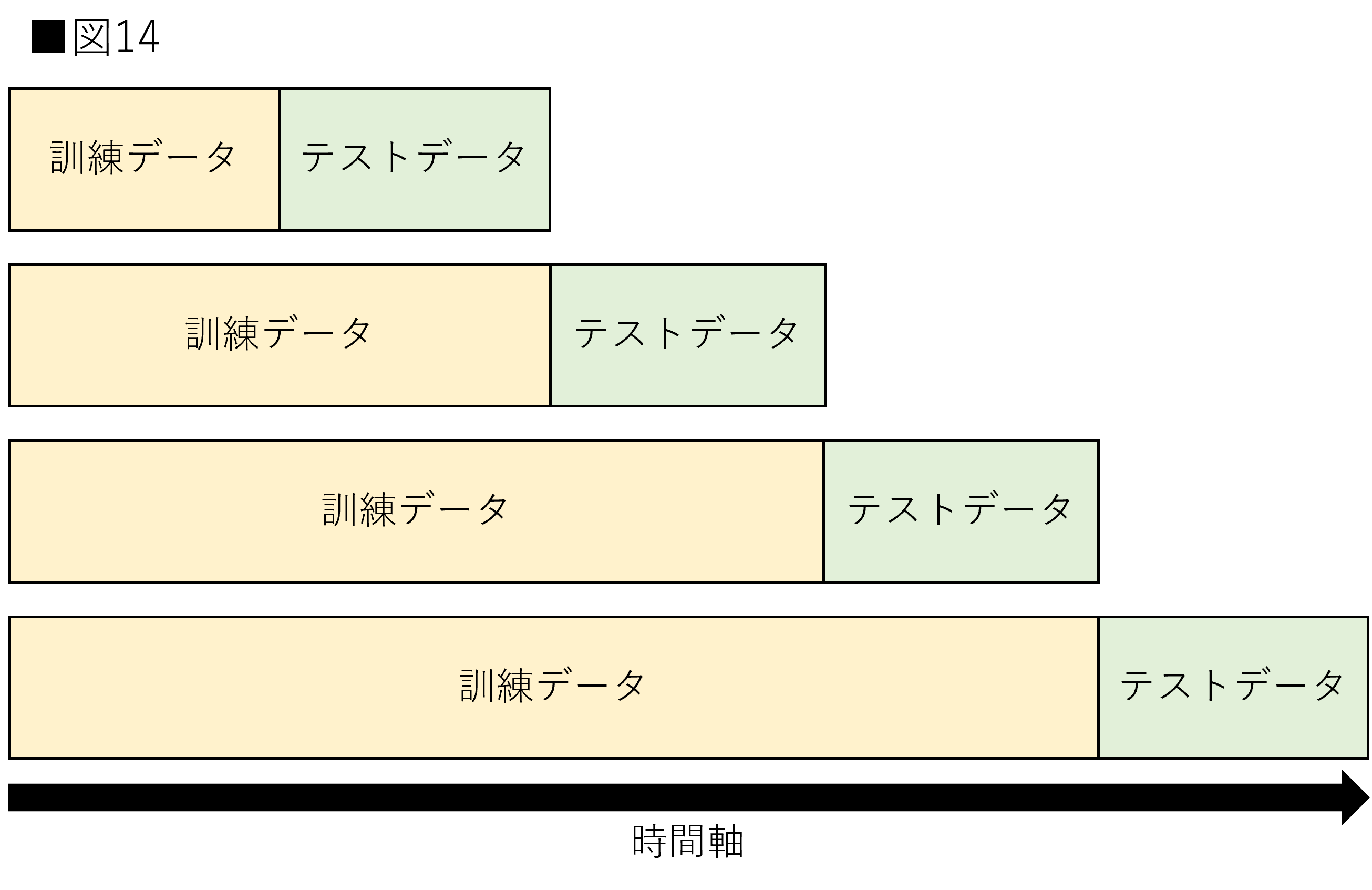
今までとは交差検証の形式が異なります。時間軸に沿ったようにデータ分割が行われ、テストデータ以降のデータが訓練データに使用されることはありません。また、テストデータの時間が後になるについれて訓練データに使用できるデータ量も多くなります。場合によっては訓練データの量を一定に揃える場合もあります。
実装はscikit-learnに用意されているTimeSeriesSplit()を使用します。TimeSeriesSplit()は分割数を引数に指定することができます。for文を使用すること、split()メソッドを使用することはKFlod()と同様です。TimeSeriesSplit()ではmax_train_sizeを指定することで訓練データのサイズを指定できます。今回3分割で実装します。重要な引数に関しては以下に記載します。詳細については公式ドキュメントを参照してください。(参考:scikit-leanr公式:TimeSeriesSplit)
- n_splits:分割数
- max_train_size:訓練データのサイズ
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
#[IN]: #TimeSeriesSplitのインポート #訓練データサイズの指定なし from sklearn.model_selection import TimeSeriesSplit #TimeSeriesSplitの設定 #訓練データサイズの指定なし tss_a = TimeSeriesSplit(n_splits = 3, max_train_size = None) #交差検証 for train, test in tss_a.split(data): print(f"訓練用データは:{np.sort(data[train])}, 検証用データは:{np.sort(data[test])}") |
|
1 2 3 4 5 6 7 |
#[OUT] 訓練用データは:['0' '1' '2' '3'], 検証用データは:['4' '5'] 訓練用データは:['0' '1' '2' '3' '4' '5'], 検証用データは:['6' '7'] 訓練用データは:['0' '1' '2' '3' '4' '5' '6' '7'], 検証用データは:['8' '9'] |
|
1 2 3 4 5 6 7 8 9 10 11 |
#[IN]: #TimeSeriesSplitの設定 #訓練データサイズの指定あり tss_b = TimeSeriesSplit(n_splits = 3, max_train_size = 2) #交差検証 for train, test in tss_b.split(data): print(f"訓練用データは:{np.sort(data[train])}, 検証用データは:{np.sort(data[test])}") |
|
1 2 3 4 5 6 7 |
#[OUT] 訓練用データは:['2' '3'], 検証用データは:['4' '5'] 訓練用データは:['4' '5'], 検証用データは:['6' '7'] 訓練用データは:['6' '7'], 検証用データは:['8' '9'] |
ここまで、複数の交差検証を解説してきました。データ分割の話も含んでいるので難しい部分もあるかと思います。言葉では理解しきれなかったという方は後半の実装まで読んでいただき、もう一度読み返して見ることをお勧めします。
モデルの汎化性能を評価する交差検証の実装
ここからは以下の3つをコードとともに解説します。1つ1つ丁寧に解説していきますので初学者の方も是非取り組んでください。
- モデルの汎化性能を評価する交差検証の実装
- ハイパーパラメータチューニングのための交差検証の実装
- コンペティションで使用される交差検証の実装
本節では、モデルの汎化性能を評価するための交差検証を行います。先ほどの解説でもあったようにこの交差検証は、研究などのデータセットが1つの場面で比較的使用されます。最も基礎的な実装になりますので、確実に押さえてください。前節までの実装は引き継ぎません。改めてライブラリのインポートから始めます。ポイントとなるライブラリについてはその都度追加していきます。
