
みなさんはデータ分析コンペティションに参加されたことはあるでしょうか。現在はkaggleやSIGNATEなど様々なコンペティションが開催されています。コンペティションにチャレンジされている方であれば、ほとんどの方がメダルに憧れを抱いていると思います。筆者もその1人です。
データ分析の作業割合は前処理がほとんどを占めると言われています。コンペティションでも、データセットに対してどれだけ有効な特徴量を作成できるかが順位に直結します。しかし、初学者の方にとってはこのハードルは高いものがあります。その理由は、有効な特徴量がデータセットによって異なり、多くの特徴量は分析者の経験から作成される場合が多いからです。
本稿では、特徴量生成の中でも中級レベルに位置するTarget Encoding(読み:ターゲット・エンコーディング)について解説します。コンペティションの上級者も使用する手法ですので、機械学習の脱初心者を目指す方や、コンペティションで上位を目指す方は確実に押さえておきましょう。
本編に入る前に
本稿のTarget Encodingは「特徴量作成」の中の一手法でしかありません。そのため、コンペティション自体を知らない方や、特徴量という言葉に馴染みのない方は先に基本的な内容を押さえておくことをお勧めします。データの読み込みから評価までの基本的な流れ(ベースライン)に関しては、本稿では省略させていただきます。
Target Encodingとは
Target Encoding(Target Mean Encoding)とはカテゴリカル(質的)データを数値に変換する方法の1つです。様々な手法があるのですが、Target Encodingの一番の特徴は目的変数を使用するという点です。筆者の言葉で誤解を恐れずに言うのであればTarget Encodingが生み出すのは「値が大きいほど目的変数の値も大きい確率が高い」特徴量ということになります。目的変数という答えを利用するTarget Encodingはデータセットによっては非常に強力な力を持ちます。
Target Encodingの変換を言葉にすると「目的変数の平均値を特徴量にする」です。外れ値などの状況によっては中央値などをとる場合もあるのですが、本稿では平均値を使用します。イメージとしては図1のようになります。本稿では可能な限り理解しやすいよう、0と1の2値分類を想定しています。(参考:外れ値とは?Pythonを使用して外れ値の検出方法を実装してみよう(全コード公開中))
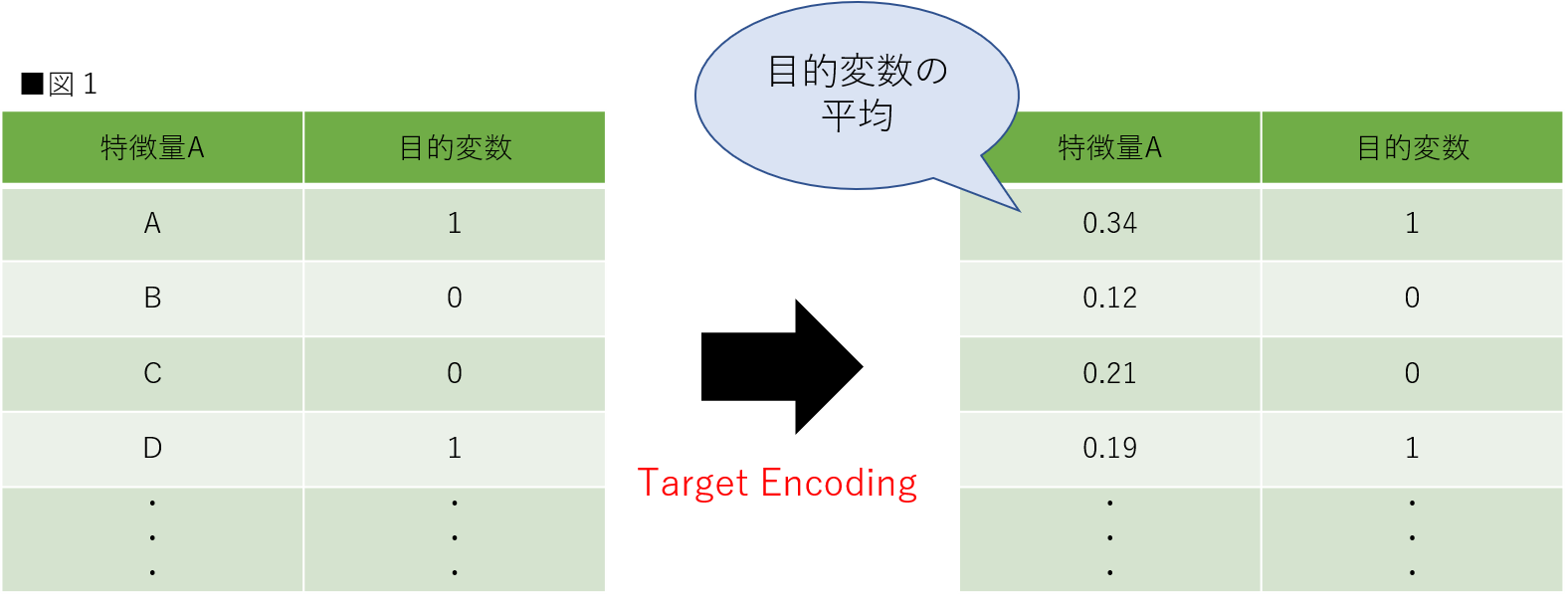
Target Encodingの基本はこれだけです。図1の場合だと、特徴量Aは目的変数が1をとる確率が他に比べて高いということになります。ここまでは難しいと感じない方がほとんどだと思います。しかしTarget Encodingが難しいと言われる所以は、この「訓練データの目的変数の平均」をどのようにして取得するかという点にあります。取得方法については後述します。
リークとは?
