
短期間で日本のスタートアップシーンを大きく揺るがした超大型スタートアップの「メルカリ」が、Kaggle(Kaggleとは?)にて競争コンペを公開しました!
私が記憶している限りだと、おそらく「リクルート」に次いで、日系企業として2社目かと思います!日本勢カグラーで上位を叩き出したいところではありますが、ひとまず最速レビューとして英語の苦手な方でも参加が可能なように、コンペの概要をまとめました。
また、ランダムフォレストを使って、既に複数のカーネル(コード)も公開されていましたので、機械学習初心者向けのハンズオンチュートリアルもまとめています。機械学習を勉強されている方は、これを機会にKaggleへの参加をしてみてはいかがでしょうか?
初めて機械学習に学ぶのであれば、Kaggleへ参加する前に初歩的な手法から学ぶのがオススメです。環境構築が不要、オンラインで実行が可能な機械学習入門チュートリアルを公開中!機械学習の世界へ飛び込んでみませんか?
この記事の目次
メルカリ 価格予測チャレンジ概要

Kaggleメルカリチャレンジでは、販売者が投稿した情報を基に「適正な販売価格」を予測するチャレンジです。訓練データとして、ユーザーが投稿した商品情報やカテゴリ、さらに商品の状態やブランド名などが与えられており、それらを基に販売価格を予測するモデル作成が課題です!
下記、Kaggleメルカリチャレンジの必要な概要情報まとめです。
- コンペ開始日は2017年11月21日
- エントリー締切日は2018年2月7日
- 課題提出締切日は2018年2月14日
- このチャレンジは「カーネルオンリー」(カーネルの提出をしないと評価されません)
- 現在公開されているデータ(Stage1)のカーネルを使ってStage2のデータ予測を行う
- チャレンジの最終ランキングはStage2のスコアが基準となる
- 賞金は1位60,000米ドル、2位30,000米ドル、3位10,000米ドル
まだ公開されて4日目と間もないですが、既に231チームが参加しています。現時点でのトップスコアは「0.44408」ですが、時間が経つにつれてスコアは改善されるかと!公開ランキングでは、既に日本人らしきお名前も数名見かけます!(頑張りましょう!!)
では、早速データの簡単な概要と、ランダムフォレストを使った初心者向けKaggleメルカリのハンズオンチュートリアルをやっていきましょう。
Kaggleメルカリ初心者向けチュートリアル概要
本チュートリアルは、機械学習初心者向けの内容となっています。既にKaggleへ参加しているデータサイエンティストの皆々様からは厳しいツッコミがありそうですが・・暖かい目で見守ってください。(笑)
チュートリアルで使うもの
- Python 3.X
- Pandas
- Numpy
- scikit-learn
- Jupyter Notebook(必須ではありません)
Python 2をお使いの方がいましたら、3を使うようにお願いします。それ以外のライブラリは、おそらくバージョンが多少違くても問題ないかと思います。
チュートリアルで行う内容
- Kaggleメルカリチャレンジのデータの確認
- データ事前処理
- ランダムフォレストのモデル作成
- 予測データのCSV書き出し
- Kaggleへの投稿
メルカリチャレンジの「Kernels」ページでは既にたくさんのランダムフォレストを使った予測モデルが公開されています。本チュートリアルでは、同様にランダムフォレストを使った予測を行います。Kaggleメルカリチャレンジへ投稿(Submit)すると「0.53」のスコアとなります。(11月25日時点で100位以内/231位)
参考までにですが、本チュートリアルはMac macOS High Sierra、メモリ 8GB、プロセッサ2.4GHz Core i5で、15分〜20分程度で処理が完了しました。
Kaggleメルカリのデータ確認
では、早速やってみましょう。まずは必要なものをインポートしておきましょう。
|
1 2 3 4 5 6 7 8 9 10 |
import pandas as pd from sklearn.ensemble import RandomForestRegressor, RandomForestClassifier from IPython.display import display from sklearn import metrics from sklearn.model_selection import train_test_split pd.set_option('display.float_format', lambda x:'%.5f' % x) import numpy as np |
次にメルカリから提供されているトレーニングとテストデータを読み込みましょう。Kaggle Mercari Price Suggestion Challenge Dataのページからダウンロードが可能です。ダウンロードにはKaggleへの無料会員登録とコンペ参加規約への同意が必要ですので、まだ会員でない方は、まずはKaggleへの登録をしましょう。
