
2017年11月にサービスインした、アマゾンAWSの新しい機械学習サービス「SageMaker」。codexaの機械学習チーム内でも、利用することが増えてきており、機会学習エンジニアの必須プラットフォームになる可能性をひしひしと感じています。
さて、先日に公開した、第一弾チュートリアル「Amazon SageMakerを使って銀行定期預金の見込み顧客を予測【SageMaker +XGBoost 機械学習初心者チュートリアル】」に続いて、今回は第二弾のAmazon SageMaker初心者向けチュートリアルとなります!
前回は銀行の定期預金マーケティングの予測でしたが、今回はゲームソフトの売行き予測をXGBoostで行います。本チュートリアルの概要は下記となります。(チュートリアル参照元はこちら)
チュートリアルに掛かる時間
1時間〜3時間程度で実施可能です
発生するAWS料金
最低限のインスタンスを利用して3ドル〜5ドルとなります。SageMakerの無料枠の利用も可能ですので、使える方は無料枠でお試しください。 無料枠を利用しない限りは、料金が発生します。インスタンスの選択など、必ず各自の責任で本チュートリアルを実施ください。
【重要】
チュートリアル終了後にインスタンスを放置しておくと、無駄な料金が発生していまします。チュートリアル終了後は、必ずインスタンスの停止または削除を行いましょう!
本チュートリアルで実施する概要
- Amazon SageMakerのノートブックでデータ前処理
- Boto3経由でS3とSagaMakerの連携
- モデルトレーニングインスタンスでSageMaker XGBoostの訓練
- モデルホスティングインスタンスで訓練済みモデルをホスト
- テストデータをホスティングしたモデルを使って予測値を取得
- 結果確認
今回ですが第二回目となりますので、登録や初期設定の詳細に関しては省いています。まだSageMakerを一度も触られたことがない方は、第一弾目からどうぞ。
では、早速、やってみましょう!
この記事の目次
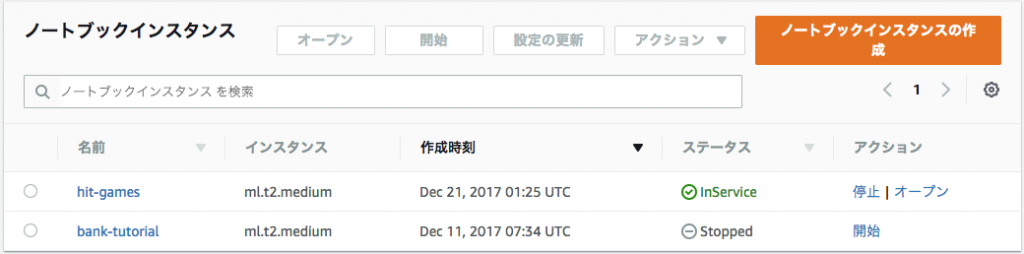
SageMaker ノートブックインスタンスの立ち上げ