Target Encodingを理解するために必須な「リーク」と呼ばれる事象について解説します。リーク(Leakage)とはデータ分析の界隈で比較的よく使用される言葉です。kaggleの公式では「リークとは、訓練データに予期しない追加情報が存在することで、モデルまたは機械学習アルゴリズムが現実的でない優れた予測を行うことを可能にすること」とあります。複数のタイプがあるのですが、Target Encodingでは訓練データにおいて目的変数の情報が漏れる可能性があります。(参考:kaggle公式:What is Leakage)
リークを起こすと訓練データに対しての予測は非常に高い評価になるのに対し、テストデータの評価が下がることがあります。これはモデルが訓練データに用意されている目的変数の情報から、強く影響を受けてしまったことによりモデルの汎用性が下がる場合に起こる現象です。言葉だと少し難しいと思いますので、詳細は実装も含めて後述します。
テストデータへの適応
訓練データには目的変数が存在しますが、テストデータには存在しません。そのため、テストデータのカテゴリカル変数は訓練データの値を用いてTarget Encodingを行うことになります。テストデータへの適応は非常にシンプルです。カテゴリカル変数ごとに訓練データの目的変数の平均をあたはめるだけで完了します。

Target Encodingの種類
先ほど少し触れましたが、Target Encodingには「目的変数の平均」の取り方によっていくつか種類があります。リークを起こしやすいものから起こしにくいものまで存在するので、しっかりと理解して扱えるようにする必要があります。本節では仮のデータセットを作成し、ある程度わかりやすい数値でTarget Encodingを実装していきます。解説では数値がどのように変化しているのか1つ1つ追っていきます。本稿で解説するのは以下の3つです。
- Greedy Target Encoding
- Leave-one-out Target Encoding
- Holdout Targer Encoding
実装はGoogle Colabを用いて実装していきます。ライブラリをそのままインポートすれば同じように実装可能です。是非、ご自身でも実装してみてください。Google Colabを使用したことがない方は下記の記事を参考にしてください。(参考:Google Colabの知っておくべき使い方 – Google Colaboratoryのメリット・デメリットや基本操作のまとめ)
Greedy Target Enoding
最初は、Greedy Target Encoding(Greedy Target Statistic)です。この方法は単純にデータセット全体から目的変数の平均を取得します。しかし、この方法はリークが起こる可能性があります。図2は特徴量の1つに焦点を当てた時のGreedy Target Encodingです。リークが起こる際の理由に関しては実装コードを確認した上で解説します。
まずは仮のデータセットを用意します。pandsをインポートし、DataFrameでデータセットを作成します。仮のデータセットは10行×3列です。目的変数以外の2列に関しては文字列で作成します。このDataFrameを用いて3種類のTarget Encodingの実装を行います。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
#[IN]: #ライブラリのインポート import pandas as pd import warnings warnings.filterwarnings('ignore') #DataFrameで仮の訓練データセットを作成(10×3) df = pd.DataFrame({ "column1" : ["A","A","A","A","A","B","B","B","B","B"], "column2" : ["C","D","D","D","D","D","D","D","E","E"], "target" : [1, 0, 0, 1, 0, 0, 1, 1, 0, 1] }) #先頭から10行を表示 df.head(10) |
