
Kaggleなどのデータ分析競技を取り組んでいる方であれば、LightGBM(読み:ライト・ジービーエム)に触れたことがある方も多いと思います。近年、XGBoostと並んでKaggleの上位ランカーがこぞって使うLightGBMの基本的な使い方や仕組み、さらにXGBoostとの違いについて解説をします。
前半はLightGBMの概要に加えて仕組みを解説します。後半はLightGBMの基本操作を学ぶため、江戸時代などに古文書で使われた「くずし字」の画像認識の実装を行います。画像認識の経験がない方は「はじめての画像認識コース」をお勧めします。
記事概要
・LightGBMによる画像認識の全実装コード収録
・完読/実装までの所要時間 15〜30分
・ブラウザのみで実行可能(Google Colab対応)
本稿では数式を用いた厳密なLightGBMの解説は行いません。初心者の方でも直感的に理解しやすいように解説します。しっかりと学びたい方はLightGBMの論文をお勧めします。
LightGBM: A Highly Efficient Gradient Boosting Decision Tree
この記事の目次
LightGBMとは
LightGBMとは決定木アルゴリズムに基づいた勾配ブースティング(Gradient Boosting)の機械学習フレームワークです。LightGBMは米マイクロソフト社がスポンサーをしています。(勾配ブースティングの仕組みについては後述します)
勾配ブースティングのフレームワークといえばXGBoostが有名です。両方とも勾配ブースティングのフレームワークですが、細かい部分で実装が異なります。XGBoostのリリースは2014年でしたが、LightGBMは後発で2016年にリリースされました。
機械学習のコミュニティで世界的に有名なKDnuggetsによると、Kaggleで上位ランキングを取った半数以上もの勝者が「勾配ブースティング」を使った実績があると報じています。(参照:こちら)。それほど勾配ブースティングは注目度の高い機械学習手法であり、今日のデータ分析競技には必須とも言える存在なのです。
LightGBMの仕組み
LightGBMの仕組みを理解するため、本稿では「決定木」、「アンサンブル学習」、「勾配ブースティング」を順に紐解いていきましょう。
決定木
LightGBMは決定木の勾配ブースティングのフレームワークです。つまり決定木の理解を無くして、LightGBMの仕組みを語れません。
決定木は英語で「Decision Tree(ディシジョン・ツリー)」と呼ばれており、構造はシンプルですが人気の高い「教師あり学習」の手法の一つです。
簡単なデータを使って決定木を紐解きましょう。図1は猫と犬の体重、尻尾の長さ、全長を表すデータです。それぞれ分類のクラス(猫 or 犬)が与えられています。
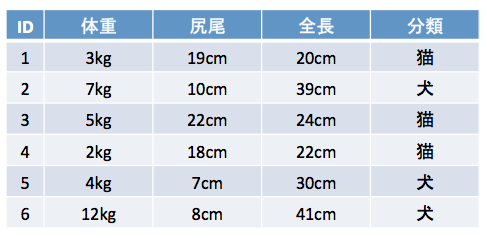
図 1
6匹の身体データを特徴量として、決定木を使って分類クラスを推測する流れを考えてみましょう。決定木では図2のように、アルゴリズムを使い特徴量を基準にデータを分岐して推測を行います。
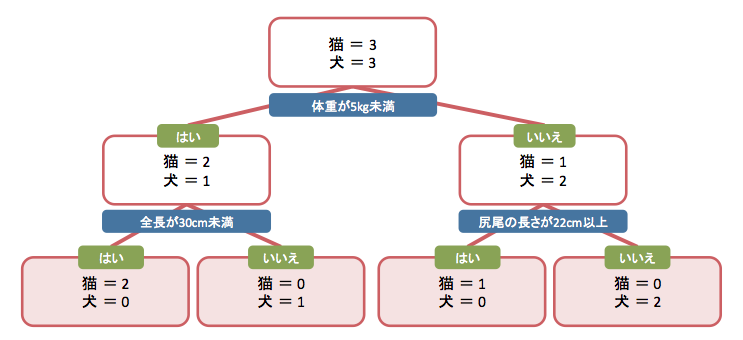
図 2
図2のチャートと図1のデータを見比べてみください。図2の最上部のボックス(これはノードと呼ばれます)には猫3匹、犬3匹の全固体が入っています。最初の分岐は「体重が5kg未満」とあり、分岐条件に応じて2層目は「はい」と「いいえ」で分岐しています。さらに三層目は「全長が30cm未満」と「尻尾の長さが22cm以上」の条件で分岐しています。
このように、決定木では条件に基づいて分岐を行い、ターゲットのクラスへ分類します。実際に決定木を用いると、図2のようなチャートを生成することもできます。推測結果を明確かつ容易に説明することができるのは決定木の大きな特徴の一つです。
決定木のより詳細は「実践チュートリアル 決定木とランダムフォレスト」をご参照ください。
アンサンブル学習
続いて「アンサンブル学習」を紐解きましょう。前述した通りLightGBMは決定木の勾配ブースティングのフレームワークです。勾配ブースティングはアンサンブル学習の「ブースティング」の手法を使います。
アンサンブル学習(Ensemble Learning)は、複数のモデル(学習器)を融合させて1つの学習モデルを生成する手法です。シンプルに考えると、アンサンブル学習は1人で問題を解くより、複数人で意見を出し合って知識を補い合いながら解く方が正答率が上がるのと考え方は同じです。(参照:アンサンブル学習とは?)