SageMakerのメリットの一つとして、クラウドでJupyter Notebookが簡単に使えることです。機械学習で必要なライブラリやフレームワークが、すでに使える環境ですので、大きな時間短縮となります。
では、SageMakerへログインをしてノートブックインスタンスの立ち上げを行なっていきましょう。まだSageMakerのアカウントをお持ちでない方は、こちらから登録をお願いいたします。
インスタンスの立ち上げですが、基本的には下記の3つの設定が必要なります。
- ノートブックインスタンス名
- ノートブックインスタンスのタイプ
- IAMロール
今回はノートブックインスタンス名を「hit-games」と名付けて作成しました。インスタンスのタイプは、一番安い「ml.t2.medium」を利用しています。無料枠が利用可能な方は、こちらへ無料枠用のタイプが出ているかと思いますので、適宜、そちらを選んで下さい。SageMakerの料金設定はこちらのページを各自参照して、料金を理解した上での利用をお願い致します。また、IAMロールの設定はSageMaker一段目チュートリアルをご参照ください。
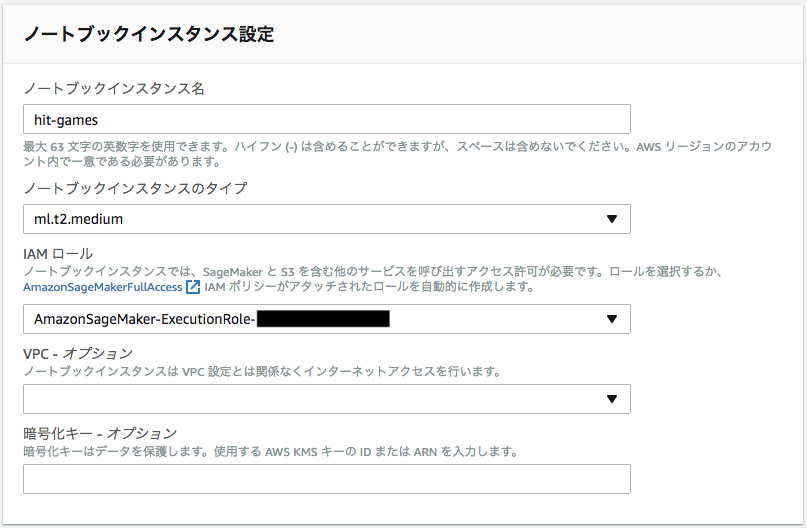
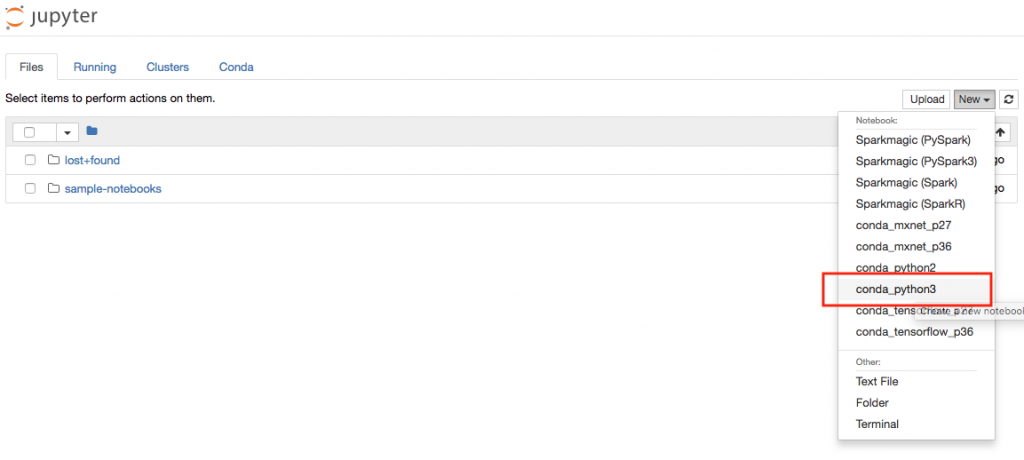
ノートブックインスタンスの立ち上げが完了したら、次はJupyter Notebookで新しいノートを作成しましょう。下記の画面の「New」のドロップダウンから「conda_python3」を選択して、新規ノートブックを作成します。
これで、ノートブックインスタンスの準備完了です。次にS3のバケット名とリージョンの確認を行いましょう。S3とSageMakerのリージョンが異なると、使えませんので気をつけましょう。S3のコンソールへログインをして、バケット名とリージョンの確認をお願いいたします。本チュートリアルでは、SageMakerの「米国東部(バージニア北部)」を利用していますので、s3も同様のリージョンで作られているのが確認できます。
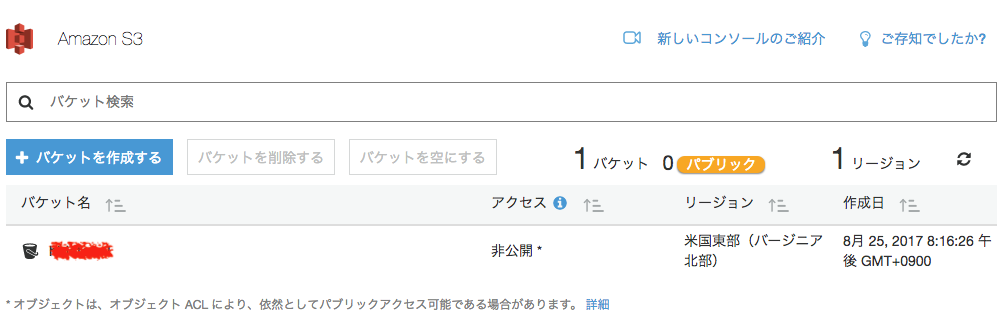
これで、ノートブックインスタンスの作成は完了です。S3のバケット名ですが、後ほど使いますので、どこかにメモっておきましょう。
次はデータセットの取得とノートブックインスタンスを利用して前処理へ進みましょう!