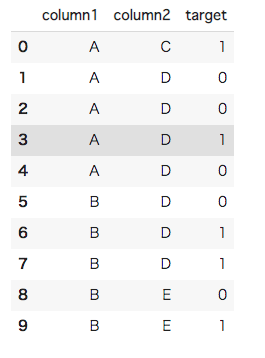
仮のデータセットが作成できました。targetの列が今回の目的変数となります。column1とcolumn2は文字列ですので、数値に変換してあげる必要があります。そこで先ほど解説したGreedy Target Encodingを用いてcolumn1とcolumn2を数値に変換します。まずは各特徴量ごとの目的変数の平均をとります。column1であればAとB、column2であればCとDとEです。
|
1 2 3 4 5 6 7 8 9 10 |
#[IN]: #各特徴量ごとの目的変数の平均をとる col1_means = df.groupby("column1")["target"].mean() col2_means = df.groupby("column2")["target"].mean() print(col1_means) print(col2_means) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
#[OUT]: column1 A 0.4 B 0.6 Name: target, dtype: float64 column2 C 1.000000 D 0.428571 E 0.500000 Name: target, dtype: float64 |
各特徴量ごとの目的変数の平均を取得できました。これを特徴量として新たな列に追加します。本来であれば文字列自体を置き換えますが、本節では見やすいように新たな列を作成し、Greedy Target Encodingを適用した値を入れたいと思います。
|
1 2 3 4 5 6 7 8 |
#[IN]: #目的変数の平均を特徴量として新たな列に加える df["column1_target"] = df["column1"].map(col1_means) df["column2_target"] = df["column2"].map(col2_means) df |
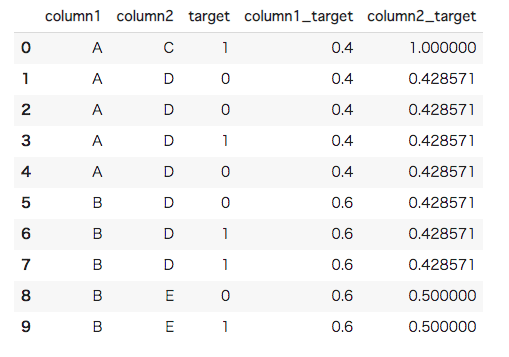
Greedy Target Encodingが完了しました。簡単に実装できましたが、今回の実装ではリークが起こっています。1行目を見てください。目的変数(target)と特徴量(column2_target)の値が同じです。Greedy Target Encodingでは自分自身の目的変数も計算に加えてしまっているため、カテゴリカル変数の数が1つだと特徴量の値がそのまま目的変数になっています。これではテストデータが与えられた時に正しく評価することは厳しく、正しい特徴量生成とは言えません。場合によってはSmoothingなどのテクニックを使ってリークを起こしにくくすることもできます。Smoothingに関しては後述します。
Leave-one-out Target Encoding
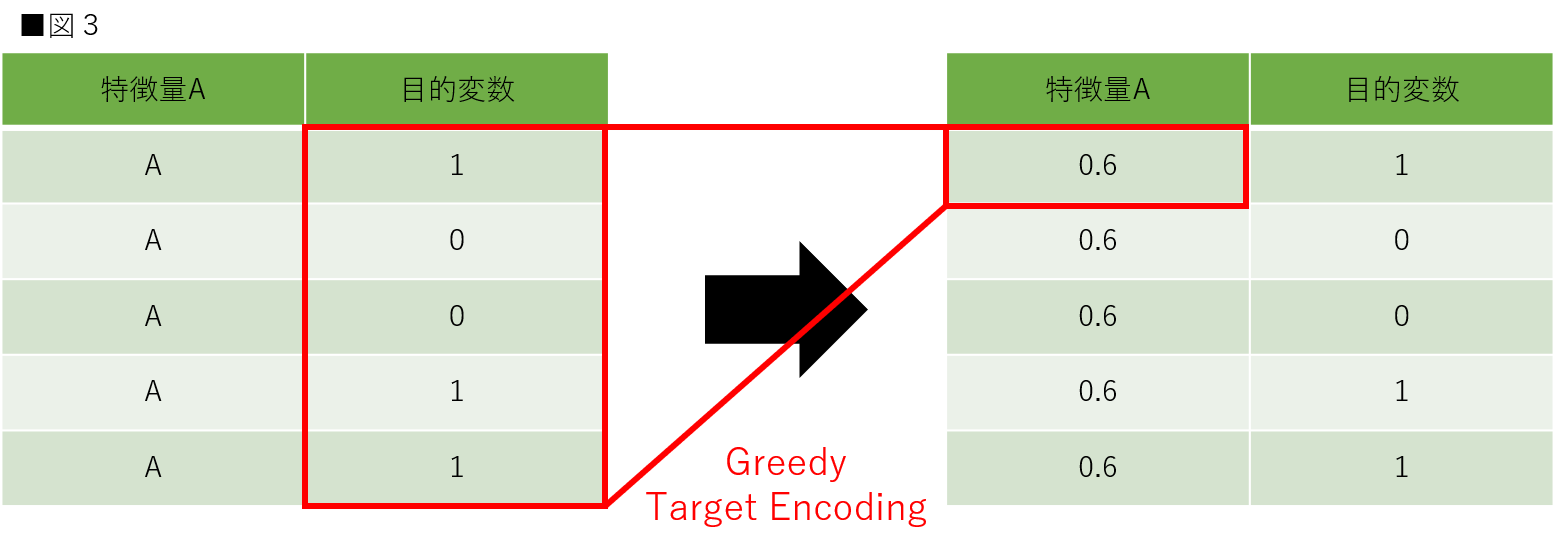
次に、Leave-one-out Target Encoding(Leave-one-out Target Statistic)です。この方法は自身が持つ目的変数以外の目的変数の平均を取得します。この方法もリークが起こる可能性があるので注意が必要です。図3は特徴量の1つに焦点を当てた時のLeave-one-out Target Encodingです。こちらも、リークが起こる際の理由に関しては、実装コードを確認した上で解説します。
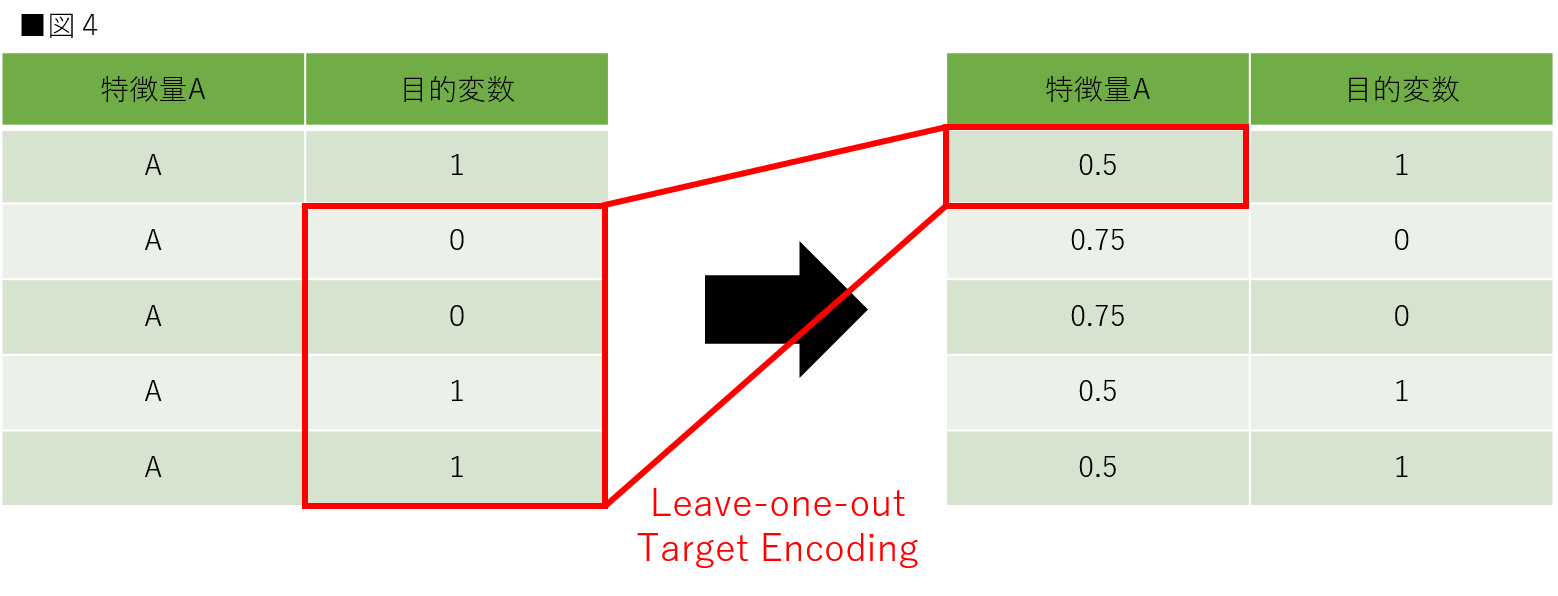
Greedy Target Encodingと同様のデータセットを用意します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