アンサンブル学習は大きく3つの手法に別けることが可能です。それが「バギング」「ブースティング」「スタッキング」と呼ばれる手法です。
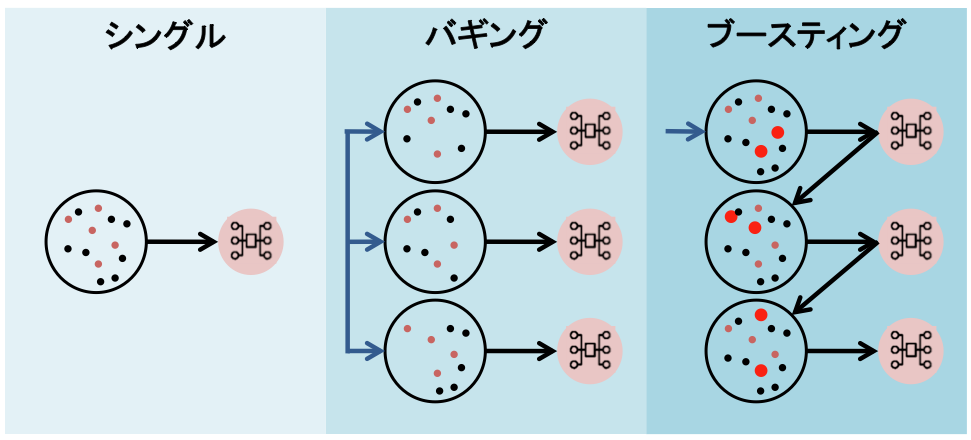
図 3
図3はアンサンブル学習の「バギング」と「ブースティング」の訓練課程を簡易的に図式化したものです。バギングはそれぞれのモデルを並列的に学習を行います。対して、ブースティングは前の弱学習器の結果を次の学習データに反映させるという大きな特徴があります。
決定木を弱学習器として「バギング」によるアンサンブル学習の手法を「ランダムフォレスト」と呼びます。対して、勾配ブースティングは決定木を弱学習器として「ブースティング」の手法を用いてアンサンブル学習を行います。
勾配ブースティング
前述した通り勾配ブースティングは複数の弱学習器(LightGBMの場合は決定木)を一つにまとめるアンサンブル学習の「ブースティング」を用いた手法です。
ブースティングは前の弱学習器の結果を、次の学習データに反映をさせます。では、どのように反映させるのでしょうか?ここにブースティングの工夫があります。
仮に最初に訓練を行う決定木を1号、次に訓練を行う決定木を2号としましょう。まずは決定木(1号)でモデル訓練を行い推測結果を評価します。決定木(1号)の推測結果と実際の値の「誤差」を訓練データとして、決定木(2号)の訓練を行います。N号の決定木はN-1号の決定木の誤差(Residuals)を学習するわけです。
このように勾配ブースティングはそれぞれの弱学習器の誤差を学習することに最大の特徴があります。XGBoostもLightGBMもこの「勾配ブースティング」を扱いやすくまとめたフレームワークです。
「実践 XGBoost入門コース」では勾配ブースティングをPythonを使ってスクラッチで実装を行う実習も含まれています。勾配ブースティングをより深く理解したい方は、是非ご受講をご検討ください。
LightGBMは大規模なデータセットに対して計算コストを極力抑える工夫が施されています。この工夫により、多くのケースで他の機械学習手法と比較しても短時間でモデル訓練が行えます。その工夫とは勾配ブースティングで使われる「決定木の扱い方」にあります。
勾配ブースティングの訓練過程において、決定木の扱い方には「Level-Wise」と「Leaf-Wise」の2つの手法が存在します。図4をご覧ください。「Level-wise」とは決定木のlevel(つまり層)が成長していきます。決定木を訓練する場合、こちらが一般的です。
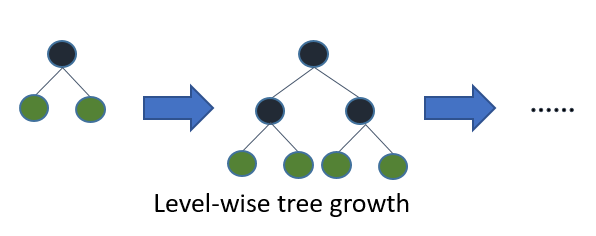
図4 (引用: LightGBM 公式ドキュメント)
対して「Leaf-wise」では決定木のleaf(つまり葉)に準じて成長していきます。LightGBMはこの「Leaf-wise」という手法を採用しています。従来の「Level-wise」に比べてLightGBMが採用している「Leaf-wise」は訓練時間が短くなる傾向にあります。
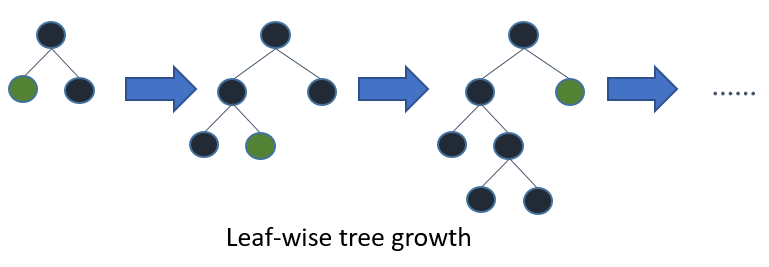
図4 (引用: LightGBM 公式ドキュメント)
また決定木モデルの訓練において、一つの課題として最適な枝分かれのポイントを探すための計算コストがあります。従来の決定木では厳密な枝分かれポイントを探すため、全てのデータポイントを読み込む必要がありました。
この課題を解決する工夫がLIghtGBMには施されています。LigtGBMでは訓練データの特徴量を階級に分けてヒストグラム化することで、意図的に厳密な枝分かれを探さず大規模なデータセットに対しても計算コストを抑えることが可能なのです。