|
1 2 3 4 5 6 7 8 9 |
#[IN] #ライブラリのインポート import numpy as np import pandas as pd import warnings warnings.filterwarnings('ignore') |
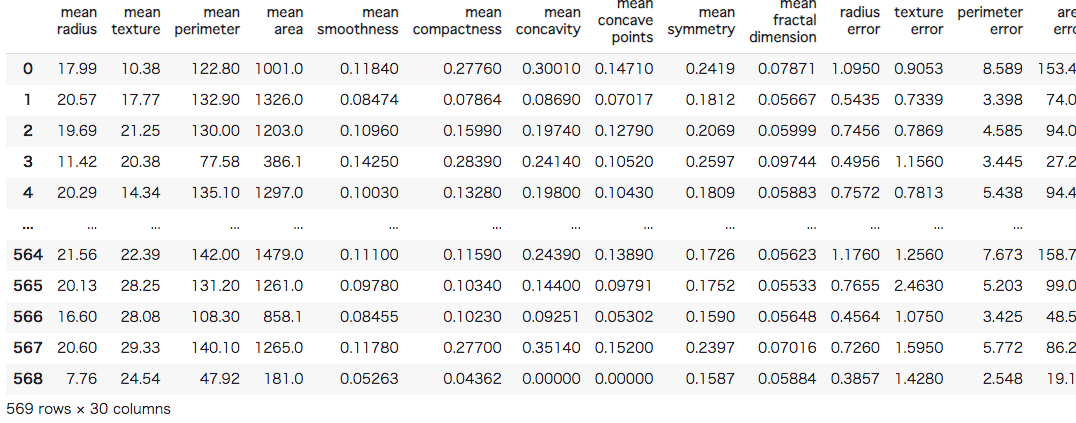
次に、データセットを準備します。今回使用するデータセットは乳がんのデータセットです。30の特徴量から悪性と良性の2値分類を行います。データ数は全部で569です。本稿では各特徴量に関する解説は省きますが、興味のある方はダウンロード元を調べてみてください。(参考:Breast Cancer Wisconsin (Diagnostic) Data Set)
|
1 2 3 4 5 6 7 8 9 10 11 12 |
#[IN] #データセットの追加 from sklearn.datasets import load_breast_cancer src = load_breast_cancer() #データセットをDataFrameにする data = pd.DataFrame(src.data, columns = src.feature_names) label = pd.DataFrame(src.target, columns = ["Target"]) data |
ホールドアウト法
次に、データ分割に移ります。今回はホールドアウト法を用いた2分割と、交差検証を用いた結果を比較したいと思います。先にホールドアウト法から行います。ホールドアウト法はtrain_test_split()を用いて行います。8割を訓練データ、2割をテストデータにします。
|
1 2 3 4 5 6 7 8 9 |
#[IN]: #train_test_splitのインポート from sklearn.model_selection import train_test_split #データ分割 train_x, test_x, train_y, test_y = train_test_split(data, label ,test_size = 0.2, shuffle = True, random_state = 0) |
次に、データの標準化を行います。標準化は学習の効率を高めるために使用します。テストデータは訓練データの値を用いて標準化されます。標準化は交差検証の際にもう一度登場しますので、知識に不安のある方は以下を参考にしてください。(参考:正規化・標準化を徹底解説)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
#[IN]: #StandardScalerのインポート from sklearn.preprocessing import StandardScaler #標準化のクラスを定義 ss_holdout = StandardScaler() #訓練データを標準化 train_x = ss_holdout.fit_transform(train_x) #訓練データの値を用いてテストデータを標準化 test_x = ss_holdout.transform(test_x) |
次に、モデル構築を行います。使用するのはロジスティック回帰です。8割の訓練データを用いて学習を行います。ロジスティック回帰は機械学習の中で最も初歩的な手法の1つです。知識的に不安のある方は以下のコースの受講をおすすめします。(参考:機械学習チュートリアル:ロジスティック回帰)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
#[IN] #ロジスティック回帰のインポート from sklearn.linear_model import LogisticRegression #ロジスティック回帰の設定 lr = LogisticRegression(solver = "sag", random_state = 0) #訓練 lr.fit(train_x, train_y) #テストデータに対する予測 pred = lr.predict(test_x) pred |