#[IN]: #ライブラリのインポート import pandas as pd import warnings warnings.filterwarnings('ignore') #DataFrameで仮のデータセットを作成(10×3) df = pd.DataFrame({ "column1" : ["A","A","A","A","A","B","B","B","B","B"], "column2" : ["C","D","D","D","D","D","D","D","E","E"], "target" : [1, 0, 0, 1, 0, 0, 1, 1, 0, 1] }) #先頭から10行を表示 df.head(10) |
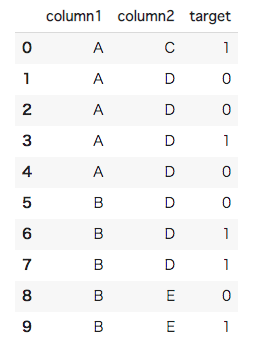
Greedy Target Encodingでは目的変数の平均を取得するだけで実装できましたが、Leave-one-out Target Encodingでは自身の値は含まないため、実装が少し複雑になります。まずは特徴毎のカウント数と目的変数の合計を取得します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
#[IN]: #column1の特徴毎のカウント数を取得する col1_count = df.groupby("column1")["column1"].count() #column1の特徴毎の目的変数の合計を取得する col1_sum = df.groupby("column1")["target"].sum() print("column1のカウント数↓" + str(col1_count)) print("column1の目的変数の合計↓" + str(col1_sum)) #column2の特徴毎のカウント数を取得する col2_count = df.groupby("column2")["column2"].count() #column2の特徴毎の目的変数の合計を取得する col2_sum = df.groupby("column2")["target"].sum() print("column2のカウント数↓" + str(col2_count)) print("column2の目的変数の合計↓" + str(col2_sum)) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
#[OUT]: column1のカウント数↓column1 A 5 B 5 Name: column1, dtype: int64 column1の目的変数の合計↓column1 A 2 B 3 Name: target, dtype: int64 column2のカウント数↓column2 C 1 D 7 E 2 Name: column2, dtype: int64 column2の目的変数の合計↓column2 C 1 D 3 E 1 Name: target, dtype: int64 |
次に、関数を定義します。DataFrameのapplyメソッドは、行または列毎に処理を行うことができます。また、その処理は関数で定義することができます。今回定義するleave_te関数は、先に用意した特徴毎の目的変数の合計から自身の目的変数を引き、特徴毎のカウント数から1を引いています。その値から作成した平均値をtarget_encodingの値として取得しています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
#[IN]: #特徴毎の合計とカウント数から自身の値を引く関数を作成 def leave_te(row, count, sum): #特徴の名前を取得 col = count.name #特徴の目的変数の合計から自身の目的変数を引く x = sum[row[col]] - row["target"] #特徴のカウント数から1(自身のカウント数)を引く y = count[row[col]] - 1 #平均を返す return x / y #leave_te関数を適用する df["column1_target"] = df.apply(leave_te, args = (col1_count, col1_sum), axis = 1) df["column2_target"] = df.apply(leave_te, args = (col2_count, col2_sum), axis = 1) df |