データセットの取得
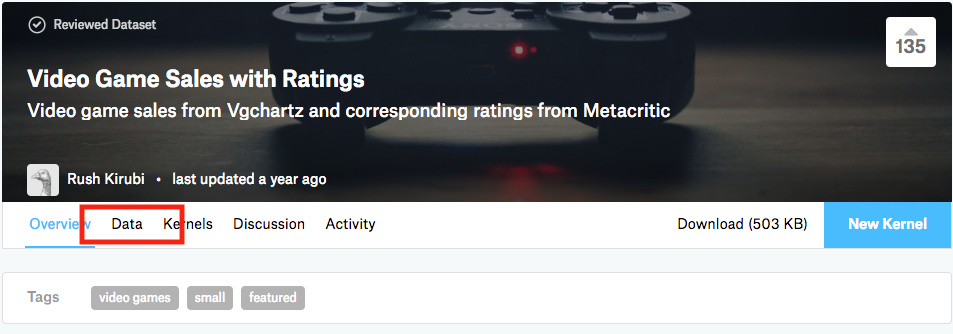
本チュートリアルで使うデータセットはKaggleのVideo Game Sales with Ratings(意訳:ビデオゲームの売上とレビュー)を使います。Kaggleにまだ登録されていない方は、この機会に登録をお勧めいたします。(Kaggleの詳しい説明はこちらをご参考)
登録完了後に「Data」のページからデータセットのダウロードが可能です。 Video_Games_Sales_as_at_22_Dec_2016.csv をローカルにダウロードしましょう。
データセットのダウロードが完了したら、次はS3へアップロードを行います。SageMakerと同じリージョンのS3のバケット直下へ、 Video_Games_Sales_as_at_22_Dec_2016.csv のアップロードをしてください。
次に、SageMaker ノートブックで、S3へ格納したデータセットを読み込んで、データの前処理を行います。先ほど作成したノートブックを開きましょう。
まずは、S3のバケット名の指定、さらにS3で使うプレフィックスとIAM Roleの宣言をしましょう。ノートブックの一番最初のセルへ下記のコードを入力して、Shift + Enterで実行しましょう。
|
1 2 3 4 5 6 7 8 9 |
bucket = 'hideto-ml' prefix = 'sagemaker/videogames_xgboost' # IAMのRoleを宣言 import sagemaker role = sagemaker.get_execution_role() |
次に本チュートリアルで使う機械学習系のライブラリのインポートを一括で行います。今回使うライブラリですが、全てSageMakerにインストール済ですので、特に事前の作業は必要ありません。
NumpyやPandasなどの機械学習定番のライブラリに加えて、PythonとAWSをブリッジングしてくれるboto3も使います。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
# 必要なライブラリのインポートをしましょう # すべてsagemakerで用意されていますので追加作業なし import numpy as np import pandas as pd import matplotlib.pyplot as plt from IPython.display import Image from IPython.display import display from sklearn.datasets import dump_svmlight_file from time import gmtime, strftime import sys import math import json import boto3 |
次は先ほどKaggleからダウロードして、S3へ格納したファイルの読み込みを行います。ファイル名を指定して、Boto3経由でS3からSageMakerへファイルを移しましょう。さらに、CSVファイルからPandasデータフレームへの変換も行なって、データの表示をしてみましょう。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
# KaggleからダウロードしたデータセットをS3のバケットへ格納 # ファイル名を指定する raw_data_filename = 'Video_Games_Sales_as_at_22_Dec_2016.csv' # boto3経由でs3内に格納したデータをSageMakerのノートブックインスタンスへ移します s3 = boto3.resource('s3') s3.Bucket(bucket).download_file(raw_data_filename, 'raw_data.csv') # PandasのデータフレームへCSVファイルを変換 # Pandasの行表示制限のオプション設定を変更 # データを表示させる data = pd.read_csv('./raw_data.csv') pd.set_option('display.max_rows', 20) data |

次は、このデータセットの概要の確認と予測ターゲットの設定を行います。
データセットの確認と予想ターゲットの設定
こちらのデータセットですが、KaggleのDataのページにて詳細が記載してあります。各項目の概要を紐解いていきましょう。データの提供元はMetacritic(メタクリティック)という、ゲームや音楽などをレビュー集積するウェブサービスとなっています。
各項目の概要
- Name ゲームタイトル
- Platform ゲーム機種別
- Year_of_Release ゲーム発売年
- Genre
- ゲームのカテゴリ
- Publisher
- ゲーム販売者名
- NA_Sales 北米の販売数(単位:百万)
- EU_Sales ECの販売数(単位:百万)
- JP_Sales 日本の販売数(単位:百万)
- Other_Sales 上記以外の地域の販売数(単位:百万)
- Global_Sales 全世界の合計販売数(単位:百万)
- Critic_Score メタクリティックが統計したスコア
- Critic_Count Critic_Scoreの算出元となるレビュー数
- User_Score メタクリティックのユーザーがつけた評価スコア
- User_Count User_Scoreの算出元となるユーザー数
- Developer ゲーム開発名
- Rating アメリカのゲーム利用の年齢制限レーティング
データセット概要
- 16719行16列のデータセット
- Name(ゲームタイトル)のユニーク数は約1200
- Platform(ゲーム機)のユニー数は31
- Global_SalesなどSales関連の単位は全てMillion(百万)