|
1 2 3 4 5 6 7 8 9 10 |
#[OUT] array([0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 0, 1, 0, 0, 0, 0, 0, 1, 1, 0, 1, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 0, 1, 0, 1, 1, 0, 1, 1, 1, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 0, 0, 0, 1, 1, 0, 1, 0, 0, 0, 1, 1, 0, 1, 0, 0, 1, 1, 1, 1, 1, 0, 0, 0, 1, 0, 1, 1, 1, 0, 0, 1, 0, 0, 0, 1, 1, 0, 1, 1, 1, 1, 1, 1, 1, 0, 1, 0, 1, 1, 1, 1, 0, 0, 1]) |
次に、予測した値の評価を行います。評価に関しては正解率(Accuracy)を用います。評価指標は機械学習を学ぶ上で非常に重要です。評価指標に対してより詳しく知りたい方は以下の記事を確認してください。(参考:機械学習の評価指標 分類編)
|
1 2 3 4 5 6 7 |
#[IN] #Accuracyを計算 from sklearn.metrics import accuracy_score accuracy_score(test_y, pred) |
|
1 2 3 4 5 |
#[OUT] 0.9649122807017544 |
正解率が出力されました。しかし、この正解率にはどれほどの信頼が置けるでしょうか。0.96という結果は非常に高いようにも感じられますが、それはホールドアウト法で偶然にもそういった結果が得られたかもしれません。次の交差検証で検証します。
層化K分割交差検証(Stratified K-Fold)
交差検証に入る前に準備を行います。先ほど行なった標準化を交差検証でも行います。交差検証の場合、fold毎に標準化を適用し直さなければなりません。交差検証時の標準化の適用を図15に示します。
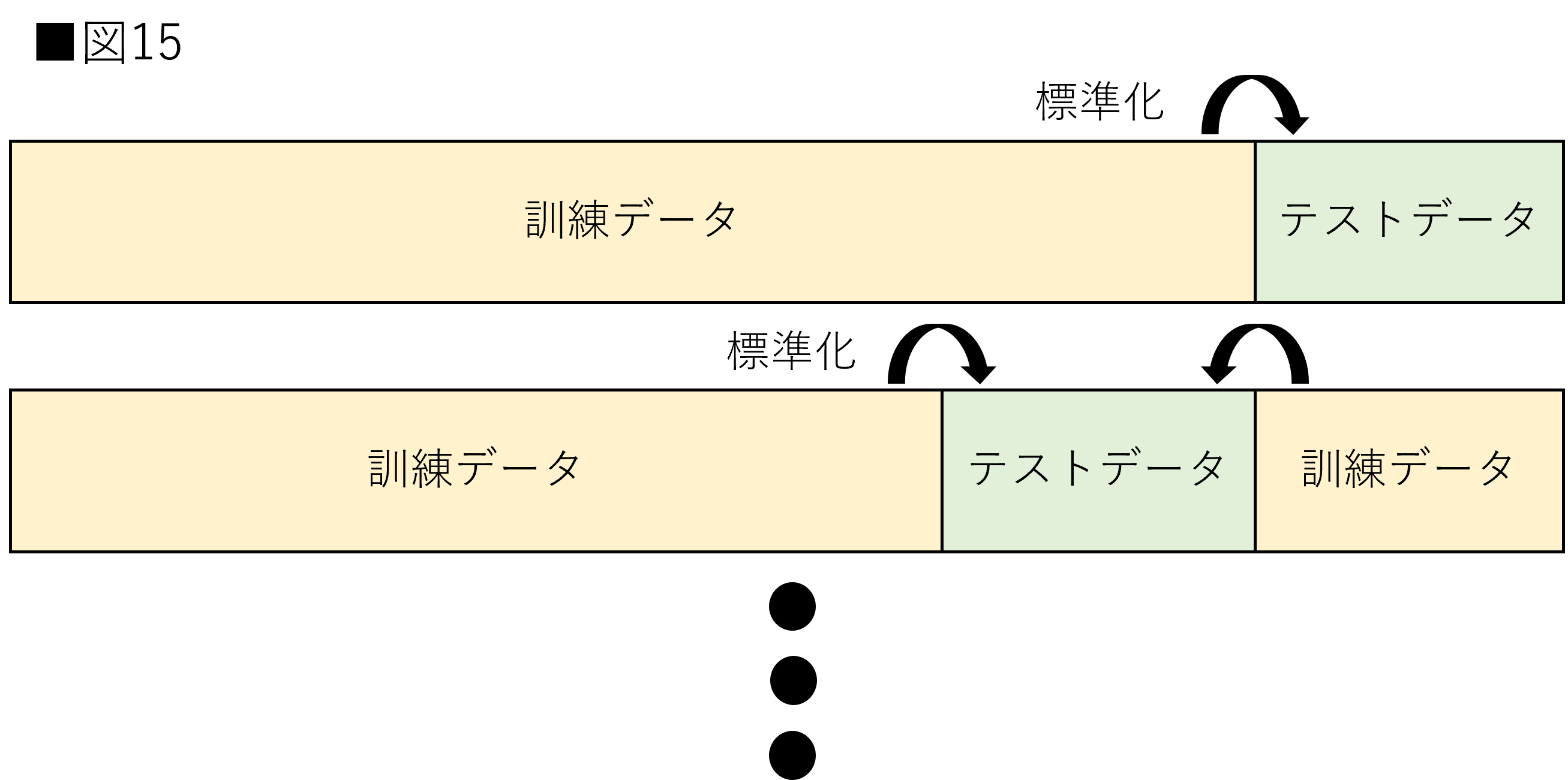
図15のように標準化を適用するために、Pipelineを用います。Pipelineはデータの前処理から学習までを一連の処理として定義できます。今回は標準化とロジスティック回帰の構築を一連の処理としてまとめます。これにより、交差検証を実装する際にも、fold毎に標準化を行うことができます。(scikit-lean公式:Pipeline)
|
1 2 3 4 5 6 7 8 9 10 11 12 |
#[IN]: #StratifiedKFold from sklearn.pipeline import Pipeline #標準化の設定 ss_kfold = StandardScaler() #パイプラインの設定 pl = Pipeline([('tf', ss_kfold), ('lr', lr)]) |
次に、交差検証を行います。本節で使用する交差検証はStratified K-Foldになります。使用の理由としては今回の目的変数の割合が5:5でないためです。悪性:良性=212:357であるため、目的変数の割合に若干の違いがあります。そのため、Stratified K-Foldを用いて、訓練とテストの目的変数の割合を等しくします。
実装は非常に簡単です。前半での説明は読者の皆様に直感的に理解いただけるようfor文とsplit()などを用いて実装しました。このやり方は非常に便利ですが、少し難易度が高いです。評価を出すことだけが目的であれば、cross_val_score()を用いた方が簡単です。主な引数に関する情報は以下に示します。
- 第1引数:estimator(モデルなど)
- 第2引数:特徴量
- 第3引数:目的変数
- group:GruoKfoldで指定する特徴量