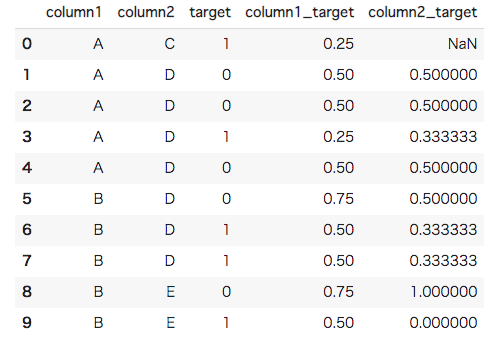
Leave-one-out Target Encodingが実装できました。しかし、今回もリークが発生しています。まず一番分かりやすいのはcolumn2_targetの8、9行目です。column2_targetの値が目的変数と逆の値を取っていることが分かると思います。これは自身の目的変数を計算に含まなかったことにより、逆に強く影響が生まれてしまっている例です。
column1_targetの0~4行目も見てみます。これらは一見すると問題なさそうですが、図5のような問題が発生しています。

図5に示されているように複数個のカテゴリカル変数があったとしても、Leave-one-out Target Encodingによって目的変数がわかってしまう状態になっています。テストデータでは訓練データ全体の平均が与えられるわけですので、これらの値に適合したモデルでは高い評価を出すことができないと予想できます。
Holdout Target Encoding
次に、Holdout Target Encoding(Holdout Target Statistic)です。この方法は訓練データを分割し、別ブロックの目的変数の平均を使用して自身のブロックのカテゴリカル変数を変換します。本稿で紹介するTarget Encodingの中ではもっとも一般的に知られている方法です。絶対ではありませんが、この方法を使用するとリークを起こりにくくすることができます。図6は図特徴量の1つに焦点を当てた時のHoldout Target Encodingです。

図6を見ると、自身のブロック以外の目的変数の平均を取得していることがわかると思います。それではHoldout Target Encodingを実装していきます。今までと同様にデータセットの準備から始めます。配列を使用するためにnumpyと、分割を行うためにscikit-learnのKFoldを追加でインポートしています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
#[IN]: #ライブラリのインポート import pandas as pd import numpy as np from sklearn.model_selection import KFold import warnings warnings.filterwarnings('ignore') #DataFrameで仮のデータセットを作成(10×3) df = pd.DataFrame({ "column1" : ["A","A","A","A","A","B","B","B","B","B"], "column2" : ["C","D","D","D","D","D","D","D","E","E"], "target" : [1, 0, 0, 1, 0, 0, 1, 1, 0, 1] }) df |
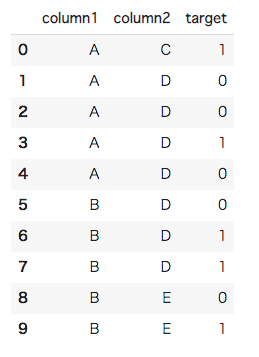
ここからがHoldout Target Encodingの実装の肝です。詳細な解説はコード内にも記載しますが、重要なのはKfoldでの分割です。今回はデータ数が10と非常に少ないため分割を3で行なっていますが、通常のデータセットであればもう少し分割数は増やすことをお勧めします。実際はデータセットによるため、確実な分割数を述べることはできませんが、筆者の感覚ではいつも5分割程度に設定しています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