- Global_Salesの平均値は0.53(つまり53万個の販売数)
余談ではありますが、こちらのデータを色々と深掘りしてみると面白いですね!別途、時間がある方は深掘りして見ると、データセットの処理の良い勉強になるかと思います!
さて、次は予測ターゲットの設定を考えましょう。今回の予測ターゲットですが、「ゲームソフトがヒットするかどうか」を予測しましょう。ヒットの定義として、ゲームソフトが100万本以上売れたらヒット(ミリオンセラー)とします。
ということで、 Global_Sales のデータ値を参照して、予測ターゲット y を作成しましょう。さらに、今回のデータセットでのミリオンセラーの分布を確認してみましょう。
|
1 2 3 4 5 6 7 8 9 10 |
# ターゲットを設定 # Global_Salesで1(100万本)以上の売上を基準としてyを作成 data['y'] = (data['Global_Sales'] > 1) # ターゲットの分布を確認 plt.bar(['not a hit', 'hit'], data['y'].value_counts()) plt.show() |
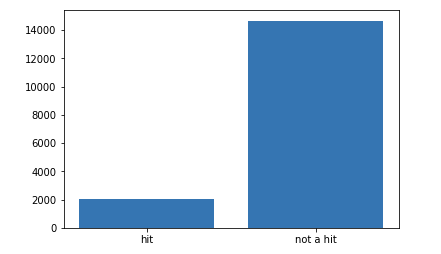
当然といえば当然ですが、ミリオンセラーの販売実績は非常に高い壁のようですね(笑)。莫大なお金と時間を投じても、売れるゲームと売れないゲームがあるという厳しい現実を表したデータです。
予測ターゲットの設定ができましたので、次はいよいよ特徴量を決めていきましょう。データの各項目を見てみると、予測ターゲット( Global_Sales )に特に関係が強うそうなデータとして、 User_Score と Critic_Score が考えられます。この2項目のデータと予測ターゲットyの相関を対数目盛を利用してプロッティングしてみましょう。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# 次は特徴量を決めます # ゲームのレビュー(User_ScoreとCritic_Score)と販売量(Global_Sales)の相関性は? # 対数目盛を使ってグラフにしてみよう viz = data.filter(['User_Score','Critic_Score', 'Global_Sales'], axis=1) viz['User_Score'] = pd.Series(viz['User_Score'].apply(pd.to_numeric, errors='coerce')) viz['User_Score'] = viz['User_Score'].mask(np.isnan(viz["User_Score"]), viz['Critic_Score'] / 10.0) viz.plot(kind='scatter', logx=True, logy=True, x='Critic_Score', y='Global_Sales') viz.plot(kind='scatter', logx=True, logy=True, x='User_Score', y='Global_Sales') plt.show() |

左が Critic_Score で右が User_Score のグラフとなります。想像の通り両方のデータはターゲット y の予測をするのに使えそうなのが解ります。他にも genre (ゲームのカテゴリ)も当然、ミリオンセラーの要因になりますし、 ESRB (米ゲーム年齢制限レーティング)も販売対象となるリーチが大きく異なることから(例:全ての年齢対象のソフトより成人対象のソフトはリースが少ない)、予測ターゲットの特徴量として使えるかと思います。ここでは、他の項目とターゲット y との相関を出しませんが、各自でデータを確認してみてください。
次ですが、特徴量として使えない(使わない)項目を考えましょう。すでにデータをパッと確認したら気づくかと思いますが、 JP_Sales (日本での販売数)など、予測ターゲットに直接関係のあるデータが含まれています。これらの項目は予測モデルに組み込むべきではありませんので、除外しましょう。、あた、 Name (ゲームタイトル)や Year_of_Release (販売開始年)なども除外します。
|
1 2 3 4 5 6 |
# 特徴量として使わない項目を除外 data = data.drop(['Name', 'Year_of_Release', 'NA_Sales', 'EU_Sales', 'JP_Sales', 'Other_Sales', 'Global_Sales', 'Critic_Count', 'User_Count', 'Developer'], axis=1) |
これで訓練に使う項目のみが残りましたので、次はお決まりの欠損値の確認を行いましょう。 missing_values_table の関数を作成して、 data の各項目(特徴量)の欠損値の状況把握をします。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# 欠損データの確認 missing_values_tableを作る def missing_values_table(df): mis_val = df.isnull().sum() mis_val_percent = 100 * df.isnull().sum()/len(df) mis_val_table = pd.concat([mis_val, mis_val_percent], axis=1) mis_val_table_ren_columns = mis_val_table.rename( columns= {0 : 'Missing Values', 1: '% of total values'}) return mis_val_table_ren_columns # まずはおきまりの欠損データの状況を確認しておこう missing_values_table(data) |