メルカリから提供されているデータ形式ですが、「.7z」の形式となっています。Macをお使いの方は、「The Unarchiver」 で解凍が可能です。(無料でApp Storeより入手可能)
Kaggleからデータをダウンロードして解凍が出来たら、Pandasでデータフレームへ読み込みを行いましょう。
|
1 2 3 4 5 6 7 8 9 10 |
# データタイプを指定 types_dict_train = {'train_id':'int64', 'item_condition_id':'int8', 'price':'float64', 'shipping':'int8'} types_dict_test = {'test_id':'int64', 'item_condition_id':'int8', 'shipping':'int8'} # tsvファイルからPandas DataFrameへ読み込み train = pd.read_csv('train.tsv', delimiter='\t', low_memory=True, dtype=types_dict_train) test = pd.read_csv('test.tsv', delimiter='\t', low_memory=True, dtype=types_dict_test) |
お決まりですが、ひとまずheadとshapeでデータのサイズと中身をチラ見してみましょう。
|
1 2 3 4 5 6 7 8 9 10 11 |
# trainとtestのデータフレームの冒頭5行を表示させる train.head() test.head() # trainとtestのサイズを確認 train.shape, test.shape ((1482535, 9), (693359, 8)) |
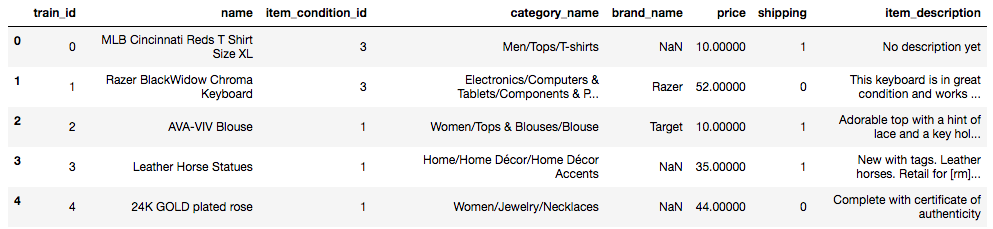
trainの最初5行
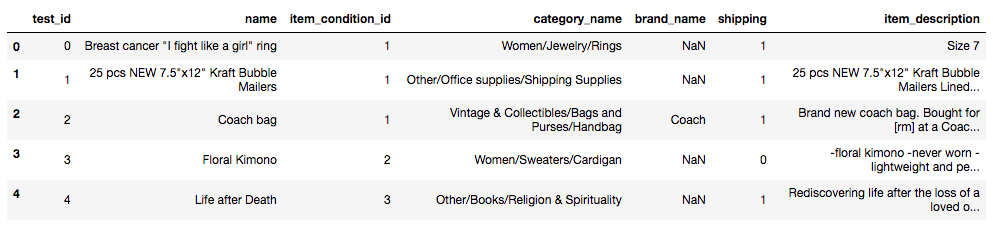
testの最初5行
トレーニングデータは1,482,535個のユーザーが投稿した販売商品のデータセットとなっています。同様にテストデータは693,359個となりますが、「価格(Price)」の項目がテストデータは含まれていませんので列数は「8」となっています。
各データの情報を簡単にまとめました。
- train_id / test _id – ユーザー投稿のID
- name – 投稿のタイトル。タイトルに価格に関する情報がある場合(例:$20)はメルカリが事前に削除をして[rm]と置き換えています。
- item_condition_id – ユーザーが指定した商品の状態
- category_name – 投稿カテゴリー
- brand_name – ブランドの名前
- price – 訓練データのみ。実際に売られた価格。米ドル表示。今回のチャレンジの予測ターゲットとなります。
- shipping – 送料のフラグ。「1」は販売者負担。「0」は購入者負担。
- item_description – ユーザーが投稿した商品説明の全文。タイトルと同様に価格情報がある場合は[rm]と置き換えられています。
冒頭でも触れましたが、Kaggleメルカリチャレンジではこのダウンロードしたデータは「ステージ1」のデータとなります。実際にランキングの評価となるテストデータは、メルカリが新たに提供する「ステージ2」のデータです。(締切日までに投稿されたカーネルに自動的にステージ2のテストデータが提供されてスコアが算出されます)
次にデータの統計量を確認しましょう。Pandasの行と列の表示オプションを最大にして表示する「display_all」を作成して、trainとtestの統計量を確認します。「transpose」で列と行を転置しています。
|
1 2 3 4 5 6 7 8 9 10 |
def display_all(df): with pd.option_context("display.max_rows", 1000): with pd.option_context("display.max_columns", 1000): display(df) # trainの基本統計量を表示 display_all(train.describe(include='all').transpose()) |
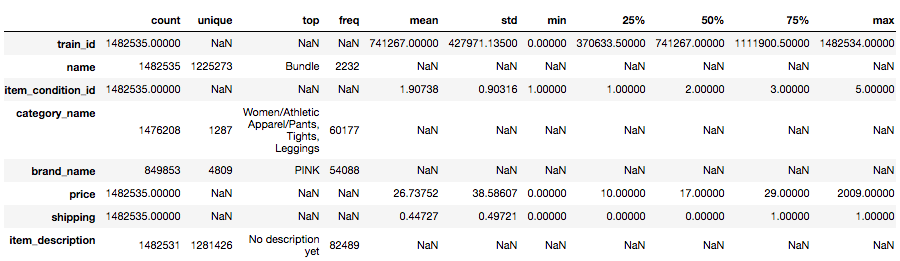
ふむふむ。「item_description」の「Top」では「No description yet」と出ていますね。商品説明がしっかり入っている訳ではなさそうですね。価格(price)は平均(mean)が26.74ドルで標準偏差(std)が38.59ドル。最小値が0ドル、最大値は2009ドルとなっています。一体、メルカリで2009ドルもの高価なものが売れているのに驚きが隠せませんが、それよりも最小値0ドルも気になります。
あんまり深追いすると進みませんので、サクサクと次にいきましょう!