- scoreing:評価指標
- cv:交差検証の指定
引数のscoreingですが、様々な評価指標を設定できます。他の評価指標に関しては以下を参考にしてください。また、本稿で紹介する引数は上記6つですが、cross_val_score()には他にも引数が存在します。上記6つも用途によって若干条件が変更される場合があります。より詳細に知りたい方は公式ドキュメントを参考にしてください。(参照:scikit-learn公式:scoreing・cross_val_score)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
#[IN]: #StratifiedKFold from sklearn.model_selection import StratifiedKFold from sklearn.model_selection import cross_val_score #StratifiedKFoldの設定 skf = StratifiedKFold(n_splits = 5, shuffle = True, random_state = 0) #指定したモデル+交差検証で評価を行える #scoreには分割の数だけ評価指標がリストで入る score = cross_val_score(pl, data, label, scoring = "accuracy", cv = skf) #各foldでの正解率 print(score) #平均の正解率 print(score.mean()) |
|
1 2 3 4 5 6 |
#[OUT] [0.95614035 0.98245614 0.98245614 1. 0.98230088] 0.98067070330694 |
表示された正解率はホールドアウト法のときよりも上がっています。もしかするとホールドアウト法の時は偶然予測が難しかったのかもしれません。このように、交差検証を行うとより正確な評価を行うことができます。本節は、この後の実装にも関連する部分が多いです。理解しておいてください。
ハイパーパラメータチューニングのための交差検証の実装
本節では、ハイパーパラメータチューニングに用いられる交差検証の実装を行います。汎化性能を評価する場合との違いを意識しながら進めるようにしてください。先でも述べたように本稿ではハイパーパラメータに関する基本的な解説は省いています。あくまで交差検証のイメージを掴むための実装であることをご了承ください。
データセットは先ほどと同様です。もう一度ライブラリのインポートから始めますが、2回目ですのである程度はまとめています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
#[IN] #ライブラリのインポート import numpy as np import pandas as pd import warnings warnings.filterwarnings('ignore') from sklearn.datasets import load_breast_cancer #データセットの追加 src = load_breast_cancer() #データセットをDataFrameにする data = pd.DataFrame(src.data, columns=src.feature_names) label = pd.DataFrame(src.target, columns=["label"]) |
今回もホールドアウト法を用いて訓練データとテストデータに分割します。ハイパーパラメータチューニングの後、最終的な評価に使用するためです。先ほどとは違い、引数のstratifyを追加しています。これはStratified K-Foldと同様でデータ分割時にラベルの割合を等しくすることができます。便利な引数ですので、是非覚えていてください。
|
1 2 3 4 5 6 7 8 9 |