LightGBMの特徴
Kaggleなどで人気のLightGBMですが、他の機械学習手法と比較して主に5つの特徴があります。仕組みの項でも解説した通りLightGBMはヒストグラムをベースとしたアルゴリズムを採用しています。特徴量の計量値(Continuous Values)は階級毎に処理されるため、多くのケースで下記の傾向が見てとれます。(注:全てのデータ・状況に当てはまるものではありません)
モデル訓練に掛かる時間が短いLightGBMが「Light(軽い)」と言われる所以です。
メモリ効率が高い計量値をヒストグラムとして扱うのでメモリを抑えることが可能です。
推測精度が高い同じデータセットに対して他のブースティングの機械学習アルゴリズムと比較した場合、Leaf-Wiseのため推測精度が改善する傾向にあります。これはLeaf-Wiseの方がLevel-Wiseと比較して、より複雑な決定木となるためで。
過学習しやすいLeaf-wiseは決定木が複雑になります。つまり、決定木の構造をハイパーパラメータで適切に調整しないと過学習(Overfitting)となる可能性が高いです。
大規模なデータセットも訓練可能全く同等の大規模な訓練データを使った場合、XGBoostよりもLightGBMはモデル訓練時間が大幅に短い傾向にあります。またサポートベクターマシンなど一部の機械学習手法はその構造上、大規模データに適していません。対してLightGBMは大規模データに適している手法と言えます。
LightGBMとXGBoostの比較
XGBoostとLigtGBMは決定木の勾配ブースティングのフレームワークです。細かい実装方法に違いはありますが、大枠ではほとんど同種のフレームワークと考えても問題ありません。
LightGBMは計量値(Continuous Values)をヒストグラムとして扱うため高速化すると解説しました。XGBoostにはこの実装は元々はありませんでしたが、現在はパラメータtree_method = histとすることで、ヒストグラムベースのアルゴリズムを採用することも可能です。
勾配ブースティングは実用性が高いため、XGBoostとLightGBMの比較は研究対象にもなっています。2018年9月に発表された「Benchmarking and Optimization of Gradient Boosting Decision Tree Algorithms(意訳:決定木の勾配ブースティングアルゴリズムの測定と最適化)」があります。XGBoost、LightGBM、Catboostの検証を行なった結果、全ての状況で明確に優れていると言える手法は無いと結論付けています。
LightGBMのスポンサーをしている米Microsoft社もLightGBMとXGBoostの興味深い調査の結果をブログの記事として投稿しています。

サイズの異なる様々なデータセットを使いXGBoostとLightGBMの訓練時間を比較した表です。これは2017年7月にMicrosoft社により検証された結果です。CPU、GPUそれぞれの訓練時間の結果を比較したところ、LightGBMはXGBoostよりも訓練時間が短い傾向にあるのが見てとれます。
上記の結果ではLightGBMの訓練時間が短いと示されましたが、決してXGBoostよりも優れていると断言するものではありません。扱うデータの特性により、柔軟に使い分けるのが最も重要です。
次の項から実際にLightGBMを使って画像認識を行なってみましょう!