次は、下記の4つの文字列を値として持っている項目を「category」のデータタイプへ変換をしましょう。
データタイプを文字列からcategoryへ変換する項目(trainとtestで同項目)
- category_name
- item_description
- name
- brand_name
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# trainのカテゴリ名、商品説明、投稿タイトル、ブランド名のデータタイプを「category」へ変換する train.category_name = train.category_name.astype('category') train.item_description = train.item_description.astype('category') train.name = train.name.astype('category') train.brand_name = train.brand_name.astype('category') # testのカテゴリ名、商品説明、投稿タイトル、ブランド名のデータタイプを「category」へ変換する test.category_name = test.category_name.astype('category') test.item_description = test.item_description.astype('category') test.name = test.name.astype('category') test.brand_name = test.brand_name.astype('category') # dtypesで念のためデータ形式を確認しましょう train.dtypes, test.dtypes |
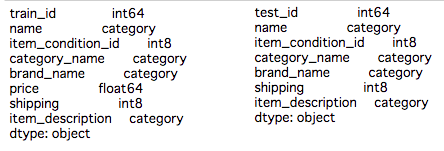
左がtranで右がtestです。指定した項目のデータ形式が「category」に変換されているのが確認できます。
次はデータのユニーク値を確認しておきましょう。
|
1 2 3 4 5 6 7 8 |
# trainの中のユニークな値を確認する train.apply(lambda x: x.nunique()) # testの中のユニークな値を確認する test.apply(lambda x: x.nunique()) |
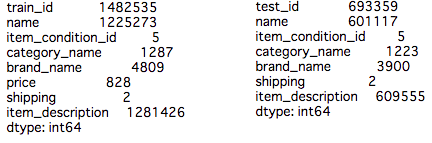
左がtrainで右がtestのユニーク値の確認テーブル
当然ではありますが、train、test共にIDはしっかりとユニークな値となっています。カテゴリやブランド名の重複は当然ですが、投稿タイトル(name)にも重複データが結構ありますね。先に確認しましたが商品説明では「No Description yet」(商品説明がまだありません)があったので、こちらも重複があって当然ですね。
モデルを作成する前に必ずやらなくてはいけない作業、欠損データの確認もしておきましょう!