#[IN]: #train_test_splitのインポート from sklearn.model_selection import train_test_split #データ分割 train_x, test_x, train_y, test_y = train_test_split(data, label , test_size = 0.2, shuffle = True, stratify = label, random_state = 0) |
次に、データの前処理とモデル構築を組み合わせてPipelineを作成していきます。モデルは非線形SVM(サポートベクターマシン)を用います。サポートベクターマシンも機械学習を扱う上では重要なモデルの1つです。興味のある方には以下のコースをおすすめします。(参考:機械学習 チュートリアル サポートベクターマシン)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
#[IN]: #StandardScalerのインポート from sklearn.preprocessing import StandardScaler from sklearn.svm import SVC from sklearn.pipeline import Pipeline # 標準化のクラスを定義 ss = StandardScaler() #デフォルトの状態でモデル構築 svc = SVC() #Pipelineの作成 pl = Pipeline([("tf", ss), ("svc", svc)]) |
次に、ハイパーパラメータチューニングを行います。今回使用する手法はグリッドサーチです。「全通り試す」と思っていただければ問題ありません。難しく見えるかもしれませんが実装はシンプルです。まず試行したいハイパーパラメータを準備します。これらは辞書型で用意すれば問題ありません。今回、SVCにおけるlinearにはgmmaは利用できません。そのため、linearだけは別で用意しています。
今回のハイパーパラメータはPipeline上のモデルに適用することになります。この場合、Pipeline上のどのステップに適用するかを指定する必要があります。そのため、通常とはパラメータの名前が若干変わります。
Pipelineでのステップ名__パラメータ名:[試行するパラメータ]
のように、Pipelineでのステップ名が必要になります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
#[IN]: #必要なライブラリのインポート from sklearn.model_selection import StratifiedKFold from sklearn.model_selection import GridSearchCV #試行するハイパーパラメータ parameters = [ {"svc__kernel": ["rbf", "sigmoid", "poly"], "svc__gamma": [0.001, 0.0001], "svc__C": [1, 10, 100, 1000], "svc__random_state": [0]}, {"svc__kernel": ["linear"], "svc__C": [1, 10, 100, 1000], "svc__random_state": [0]}] #グリッドサーチ内で行う交差検証の種類を指定 skf = StratifiedKFold(n_splits = 5, shuffle = True, random_state = 0) #グリッドサーチの設定 clf = GridSearchCV(pl, parameters, cv = skf, scoring = "accuracy") #交差検証しながらグリッドサーチ開始 clf.fit(train_x, train_y) #交差検証の中で最も良かったスコアを表示 print(clf.best_score_) #その時のパラメータを表示 print(clf.best_params_) |
|
1 2 3 4 5 6 |
#[OUT] 0.9824175824175825 {'svc__C': 1000, 'svc__gamma': 0.0001, 'svc__kernel': 'rbf', 'svc__random_state': 0} |