1. LightGBMのインストール
LightGBMのインストールには様々な方法があります。まずは手軽にLightGBMを試してみたい方はGoogle Colabをお勧めいたします。(本稿に記載する全コードはGoogle Colabの環境に準じて記載します)
Google Colabとは、教育や研究機関へ機械学習の普及を目的としたGoogleの研究プロジェクトの一つでです。Jupyter Notebookを必要最低限の労力とコストで利用でき、ブラウザとインターネットがあれば今すぐにでも機械学習のプロジェクトを進めることが可能なサービスです。
Google Colabの使い方はこちらの記事をご参照ください。Googleの無料アカウントがあれば、数分でLightGBMを含むPythonの実行環境が立ち上げられます。
ご自身のPCへLightGBMをインストールする方は、公式サイトのインストールガイド(英語)が最も信頼の置けるソースです。ご自身の環境(Mac、Windows、Linux)に応じて公式サイトの手順に沿ってインストールしましょう。
手っ取り早くインストールされたい方はAnacondaのconda-forgeからインストールすることも可能です。conda-forgeとはコミュニティベースで管理されているパッケージの構築レポジトリです。(LightGBMの公式ではありませんのでご注意ください)
Anacondaをインストール後にMacの方はターミナルで、Windowsの方はConda Promptから下記のコードによりLightGBMのインストールが可能です。(完了までに数分かかりますのでご注意ください)
|
1 2 3 4 |
$ conda install -c conda-forge lightgbm |
2. データセットの取得
本稿ではKaggleにて公開されている「Kuzushiji-MNIST」のデータセットを使います。Kuzushiji-MNISTは人文学オープンデータ共同利用センター(CODH)が「日本古典籍くずし字データセット」を基に作成したデータセットです。頭文字を略してKMNISTとも呼ばれます。
KMNISTデータセットはKaggleよりダウンロードすることが可能です。以下のURLから5つのファイルのダウンロードをお願いします。データのダウンロードにはKaggleの無料アカウントが必要です。
【データ取得先】
【ダウンロードデータファイル名】
- kmnist_classmap.csv(151 B)
- kmnist-test-imgs.npz(2.93 MB)
- kmnist-test-labels.npz(5.18 KB)
- kmnist-train-imgs.npz(17.41 MB)
- kmnist-train-labels.npz(29 KB)
- 『KMNISTデータセット』(CODH作成) 『日本古典籍くずし字データセット』(国文研ほか所蔵)を翻案 doi:10.20676/00000341
画像データの2つはZIP形式で圧縮されています。お手持ちの解凍ソフトでローカルに解凍してください。拡張子が.npzとなってれば問題ありません。
続いてこれらのデータをGoogle Colabへアップロードします。Google Colabに新しいノートブックを作成しましょう。Googleにログイン後に下記のリンクから作成が可能です。(ローカル環境で実行する方はこちらの操作は不要です)
Python 3の新規google colabノートブック作成
最上部のコードセルへ以下のPythonコードを入力して実行(SHIFT + ENTER)して下さい。ブラウザのファイルアップロードボタンが出力されます。「ファイルを選択」をクリックして、先ほどKaggleからダウンロードした5つのファイルを全てアップロードしましょう。
|
1 2 3 4 5 6 |
# filesモジュールをインポート from google.colab import files uploaded = files.upload() |
ファイルが正しくアップロードされたか確認します。Google Colabのメニューから「表示」→「目次」を選んで下さい。左エリアへ目次メニューが表示されます。目次メニュー上部の「ファイル」タブをクリックして「更新アイコン」をクリックしましょう。図5の様にファイルが表示されれば問題ありません。

図 5
3.データセットの確認
まずはPythonの各種ライブラリをインポートしてデータセットの確認をしてみましょう。Google Colabをお使いの方は追加インストールは不要です。ローカル環境をお使いの方で下記ライブラリがインストールされていない場合は個別にインストールが必要です。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
# データ処理ラブラり import numpy as np import pandas as pd # データ可視化ライブラリ import matplotlib.pyplot as plt %matplotlib inline # LightGBM import lightgbm as lgb # Scikit-learn(評価算出) from sklearn.metrics import confusion_matrix from sklearn.metrics import accuracy_score |
KMNISTデータセットを読み込みましょう。kmnist_classmap.csvは画像のターゲットクラスが格納されています。CSVファイルはpandasのread_csv関数で読み込みことが可能です。