|
1 2 3 4 5 6 7 8 |
# trainの欠損データの個数と%を確認 train.isnull().sum(),train.isnull().sum()/train.shape[0] # testの欠損データの個数と%を確認 test.isnull().sum(),test.isnull().sum()/test.shape[0] |
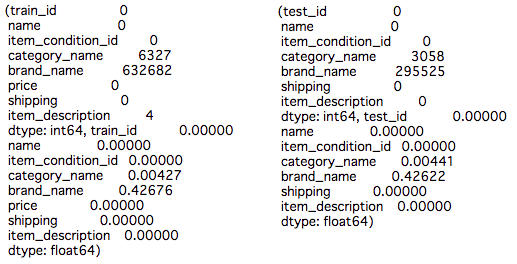
左がtrainで右がtestです。最初に欠損データ数を表示して、次に欠損データの割合を表示しています
カテゴリ名(category_name)とブランド名(brand_name)は欠損数が大きいですね。ブランド名の欠損度合いはかなり大きいのも確認できます。データの簡単な確認も行えましたので、次からはデータの事前処理を行なっていきましょう。
Kaggleメルカリ データ事前処理
さて、ランダムフォレストのモデルを作成するためにデータの事前処理を行なっていきましょう。事前処理の流れとしては・・
- trainとtestのデータを連結させる
- 連結させたDataFrameの文字列のデータ形式を「cateogry」へ変換
- 文字列を数値へ値を変換
- 訓練用データの「price」をnp.log()で処理
- ランダムフォレスト用にxとy(ターゲット)で分ける
ランダムフォレストのモデルを作るため、文字列のデータ(例:投稿タイトルやカテゴリ名など)をPandasの関数を使って一気に数値へと変換させます。そのため、testとtrainで別々に処理を行わず、連結して事前処理を行います。
文字列を数値へ変換したら、testとtrainへ改めて分けて、さらにランダムフォレスト作成のため、trainからターゲット(つまりprice)を分ける処理を行います。
文章で見ると・・いまいちパッとしませんので、実際にコードを見ていきましょう!
まずは、trainとtestのIDのカラム名を変更して、さらにデータ連結後でもどちらのデータに属しているかわかるようにフラグをつけておきましょう。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# trainとtestのidカラム名を変更する train = train.rename(columns = {'train_id':'id'}) test = test.rename(columns = {'test_id':'id'}) # 両方のセットへ「is_train」のカラムを追加 # 1 = trainのデータ、0 = testデータ train['is_train'] = 1 test['is_train'] = 0 # trainのprice(価格)以外のデータをtestと連結 train_test_combine = pd.concat([train.drop(['price'], axis=1),test],axis=0) # 念のためデータの中身を表示させましょう train_test_combine.head() |
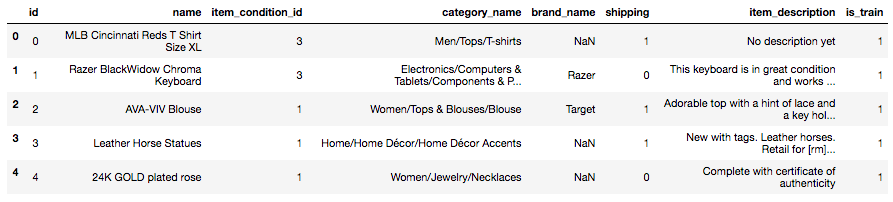
これで、trainとtestのデータの連結が「train_test_combine」に入りました。念のためshapeを確認すると「(2175894, 8)」と訓練データ1,482,535個とテストデータ693,359個の合計になっているのが確認できます。
次は、文字列のデータを数値へ変換しましょう。先に「train」と「test」を個別に文字列データの形式をcategoryに変換しましたが、同様に、連結させたデータ(train_test_combine)のデータ形式も変更をしましょう。
category形式に変換したら、pandasのcat.codesで数値へ変換を行います。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
# train_test_combineの文字列のデータタイプを「category」へ変換 train_test_combine.category_name = train_test_combine.category_name.astype('category') train_test_combine.item_description = train_test_combine.item_description.astype('category') train_test_combine.name = train_test_combine.name.astype('category') train_test_combine.brand_name = train_test_combine.brand_name.astype('category') # combinedDataの文字列を「.cat.codes」で数値へ変換する train_test_combine.name = train_test_combine.name.cat.codes train_test_combine.category_name = train_test_combine.category_name.cat.codes train_test_combine.brand_name = train_test_combine.brand_name.cat.codes train_test_combine.item_description = train_test_combine.item_description.cat.codes # データの中身とデータ形式を表示して確認しましょう train_test_combine.head() train_test_combine.dtypes |
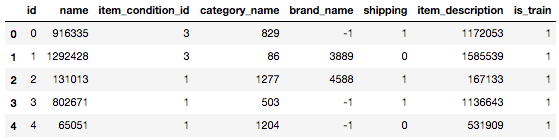
train_test_combineのヘッド情報

train_test_combineのdtypes
しっかりと文字列の値が数値へ変換されていますね。念のため表示したdtypesでも、objectからintへ変換されているのが確認できます。
数値へ変換が行えましたので、ここでtestとtrainへまた分けましょう。「is_train」(trainとtestのどちらに属するかを示すフラグ)は不要なので、この段階で落として、念のため、分け終わった後のtrain、testのデータフレームのサイズを確認しておきましょう。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