表示されているのは検証データに対して最も高い正解率と、その時のハイパーパラメータです。これで、交差検証によるハイパーパラメータの探索は終了です。最後にベストなハイパーパラメータを用いたモデルを使用して、テストデータの正解率を求めます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
#[IN] #accuracy_scoreのインポート from sklearn.metrics import accuracy_score #チューニング後のモデル best_svc = clf.best_estimator_ #テストデータに対する予測 pred = best_svc.predict(test_x) #正解率の表示 accuracy_score(test_y, pred) |
|
1 2 3 4 5 6 |
#[OUT] 0.9736842105263158 |
テストデータの正解率は交差検証時の正解率よりも少し下がっています。この理由はハイパーパラメータが検証データに対して最適化されているためであると考えられます。それでも0.97と非常に高い正解率で識別できています。他にも交差検証やチューニング方法を変更すれば違う結果が得られると思います。読者の皆様も様々な方法で本節のコードを改造してみてください。
コンペティションで使用される交差検証の実装
最後にコンペティションで使用される交差検証の実装を行います。今までとは違い、最初からtrain.csvとtest.csvに分かれているような状況を想定します。基本的な流れは同じですが、モデルを保存するという点が他とは異なります。kaggleなどのコンペティションに参加してみたい方は是非参考にしてください。
まずはデータセットを準備します。今回使用するデータセットはkaggleのチュートリアルで使用されるタイタニックのデータセットです。こちらのページからデータセットをダウンロードしていただき、Google Colab左の「ファイル」にアップロードしてください。まずはライブラリのインポートを行います。本節では必要なライブラリは全て先にインポートしています。
|
1 2 3 4 5 6 7 8 9 10 11 |
#[IN] #ライブラリのインポート import pandas as pd import numpy as np from sklearn.preprocessing import LabelEncoder from sklearn.model_selection import StratifiedKFold from sklearn.ensemble import RandomForestClassifier from sklearn.metrics import accuracy_score |
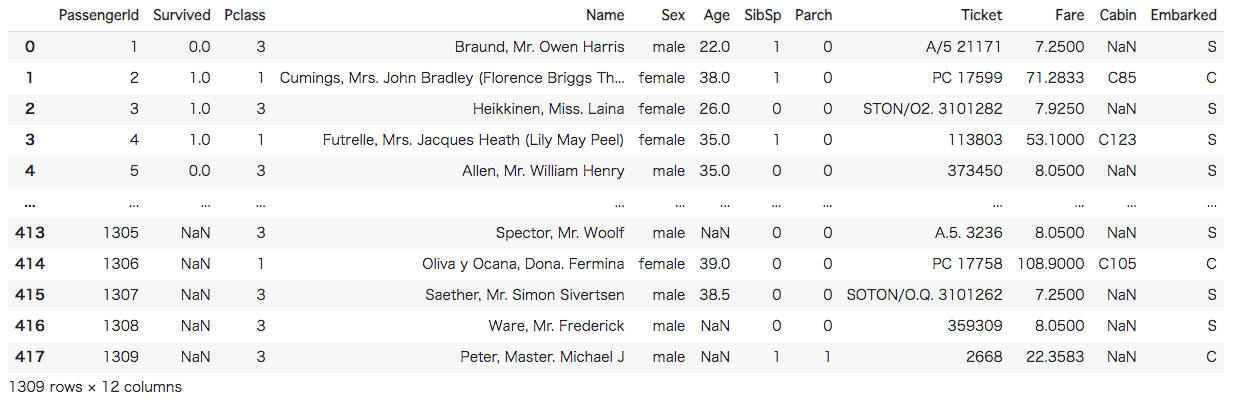
次に、データのロードを行います。各特徴量についての解説は以下の通りです。
- PassengerId – 乗客識別ユニークID
- Survived – 生存フラグ(0=死亡、1=生存)
- Pclass – チケットクラス
- Name – 乗客の名前
- Sex – 性別(male=男性、female=女性)
- Age – 年齢
- SibSp – タイタニックに同乗している兄弟/配偶者の数
- parch – タイタニックに同乗している親/子供の数
- ticket – チケット番号
- fare – 料金
- cabin – 客室番号
- Embarked – 出港地(タイタニックへ乗った港)
|
1 2 3 4 5 6 7 8 9 10 11 |
#[IN] #データのロード _train=pd.read_csv("train.csv") _test=pd.read_csv("test.csv") #データの結合 all = pd.concat([_train,_test]) all |
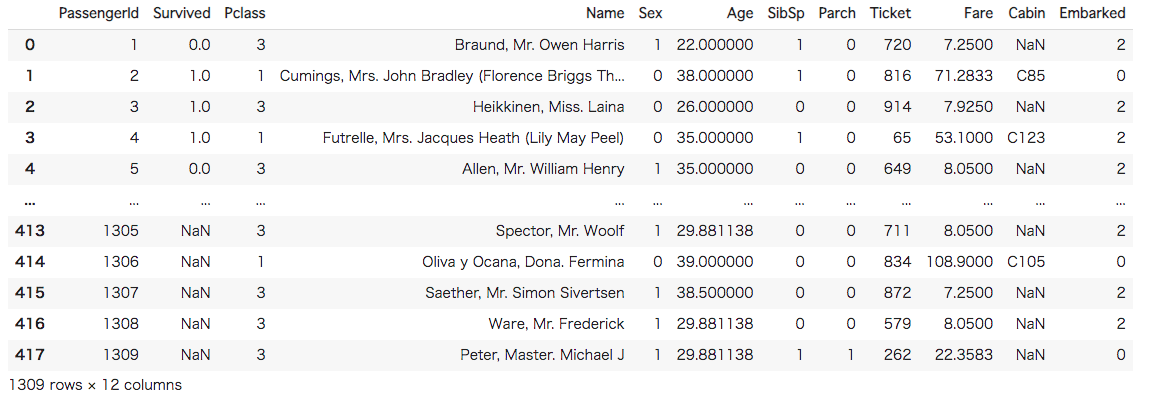