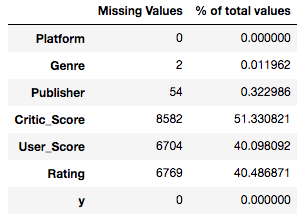
見たところ、 Critic_Score 、 User_Score 、 Rating は50%近くの割合で欠損していますね…。機械学習の醍醐味として、この欠損データをどのように処理を行うかで実力の差が出るのですが、今回はもっともシンプルな方法で処理をしましょう。そう、その方法とは・・除外することです。(失礼しました笑)
|
1 2 3 4 5 |
# 欠損データを除外しよう data = data.dropna() |
これで、欠損データは全て除外されて綺麗になりました。欠損データと同様に、データ値が使えない場合も多々あります。dataを隅々まで確認すると、どうやら User_Score に tbd というストリングの値が含まれています。 User_Score を数値として処理をしたいのに、これは不都合です。
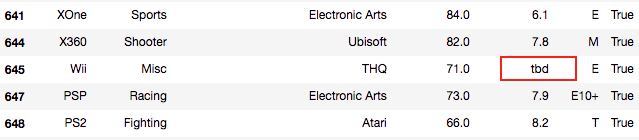
この User_Score の tbd をNaNに変換しましょう。すでに約40%もの User_Score を除外してしまっていますので、これ以上データを絞るのはあまりしたくありません。ですので tbd の値を一度NaNに変換して、さらに相関関係が非常に高い Critic_Score を元にNaNへ代入しましょう。
上の図でもわかり通り、 User_Score は Critic_Score の約1/10となっています。完璧な代入には当然なりませんが、それでもこれ以上データを除外するよりかはマシかと思いますので、その流れで tbd を処理しましょう。
|
1 2 3 4 5 6 7 8 |
# User_Scoreの数値以外の値を処理 data['User_Score'] = data['User_Score'].apply(pd.to_numeric, errors='coerce') # Critic_Scoreの1/10をUser_SocoreのNaNへ代入 data['User_Score'] = data['User_Score'].mask(np.isnan(data["User_Score"]), data['Critic_Score'] / 10.0) |
データの前処理もほとんど終わりです。次は、予測ターゲットの y を扱いやすいように処理して、データ前処理で定番のダミー変数化をしましょう。
|
1 2 3 4 5 6 7 8 |
# 予測ターゲットを扱いやすいように処理 data['y'] = data['y'].apply(lambda y: 'yes' if y == True else 'no') # 全ての特徴量をダミー変数化 model_data = pd.get_dummies(data) |
これで、特徴量の前処理は完了です!次は過学習対策として、データを3つのグループへ分けましょう。今回のチュートリアルでは全体の70%を学習用データとして分けて、20%を評価用データとして使いましょう。残りの10%は最終のテスト用データとして残しておきます。
|
1 2 3 4 5 |
# train_dataを3つのデータセットへ分別 train_data, validation_data, test_data = np.split(model_data.sample(frac=1, random_state=1729), [int(0.7 * len(model_data)), int(0.9 * len(model_data))]) |
さて、いよいよデータ前処理の最後のステップとなります。最後は、XGBoost用にlibSVM形式へ変換をして、boto3を経由してS3へファイルを送りましょう。
|
1 2 3 4 5 6 7 8 9 10 11 |
# libSVM形式へ変換 dump_svmlight_file(X=train_data.drop(['y_no', 'y_yes'], axis=1), y=train_data['y_yes'], f='train.libsvm') dump_svmlight_file(X=validation_data.drop(['y_no', 'y_yes'], axis=1), y=validation_data['y_yes'], f='validation.libsvm') dump_svmlight_file(X=test_data.drop(['y_no', 'y_yes'], axis=1), y=test_data['y_yes'], f='test.libsvm') # boto3経由でlibSVMをS3へ送る boto3.Session().resource('s3').Bucket(bucket).Object(prefix + '/train/train.libsvm').upload_file('train.libsvm') boto3.Session().resource('s3').Bucket(bucket).Object(prefix + '/validation/validation.libsvm').upload_file('validation.libsvm') |
上記のコードを実行した後に、念のためS3を確認しておきましょう。下記のキャプチャのように、libSVMファイルがS3へ格納されているはずです。
以上でデータの前処理が完了しました!次から、SageMakerのモデルトレーニングインスタンスを立ち上げてモデル構築、さらにはモデルホスティングインスタンスでモデルを使えるようにしましょう。
モデルトレーニング
データの処理が完了したところで、次はXGBoostのモデルの訓練を始めましょう。XGBoostですが、多数のハイパーパラメーターが用意されていますが、今回はその中のいくつか初歩的なものを使ってトレーニングを行いましょう。
ハイパーパラメーターとは?