# 「is_train」のフラグでcombineからtestとtrainへ切り分ける df_test = train_test_combine.loc[train_test_combine['is_train'] == 0] df_train = train_test_combine.loc[train_test_combine['is_train'] == 1] # 「is_train」をtrainとtestのデータフレームから落とす df_test = df_test.drop(['is_train'], axis=1) df_train = df_train.drop(['is_train'], axis=1) # サイズの確認をしておきましょう df_test.shape, df_train.shape ((693359, 7), (1482535, 7)) |
さて、とうとう次でデータ事前処理の最後のステップとなります!無事に文字列→数値へ変換ができましたので、「df_train」(訓練データ)へ「train」の価格(price)を戻して、log関数で処理を行いましょう。
|
1 2 3 4 5 6 7 8 9 10 11 |
# df_trainへprice(価格)を戻す df_train['price'] = train.price # price(価格)をlog関数で処理 df_train['price'] = df_train['price'].apply(lambda x: np.log(x) if x>0 else x) # df_trainを表示して確認 df_train.head() |

カテゴリ名(category_name)や投稿タイトル(name)などがしっかりと数値に変換されているのが確認できます。参考までにですが、上記のheadのデータのbrand_nameでも確認できますが、文字列から数値へcat.codesへ変換した際に、異常値は「-1」として戻ります。
非常にシンプルなものですが、これでデータセットの事前処理は終わりました!次は、いよいよランダムフォレストのモデルをこのデータを使って作成していきましょう。
ランダムフォレストのモデル作成
もうここまで来れば、(気持ち的に)予測が完了したも同然です笑。では、処理をしたデータを使って、scikit-learnのRandomForestRegressorでモデルを作りましょう!
(処理完了までMac macOS High Sierra、メモリ 8GB、プロセッサ2.4GHz Core i5で、15分〜20分程度かかりました)
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# x = price以外の全ての値、y = price(ターゲット)で切り分ける x_train, y_train = df_train.drop(['price'], axis=1), df_train.price # モデルの作成 m = RandomForestRegressor(n_jobs=-1, min_samples_leaf=5, n_estimators=200) m.fit(x_train, y_train) # スコアを表示 m.score(x_train, y_train) |
さぁ・・・・気になるスコアは・・・
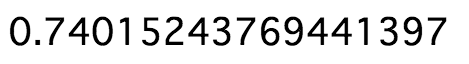
となりました(笑)
モデルも作れましたので、先に処理を指定た「df_test」(テスト用データ)を入れて、実際の予測値を出しましょう。
予測値が出たら、指数関数(np.exp())で処理をして、Pandasシリーズへ落とし込み、メルカリチャレンジの予測提出ファイル形式へ処理をしてCSVの書き出しを行いましょう!
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
# 作成したランダムフォレストのモデル「m」に「df_test」を入れて予測する preds = m.predict(df_test) # 予測値 predsをnp.exp()で処理 np.exp(preds) # Numpy配列からpandasシリーズへ変換 preds = pd.Series(np.exp(preds)) # テストデータのIDと予測値を連結 submit = pd.concat([df_test.id, preds], axis=1) # カラム名をメルカリの提出指定の名前をつける submit.columns = ['test_id', 'price'] # 提出ファイルとしてCSVへ書き出し submit.to_csv('submit_rf_base.csv', index=False) |
自分のパソコンで処理を行なっていた方であれば、「submit_rf_base.csv」のファイルが書き出しされているかと思います。
今回のKaggleメルカリコンペですが、カーネルでのみ評価提出が可能なので、もしKaggleへ実際に投稿してみたい方は、Kaggleのカーネルへ上記コードを入れて提出をしましょう!
冒頭でもお話をしましたが、こちらの処理でスコア「0.53」となります。(11月25日時点で100位以内/231位)
まとめ
いかがでしたでしょうか?すでにKaggleメルカリチャレンジへ参加しているチームは日に日に増えており、さらに上位スコアも伸びてきています!
codexaでは日本でのカグラーのマッチングも行なっています!もし一人で参加するより、チームに参加して挑戦してみたいとお考えの方は、お問い合わせにてKaggleの公開プロフィールURLを記載してご連絡ください!スキルレベルが同等のメンバー様とマッチングいたします。
まだ機械学習を始めたばかりの方は、Kaggleタイタニックのチュートリアルもやってみてはいかがでしょうか?今回はランダムフォレストを使用しましたが、タイタニックでは「決定木」を使っています。
も間違いなどがありましたら・・コメント欄にてご指導・ご指摘をお願い致します!


へー…
kernelなんて、初心者に優しいものがあるんだね
これやってみよ
それにしても0.53ですか
世に出回るAIはすごいんですねぇ…