次にデータの前処理を行います。前処理の詳細な解説は省きますが、行なっているのは基本的な欠損値の補完です。文字列に関してはLabelEncoder()を使用して、数値に変換しています。また、前処理に使用可能なデータ数を増やすため、訓練データとテストデータを結合しています。これはコンペティションでのテクニックの1つです。しかし、リークを引き起こす可能性もあるので注意してください。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
#[IN] #欠損値の補完 all["Age"] = all["Age"].fillna(all["Age"].mean()) all["Fare"] = all["Fare"].fillna(all["Fare"].mean()) all["Embarked"] = all["Embarked"].fillna("S") #文字列を数値に変換 colum=["Sex","Ticket","Embarked"] for c in colum: le = LabelEncoder() le.fit(all[c]) all[c] = le.fit_transform(all[c]) all |
前処理が完了しました。結合していたデータを訓練データとテストデータに戻します。
|
1 2 3 4 5 6 7 |
#[IN] #訓練データとテストデータに戻す train = all[:len(_train)] test = all[len(_train):] |
次に、モデル構築に使用する特徴量を選択します。今回は、「Pclass」「Sex」「Age」「SibSp」「Parch」「Ticket」「Fare」「Embarked」です。また目的変数としてSurvivedも同様に切り取っておきます。
|
1 2 3 4 5 6 7 8 |
#[IN] #訓練に使用する特徴量 #DataFrameのままだと後ほど不便なため、valuesを使用してnumpyに変換 data = train[["Pclass","Sex","Age","SibSp","Parch","Ticket","Fare","Embarked"]].values label = train["Survived"] |
次に、交差検証を行います。前節までと同様に、fold数5でStratifiedKFold()を用います。これまではcross_val_sore()を用いてきましたが、本節で最初に紹介したfor文とsplit()を用いて実装します。こちらの書き方も知っておくと便利ですので、1行1行確認してください。モデルにはランダムフォレストを使用します。(参考:機械学習 チュートリアル 決定木とランダムフォレスト)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
#[IN]: #StratifiedKFold from sklearn.model_selection import StratifiedKFold #StratifiedKFoldの設定 skf = StratifiedKFold(n_splits = 5, shuffle = True, random_state = 0) #モデル保存用のリスト model_list=[] #交差検証 for train, val in skf.split(data, label): #訓練データと検証データに分割 train_x = data[train] val_x = data[val] train_y = label[train] val_y = label[val] #ランダムフォレストの定義 tree = RandomForestClassifier(random_state = 0) #学習 tree.fit(train_x, train_y) #予測 pred=tree.predict(val_x) #検証データに対する正解率を求める print(accuracy_score(val_y, pred)) #モデルを配列に保存 model_list.append(tree) |
|
1 2 3 4 5 6 7 8 9 10 |