#[IN]: #Holdout Target Encodingの関数定義 def Holdout_te(df,column,target): #Kfoldの定義 kf = KFold(n_splits = 3, shuffle = True, random_state = 2) #仮の箱を用意 box = np.zeros(len(df)) #Nanで埋めておく box[:] = np.nan #繰り返しながらTarget Encodingを行う for idx1, idx2 in kf.split(df): #2分割 train = df.iloc[idx1] val = df[column].iloc[idx2] #グループごとの平均を計算 mean = train.groupby(column)[target].mean() #boxにカテゴリ毎の平均を入れる for i,m in mean.iteritems(): for v in val.index: if val[v] == i: box[v] = m #新たな列に挿入 df[column + "_target"] = box return df df=Holdout_te(df, "column1", "target") df=Holdout_te(df, "column2", "target") df |
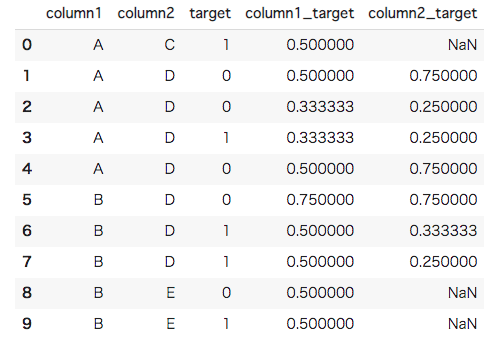
Holdout Target Encodingが実装できました。結果を見ていただければわかるようにどの値も目的変数を一意には説明していません。このようにHoldout Target Encodingを使用することでリークを起こりにくくすることができます。
分割の仕方によっては、相手ブロックに計算を行うための変数が存在せず、NaNが発生する場合があります。この欠損部分に関しても埋め方は様々ですが、一旦同じ特徴量の平均値で埋めておきます。特徴量などでの欠損値の処理方法に関しては以下の記事も参考にしてみてください。(参考:欠損値とは?Pythonを使って欠損値の処理方法と実装を徹底解説【機械学習 入門編】)
|
1 2 3 4 5 6 7 |
#[IN]: #欠損を平均値で埋める df["column2_target"] = df["column2_target"].fillna(df["column2_target"].mean()) df |
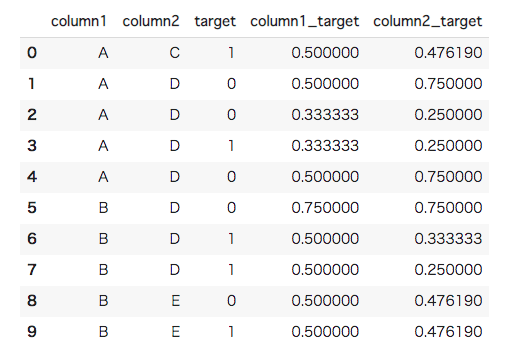
ここまで、Target Encodingについて様々な方法を解説してきました。ここまで押さえれば基本的なTarget Encodingを扱えるようになると思います。本稿では2値分類を例に挙げていますが、これが多クラスの場合もほぼ同様です。それぞれのクラスであるか否かを0と1の2値分類で考えます。回帰問題の場合も目的変数の平均を取得するのが一般的です。
Smoothing
SmooothingとはTarget Encodingのリークを防ぐためのテクニックを指します。リークが起こりにくいと解説したHoldout Target Encodingでも、特徴の数が少ないなどの場合にはうまく変換できないという問題があります。コンペティションで上位に入る方の中には、こういった問題を解決するとともに、さらにリークを防ぐ工夫をされている方もいます。以下に記載したkaggleのnotebookにはTarget Encoding時に重みづけを行なったり、ノイズを付加するコードが記載されています。初心者の方がここまで実装するのは難しいかもしれませんが、次のステップとしてこういった上位の方のコードを参考にすることはとてもお勧めです。(参考:Python target encoding for categorical features)
タイタニックでTarget Encodingの実装
本節では実際のデータセットを用いて、Target Encodingの実装を行なっていきます。今後、コンペティションなどに参加される際は、本節の実装を参考にしていただけたら幸いです。Target Encodingの方法としてはHoldout Target Encodingを用います。なお、今回はTarget Encodingの実装に重きをおいているので、適切なカテゴリカル変数を見つけ出す手順は省いています。特徴選択に関しては以下を参考にしてください。まずは必要なライブラリをインポートします。(参考:特徴選択とは?機械学習の予測精度を改善させる必殺技「特徴選択」を理解しよう)
|
1 2 3 4 5 6 7 8 9 10 11 12 |