機械学習で使われるモデルで、人間が設定しなくてはいけないパラメーター(設定)のことです。機械学習では、データを用いて機械が学習するものですが、学習されない項目を人間が設定することにより、結果の良し悪しが変動することが多々あります。
さて、次はノートブックでモデルトレーニングを実行していきましょう。手順として、まずは訓練のジョブ用に必要なパラメータ設定して、その後に訓練のジョブを動かします。
コードを動かす前に重要な点が一つ!SageMakerですが、ノートブック、モデルトレーニング、モデルホスティングの各インスタンスで料金が異なります。全てのインスタンスで本チュートリアルでは、全てい最小限のものを利用しています。インスタンスの料金は、各自、必ず理解をした上で実行をお願い致します。
では、モデルトレーニングをやっていきましょう!まずは、パラメーターの設定をしましょう。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 |
job_name = 'videogames-xgboost-' + strftime("%Y-%m-%d-%H-%M-%S", gmtime()) print("Training job", job_name) containers = { 'us-west-2': '433757028032.dkr.ecr.us-west-2.amazonaws.com/xgboost:latest', 'us-east-1': '811284229777.dkr.ecr.us-east-1.amazonaws.com/xgboost:latest', 'us-east-2': '825641698319.dkr.ecr.us-east-2.amazonaws.com/xgboost:latest', 'eu-west-1': '685385470294.dkr.ecr.eu-west-1.amazonaws.com/xgboost:latest' } create_training_params = \ { "RoleArn": role, "TrainingJobName": job_name, "AlgorithmSpecification": { "TrainingImage": containers[boto3.Session().region_name], "TrainingInputMode": "File" }, "ResourceConfig": { "InstanceCount": 1, "InstanceType": "ml.c4.xlarge", # こちらでインスタンスタイプが調整可能です! "VolumeSizeInGB": 10 }, "InputDataConfig": [ { "ChannelName": "train", "DataSource": { "S3DataSource": { "S3DataType": "S3Prefix", "S3Uri": "s3://{}/{}/train".format(bucket, prefix), "S3DataDistributionType": "FullyReplicated" } }, "ContentType": "libsvm", "CompressionType": "None" }, { "ChannelName": "validation", "DataSource": { "S3DataSource": { "S3DataType": "S3Prefix", "S3Uri": "s3://{}/{}/validation".format(bucket, prefix), "S3DataDistributionType": "FullyReplicated" } }, "ContentType": "libsvm", "CompressionType": "None" } ], "OutputDataConfig": { "S3OutputPath": "s3://{}/{}/xgboost-video-games/output".format(bucket, prefix) }, "HyperParameters": { "max_depth":"3", "eta":"0.1", "eval_metric":"auc", "scale_pos_weight":"2.0", "subsample":"0.5", "objective":"binary:logistic", "num_round":"100" }, "StoppingCondition": { "MaxRuntimeInSeconds": 60 * 60 } } |
次に、モデル訓練のジョブの実行です。こちらですが、本チュートリアルで使用したインスタンス( ml.c4.xlarge )で約6分程処理に掛かりました。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
%%time sm = boto3.client('sagemaker') sm.create_training_job(**create_training_params) status = sm.describe_training_job(TrainingJobName=job_name)['TrainingJobStatus'] print(status) try: sm.get_waiter('training_job_completed_or_stopped').wait(TrainingJobName=job_name) finally: status = sm.describe_training_job(TrainingJobName=job_name)['TrainingJobStatus'] print("Training job ended with status: " + status) if status == 'Failed': message = sm.describe_training_job(TrainingJobName=job_name)['FailureReason'] print('Training failed with the following error: {}'.format(message)) raise Exception('Training job failed') |