|
1 2 3 4 5 6 |
classes = pd.read_csv('kmnist_classmap.csv') print(classes.shape) classes |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
-- 出力 (10, 3) index codepoint char 0 0 U+304A お 1 1 U+304D き 2 2 U+3059 す 3 3 U+3064 つ 4 4 U+306A な 5 5 U+306F は 6 6 U+307E ま 7 7 U+3084 や 8 8 U+308C れ 9 9 U+3092 を |
KMNISTには10種類の平仮名の画像が含まれています。「お」や「き」などの、各平仮名に対して0〜9の整数インデックスが付与されています。
続いて画像データとターゲットクラスのデータを読み込みます。これらはnpz形式で保存されています。npzとはNumPyで使われるファイルの拡張子で、numpuy.load関数で読み込めます。npzの他にもnpy形式がNumPyには用意されており、一般的にCSVファイルよりメモリ効率が高く読み込み速度も早いです。
npzファイルはPythonのディクショナリに相当するファイル形式です。目的の画像ファイルのキーは「arr_0」です。load関数にキーを指定して訓練/テストデータの読み込みを行います。
|
1 2 3 4 5 6 7 8 9 10 |
# 訓練データの読み込み X_train = np.load('kmnist-train-imgs.npz')['arr_0'] y_train = np.load('kmnist-train-labels.npz')['arr_0'] # テストデータの読み込み X_test = np.load('kmnist-test-imgs.npz')['arr_0'] y_test = np.load('kmnist-test-labels.npz')['arr_0'] |
訓練データとテストデータのサイズを確認してみます。
|
1 2 3 4 5 6 |
# データのサイズ確認 print(X_train.shape) print(X_test.shape) |
|
1 2 3 4 5 6 7 |
-- 出力 (60000, 28, 28) (10000, 28, 28) |
KMNISTは訓練データ6万画像、テストデータ1万画像が収録されています。各画像のサイズは28 x 28のグレースケール(1チャンネル)です。
訓練データのターゲットクラス(y_train)の最初の5レコードを出力してみましょう。ターゲットクラス(kmnist_classmap.csv)を読み込んだ変数classesと比較してみます。
|
1 2 3 4 5 |
print(y_train[0:5]) print(classes) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
-- 出力 [8 7 0 1 4] index codepoint char 0 0 U+304A お 1 1 U+304D き 2 2 U+3059 す 3 3 U+3064 つ 4 4 U+306A な 5 5 U+306F は 6 6 U+307E ま 7 7 U+3084 や 8 8 U+308C れ 9 9 U+3092 を |
y_trainの整数はclassesのindexカラムと連動しています。ターゲットクラス8は平仮名の「れ」を意味します。後ほど参照しやすいようにclassesをディクショナリに変換しましょう。
|
1 2 3 4 5 |
labelindex = classes.set_index('index').to_dict()['char'] labelindex |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
-- 出力 {0: 'お', 1: 'き', 2: 'す', 3: 'つ', 4: 'な', 5: 'は', 6: 'ま', 7: 'や', 8: 'れ', 9: 'を'} |
試しにKMNISTの画像データを表示してみます。X_trainには画像のピクセル値が格納されています。KMINSTは28 x 28のグレースケールの画像です。各ピクセルの値は最小値0〜最大値255です。確認のためX_trainの最小値と最大値を算出してみましょう。
|
1 2 3 4 5 |
print(X_train.min()) print(X_train.max()) |
|
1 2 3 4 5 6 7 |
-- 出力 0 255 |
ピクセル値の数列から画像へ変換するにはMatplotlibのimshow関数が便利です。X_trainのインデックス423のデータをimshow関数で画像として表示してみましょう。引数cmapでカラーマップの指定が可能です。本データはグレースケールなのでplt.cm.grayを指定しています。
|
1 2 3 4 5 |
plt.imshow(X_train[423], cmap = plt.cm.gray) plt.show() |
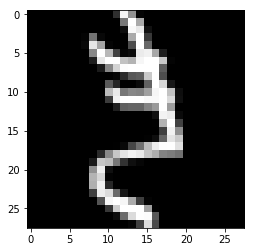