#[IN]: #ライブラリの読み込み import pandas as pd import numpy as np import seaborn as sns from sklearn.model_selection import train_test_split from sklearn.model_selection import KFold import warnings warnings.filterwarnings('ignore') |
データセットにはkaggleのチュートリアルで最も有名なTitanicのデータセットを利用します。Titanicのデータセットはseaborn上に用意されているので、今回はそちらを利用します。kaggle上で提供されるTitanicとseaborn上のTitanicのデータセットは若干の違いがあるため、注意してください。
Titanicコンペティションの解説はAIマガジンの【Kaggle初心者入門編】タイタニック号で生き残るのは誰?でも紹介しています。今回は投稿は行わないため、投稿まで行いたい方はこの記事を参考に挑戦してみて下さい。kaggleのタイタニックのページは以下になります。(参考:Titanic – Machine Learning from Disaster)
|
1 2 3 4 5 6 7 |
#[IN]: #titanicデータセットを読み込んで、一部を表示 df = sns.load_dataset('titanic') df.head() |
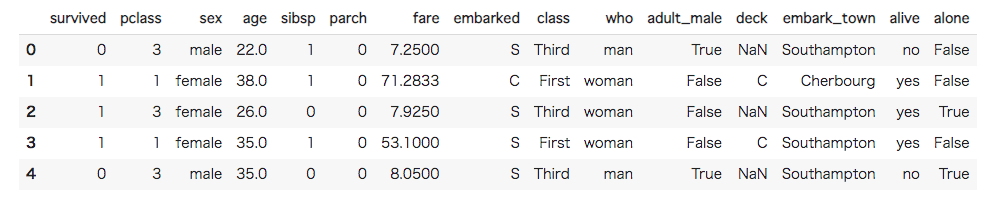
データセットの最初5行が表示されました。今回はTarget Encodingの実装が目的なため、データセットの中からカテゴリカル変数であるものを抜き出します。今回はsurvived(目的変数)、sex(性別)とembark_town(出航地名)を使用します。
|
1 2 3 4 5 6 7 |
#[IN]: #survived(目的変数)、sex(性別)、embark_town(出航地名)を抜き出して表示 df = df[["survived", "sex", "embark_town"]] df |
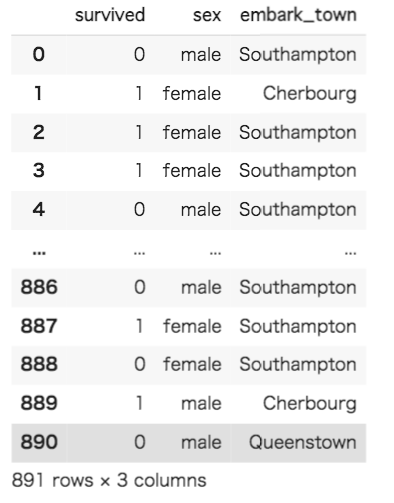
survived(目的変数)、sex(性別)、embark_town(出航地名)を抜き出すことができました。念のため、欠損値を確認して、存在していれば削除してしまいます。
|
1 2 3 4 5 6 |
#[IN]: #欠損値の有無を確認 df.isnull().sum() |
|
1 2 3 4 5 6 7 8 |
#[OUT]: survived 0 sex 0 embark_town 2 dtype: int64 |
|
1 2 3 4 5 6 7 |
#[IN]: #欠損値を含む行を削除して、表示 df = df.dropna() df |
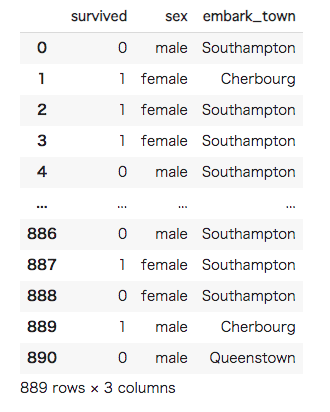
データセットを訓練用データとテスト用データに分けます。通常テストデータは目的変数が分からない状態で存在することがほとんどですが、今回はテストデータを別で用意していないので、データセットから分割したデータをテストデータとして扱います。テストデータの割合は2割とし、目的変数の割合が等しくなるように分割します。
|
1 2 3 4 5 6 7 8 9 |
#[IN]: #目的変数の割合が等しくなるようにデータセットを分割 train, test = train_test_split(df, test_size = 0.2, shuffle = True, stratify = df["survived"], random_state = 0) print("訓練用データは" + str(len(train))) print("テスト用データは" + str(len(test))) |
|
1 2 3 4 5 6 |
#[OUT]: 訓練用データは711 テスト用データは178 |