#[OUT] 0.8435754189944135 0.848314606741573 0.848314606741573 0.8033707865168539 0.8426966292134831 |
検証用データに対する予測結果が5回出力されています。どれも0.84前後です。最後に、各foldで作成したモデルを使用して多数決による投票を行います。テストデータから訓練データと同じ特徴量を取得します。
|
1 2 3 4 5 6 |
#[IN]: #予測に使用する特徴量 test_data = test[["Pclass","Sex","Age","SibSp","Parch","Ticket","Fare","Embarked"]].values |
次に、テストデータを各foldで作成したモデルで予測します。各foldモデルの予測は、辞書型に保存します。最後に、辞書からDataFrameに変換を行うことで、各行がそれぞれのモデルが予測した値になっています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
#[IN]: #結果を辞書に保存 solution = {} #各モデルで予測 for i, model in enumerate(model_list): test_pred = model.predict(test_data) solution[str(i)+"_model"] = test_pred #辞書からDataFrameに変更 solution=pd.DataFrame(solution) solution |
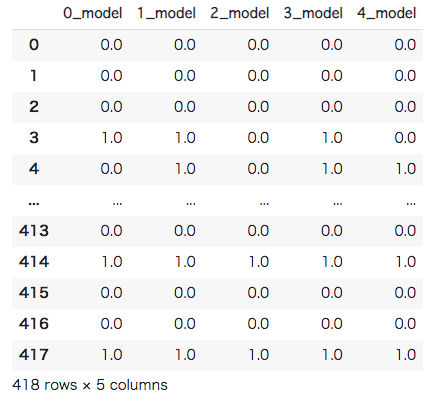
次に、多数決を取ります。DataFrameのmode()を使用することで、最頻値を取得することができます。デフォルトでは各列での適用ですので、axis=1に設定し、各行での適用に変更します。アンサンブルに関しては以下を参考にしてください。(参考:機械学習上級者は皆使ってる?!アンサンブル学習の仕組みと3つの種類について解説します)
|
1 2 3 4 5 6 |
#[IN] #最頻値を取得 solution_max = solution.mode(axis = 1).values |
最後に、サブミットするためのcsvファイルに書き出します。「ファイル」にsubmission.csvが保存されているはずです。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
#[IN] # PassengerIdを取得 PassengerId = np.array(test["PassengerId"]).astype(int) # my_prediction(予測データ)とPassengerIdをデータフレームへ落とし込む my_solution = pd.DataFrame(solution_max.astype(int), index=PassengerId, columns = ["Survived"]) # my_tree_one.csvとして書き出し my_solution.to_csv("submission.csv", index_label = ["PassengerId"]) |
submission.csvをこちらからサブミットしてみましょう。
正解率は0.77でした。他にも、交差検証の種類やモデルを変えて、サブミットのスコアが変化するか試してみてください。これでコンペティションで使用する交差検証の実装は完了になります。
まとめ
交差検証1つとっても様々な手法があり混乱された方もいるかもしれません。それだけ機械学習が難しいとも言えますが、筆者としてはそこに面白さがあるとも思います。是非、本稿を足場かけにして様々な実装にチャレンジしてみてください。
本稿を読んで、少しでも読者の皆様が機械学習に興味を持っていただけたら幸いです。
codexaでは機械学習初学者に向けたコースを複数提供しています。
また、すでに機械学習の基礎知識がある方に向けて、機械学習の様々な手法を詳しく解説したチュートリアルも公開しています。
是非、皆様のご受講をお待ちしております。