平仮名の「き」の画像のようです。ターゲットクラス(y_train)の同じインデックスの値も確認してみます。y_trainのインデックス423は「1」です。labelindexのキー「1」を確認すると平仮名の「き」でした。特徴量とターゲットクラスが連動してるのが確認できました。
|
1 2 3 4 5 |
print(y_train[423]) print(labelindex[1]) |
|
1 2 3 4 5 6 |
-- 出力 1 き |
4. データ前処理
モデル訓練を行う前に簡単なデータ前処理を行いましょう。まずは画像データの「正規化(Normalization)」を行います。
正規化とはデータを一定の規則に従い変形し利用しやすくすることを指します。正規化を行う理由は機械学習の手法により異なります。例えば、最急降下法(Gradient Descent)による最適化を行う手法では、特徴量データの「尺度(レンジ)」を正規化することにより最適化プロセスを効率的に行うことが可能になります。
前の項で示した通り画像データは各ピクセルの値を持つ数列です。本データセットはグレースケールの画像データですので、ピクセルの最小値は0、最大値は255です。これらのピクセルの値は画像の「濃淡」を表現します。値が低い箇所は黒に近く、値が高くなるにつれ白を表現します。
試しに訓練データの一部を抽出してデータの値を確認してみましょう。
|
1 2 3 4 |
plt.imshow(X_train[0,10:15,10:15], cmap = plt.cm.gray) |
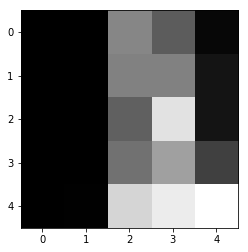
画像データはこのようにピクセル値の集合により表現されます。画像データの正規化には複数の手法があります。本稿ではそれぞれのピクセルの値を最大値255で割りましょう。この処理により全てのピクセルの値は0〜1のレンジとなります。
|
1 2 3 4 5 6 |
# 訓練/テストデータの正規化 X_train = X_train / 255 X_test = X_test/ 255 |
先ほど確認した訓練データ(X_train)の同じ部分を確認してみましょう。
|
1 2 3 4 |
X_train[0,10:15,10:15] |
|
1 2 3 4 5 6 7 8 9 |
-- 出力 array([[0. , 0. , 0.52156863, 0.35686275, 0.02745098], [0. , 0. , 0.50196078, 0.50196078, 0.07843137], [0. , 0. , 0.37254902, 0.87843137, 0.07843137], [0. , 0. , 0.43921569, 0.62352941, 0.25098039], [0. , 0.00392157, 0.82745098, 0.91764706, 0.99215686]]) |
|
1 2 3 4 5 |
print(X_train.shape) print(X_test.shape) |
|
1 2 3 4 5 6 7 |
-- 出力 (60000, 28, 28) (10000, 28, 28) |
|
1 2 3 4 5 6 7 8 |
X_train = X_train.reshape(X_train.shape[0], 784) X_test = X_test.reshape(X_test.shape[0], 784) print(X_train.shape) print(X_test.shape) |
|
1 2 3 4 5 6 7 |
-- 出力 (60000, 784) (10000, 784) |
5. LightGBMのハイパーパラメータ
機械学習でハイパーパラメータとは機械学習手法(またはアルゴリズム)の挙動を制御する設定を指します。これらの設定は設計者(エンジニア)が指定します。
LightGBMにも数多くのハイパーパラメータが存在します。本稿ではLightGBMの公式ドキュメント(英語)に準じて、特に重要なハイパーパラメータを解説します。
まずはLightGBMの分類器「LGBMClassifier」のクラスを呼び出して、ハイパーパラメータの初期値を確認してみましょう。
|
1 2 3 4 |
lgb.LGBMClassifier() |
|
1 2 3 4 5 6 7 8 9 10 11 |
-- 出力 LGBMClassifier(boosting_type='gbdt', class_weight=None, colsample_bytree=1.0, importance_type='split', learning_rate=0.1, max_depth=-1, min_child_samples=20, min_child_weight=0.001, min_split_gain=0.0, n_estimators=100, n_jobs=-1, num_leaves=31, objective=None, random_state=None, reg_alpha=0.0, reg_lambda=0.0, silent=True, subsample=1.0, subsample_for_bin=200000, subsample_freq=0) |
LightGBMには数十のハイパーパラメータが存在します。ハイパーパラメータの優劣をつけることは出来ませんが、特にモデルの推測精度に影響が大きいハイパーパラメータは以下の3つです。