訓練データが711行、テストデータが178行の2つのデータに分けることができました。それではこれらのデータを用いてHoldout Target Encodingを行なっていきます。前節でも使用した関数を定義します。今回はデータ数もある程度存在するのでsplit数を5に設定しています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
#[IN]: #Holdout Target Encodingの関数定義 def Holdout_te(df,column,target): #Kfoldの定義 kf = KFold(n_splits = 5, shuffle = True, random_state = 2) #仮の箱を用意 box = np.zeros(len(df)) #Nanで埋めておく box[:] = np.nan #繰り返しながらTarget Encodingを行う for idx1, idx2 in kf.split(df): #2分割 train = df.iloc[idx1] val = df[column].iloc[idx2] #グループごとの平均を計算 mean = train.groupby(column)[target].mean() #boxにカテゴリ毎の平均を入れる for i,m in mean.iteritems(): for v in val.index: if val[v] == i: box[v] = m #新たな列に挿入 df[column + "_target"] = box return df #indexを振り直す train = train.reset_index().drop("index", axis = 1) #Holdout Target Encodingの実装 train = Holdout_te(train, "sex", "survived") train = Holdout_te(train, "embark_town", "survived") train |
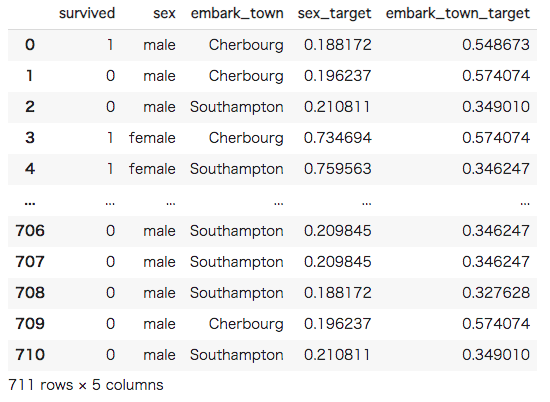
訓練データのHoldout Target Encodingが完了しました。次にテストデータのTarget Enodingを行います。こちらは非常に単純で、訓練データの目的変数の平均を取得するだけで問題ありません。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
#[IN]: #訓練用データのsexごとの目的変数の平均を取得 column1 = train.groupby("sex")["survived"].mean() #訓練用データのembark_townごとの目的変数の平均を取得 column2 = train.groupby("embark_town")["survived"].mean() #テストデータへの適用 test["sex_target"] = test["sex"].map(column1) test["embark_town_target"] = test["embark_town"].map(column2) test |

テストデータに対してもTarget Encodingを適用することができました。本節の最初でも述べたように「sex」と「embark_town」に対してTarget Encodingを適用することが正しいかどうかはテストデータの精度が向上し、リークしていないことを確認できた時点で初めて評価できます。この辺りのさじ加減は非常に難しいですが、まずは使ってみることが大切です。データ分析の前処理の仕方は山ほどありますので、試しながら自身の引き出しを増やしていきましょう。
まとめ
いかがでしたでしょうか。現在、データ分析コンペティションは様々な場所で開かれています。是非、調べて参加してみてください。本稿で取り上げた手法が、少しでも皆様のお役に立てたら幸いです。
codexaでは機械学習初学者に向けたコースを複数提供しています。
また、すでに機械学習の基礎知識がある方に向けて、機械学習の様々な手法を詳しく解説したチュートリアルも公開しています。
是非、皆様のご受講をお待ちしております。