num_leavesLightGBMで最も重要と言っても過言ではないのがnum_leaves(葉の数)です。num_leavesは決定木の複雑度を調整します。num_leavesの値が高すぎると過学習となり、低すぎると未学習になります。num_leavesを調整する場合はmax_depth(決定木の深さ)のパラメータと一緒に調整すると良いです。
min_data_in_leafLeaf-wiseを採用しているLightGBMではmin_data_in_leafはとても重要なハイパーパラメータです。min_data_in_leafは決定木のノード(葉)の最小データ数を指定します。値が高いと決定木が深く育つのを抑えるため過学習防ぎますが、逆に未学習となる場合もあります。min_data_in_leafは訓練データのレコード数とnum_leavesに大きく影響されます。
max_depth決定木の深さを指定するハイパーパラメータです。単体で調整するよりも、他のハイパーパラメータとのバランスを考えながら調整します。
LightGBMのハイパーパラメータはXGBoostと類似していますが、そもそもLevel-wiseとLeaf-wiseで根本から異なりますので注意が必要です。LightGBMのハイパーパラメータチューニングのコツは以下の通りです。各ハイパーパラメータの詳細については公式ドキュメント「Parameters」の参照をお願いします。
モデル訓練のスピードをあげる
- bagging_fraction(初期値1.0)とbagging_freq(初期値0)を使う
- feature_fraction(初期値1.0)で特徴量のサブサンプリングを指定
- 小さいmax_bin(初期値 255)を使う
- save_binary(初期値 False)を使う
- 分散学習を使う(公式ガイドはこちら)
推測精度を向上させる
- 大きいmax_bin(初期値255)を使う
- 小さいlearning_rate(初期値0.1)と大きいnum_iterations(初期値100)を使う
- 大きいnum_leaves(初期値31)を使う
- 訓練データのレコード数を増やす(可能であれば)
過学習対策
- 小さいmax_binを使う(初期値255)
- 小さいnum_leavesを使う(初期値31)
- min_data_in_leaf(初期値20)とmin_sum_hessian_in_leaf(初期値1e-3)を使う
- bagging_fraction(初期値1.0)とbagging_freq(初期値0)を使う
- feature_fraction(初期値1.0)で特徴量のサブサンプリングを指定
- 訓練データのレコード数を増やす(可能であれば)
- lambda_l1(初期値0.0)、lambda_l2(初期値0.0)、min_gain_to_split(初期値0.0)で正則化を試す
- max_depth(初期値-1)を指定して決定木が深くならないよう調整する
上記のLightGBMのハイパーパラメータはあくまで一部です。勾配ブースティングは推測精度が高く、非常に強力な機械学習の手法ですが、このようにハイパーパラメータが多いです。扱うデータや目的に応じて正しい調整が必須です。
6. LightGBM モデル訓練
いよいよLightGBMを使ってモデル訓練を行いましょう!まずはLightGBMのモデルへデータセットの初期化セットする必要があります。lightgbm.Datasetのクラスへ訓練データ(train_data)とテストデータ(eval_data)を設定しましょう。
|
1 2 3 4 5 6 |
# 訓練・テストデータの設定 train_data = lgb.Dataset(X_train, label=y_train) eval_data = lgb.Dataset(X_test, label=y_test, reference= train_data) |
本稿は画像のくずし字を分析して、正しいクラス(平仮名)に分類を行うタスクです。前の項で解説した通りLightGBMには数多くのハイパーパラメータが存在しますが、本稿では全て初期値を使いモデル訓練を行います。
train()を使いモデル訓練を行ってみましょう。train()へモデル訓練の挙動を制御するパラメータを指定します。boosting_typeのgbdtは「Gradient Boosting Decistion Tree」の略です。分類クラスは3つ以上ですので多項分類(multiclass)を目的(objective)に指定します。またターゲットクラスは10種類の平仮名ですのでnum_classは10となります。
|
1 2 3 4 5 6 7 8 9 10 |
params = { 'task': 'train', 'boosting_type': 'gbdt', 'objective': 'multiclass', 'num_class': 10, 'verbose': 2, } |
train()へパラメータ、訓練データ、テストデータを渡してモデル訓練を開始しましょう。num_boost_round引数は勾配ブースティングのイテレーションの回数を指定します。初期値の100回を指定してモデル訓練を行ってみましょう。
【注意】モデル訓練には一般的なスッペクのPCで5分〜20分程度要します。それぞれのPCスペックに合わせてイテレーションの回数を調整してください。(例:num_boost_round=10)
|
1 2 3 4 5 6 7 8 9 10 |
gbm = lgb.train( params, train_data, valid_sets=eval_data, num_boost_round=100, verbose_eval=5, ) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
-- 出力 [5] valid_0's multi_logloss: 1.71401 [10] valid_0's multi_logloss: 1.43197 [15] valid_0's multi_logloss: 1.2474 [20] valid_0's multi_logloss: 1.11132 [25] valid_0's multi_logloss: 1.00722 [30] valid_0's multi_logloss: 0.924201 [35] valid_0's multi_logloss: 0.856528 [40] valid_0's multi_logloss: 0.799088 [45] valid_0's multi_logloss: 0.751136 [50] valid_0's multi_logloss: 0.711042 [55] valid_0's multi_logloss: 0.675216 [60] valid_0's multi_logloss: 0.645093 [65] valid_0's multi_logloss: 0.617719 [70] valid_0's multi_logloss: 0.594623 [75] valid_0's multi_logloss: 0.573648 [80] valid_0's multi_logloss: 0.5548 [85] valid_0's multi_logloss: 0.537461 [90] valid_0's multi_logloss: 0.52171 [95] valid_0's multi_logloss: 0.508122 [100] valid_0's multi_logloss: 0.49569 |
モデル訓練が完了しました。イテレーションを100回でモデル訓練を行いましたが、loss値が下がり続けていることからも、まだ改善の余地はありそうです。
それでは、いよいよテストデータを使い推測結果を算出してみましょう。
|
1 2 3 4 |
preds = gbm.predict(X_test) |
predsの値は各クラスに属する確率です。NumPyのargmax関数を使いターゲットクラスへ変換しましょう。
|
1 2 3 4 5 6 7 |
y_pred = [] for x in preds: y_pred.append(np.argmax(x)) |
テストデータを使って訓練済みのLightGBMのモデルから推測結果が算出されました。では、いよいよ答え合わせです!混同行列(Confusion Matrix)と正解率(Accuracy)を算出してみます。
|
1 2 3 4 |
confusion_matrix(y_test, y_pred) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
-- 出力 array([[872, 3, 2, 4, 31, 16, 3, 34, 31, 4], [ 2, 840, 34, 4, 24, 5, 49, 6, 15, 21], [ 6, 22, 826, 48, 17, 7, 27, 14, 21, 12], [ 2, 13, 31, 917, 8, 4, 6, 7, 3, 9], [ 35, 22, 24, 13, 834, 8, 23, 9, 18, 14], [ 7, 25, 101, 7, 16, 802, 26, 2, 12, 2], [ 2, 18, 52, 4, 19, 5, 885, 9, 3, 3], [ 9, 21, 12, 5, 73, 2, 34, 787, 37, 20], [ 5, 34, 10, 32, 2, 7, 21, 1, 883, 5], [ 5, 21, 30, 7, 34, 3, 12, 26, 25, 837]]) |
|
1 2 3 4 |
accuracy_score(y_test, y_pred) |
|
1 2 3 4 5 6 |
-- 出力 0.8483 |
LightGBMでくずし字の画像認識を行った結果、テストデータで84.83%の正解率となりました!まだまだ改善する余地は大いにあります。改善のポイントを幾つか記載します。
- ハイパーパラメータチューニング
- 学習率とイテレーション数の調整
- early_stopping_roundsの使用
まとめ
本稿ではLightGBMの概要や仕組み、さらにくずし字データセット(KMNIST)を使い画像認識の実装を行いました。LightGBMはXGBoostと並び、データ分析競技などで頻繁に使われる機械学習手法です。
codexaでは機械学習準備編として、無料でコースを公開しています。是非、これらのコースの受講をご検討ください。
・Numpy 入門(無料)
・Pandas 入門(無料)
・Matplotlib 入門(無料)
・線形代数(無料)
・統計基礎(無料)
また、すでに機械学習の基礎知識がある方に向けて、機械学習の様々な手法を詳しく解説したチュートリアルも公開しています。
・実践 線形回帰
・実践 ロジスティック回帰
・決定木とランダムフォレスト
・サポートベクターマシン
・ナイーブベイズ(単純ベイズ分類器)
・XGBoost
・はじめての画像認識
以上となります!最後まで記事をご覧頂き、ありがとうございました。