これで、事前に処理したデータセットとSageMakerのXGBoostの訓練が、モデルトレーニングインスタンス上で完了できました。この訓練したモデルのホスティングをSageMakerを使ってやってみましょう。
モデルホスティングの実施
SageMakerのサーバーレスエンドポイントでのホスティングをやってみましょう。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# スコアリングコンテナとmodel.tar.gzを指定してホスティングモデルを作成する create_model_response = sm.create_model( ModelName=job_name, ExecutionRoleArn=role, PrimaryContainer={ 'Image': containers[boto3.Session().region_name], 'ModelDataUrl': sm.describe_training_job(TrainingJobName=job_name)['ModelArtifacts']['S3ModelArtifacts']}) print(create_model_response['ModelArn']) |
次にホスティングエンドポイントの設定をいくつかしましょう。具体的には、ホスティングで使うEC2インスタンスの指定や、初期で使うインスタンスの個数、さらにはホストされているモデルの名前の設定をします。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
xgboost_endpoint_config = 'videogames-xgboost-endpoint-config-' + strftime("%Y-%m-%d-%H-%M-%S", gmtime()) print(xgboost_endpoint_config) create_endpoint_config_response = sm.create_endpoint_config( EndpointConfigName=xgboost_endpoint_config, ProductionVariants=[{ 'InstanceType': 'ml.t2.medium', 'InitialInstanceCount': 1, 'ModelName': job_name, 'VariantName': 'AllTraffic'}]) print("Endpoint Config Arn: " + create_endpoint_config_response['EndpointConfigArn']) |
さて、最後にモデルのホスティングの実行しましょう。こちらですが、完了するまでに16分程度掛かりました。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
%%time xgboost_endpoint = 'EXAMPLE-videogames-xgb-endpoint-' + strftime("%Y%m%d%H%M", gmtime()) print(xgboost_endpoint) create_endpoint_response = sm.create_endpoint( EndpointName=xgboost_endpoint, EndpointConfigName=xgboost_endpoint_config) print(create_endpoint_response['EndpointArn']) resp = sm.describe_endpoint(EndpointName=xgboost_endpoint) status = resp['EndpointStatus'] print("Status: " + status) try: sm.get_waiter('endpoint_in_service').wait(EndpointName=xgboost_endpoint) finally: resp = sm.describe_endpoint(EndpointName=xgboost_endpoint) status = resp['EndpointStatus'] print("Arn: " + resp['EndpointArn']) print("Status: " + status) if status != 'InService': message = sm.describe_endpoint(EndpointName=xgboost_endpoint)['FailureReason'] print('Endpoint creation failed with the following error: {}'.format(message)) raise Exception('Endpoint creation did not succeed') |

実行したセルの下に、上記のようなメッセージが出れば成功です!
構築したモデルでテストデータを使って予測
やっと、①データの前処理②モデルトレーニング③モデルホスティングが完了しました!次はいよいよ、この構築したモデルを使って、予め切り分けておいたテスト用データを使って予測してみましょう。
|
1 2 3 4 |
runtime = boto3.client('runtime.sagemaker') |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
def do_predict(data, endpoint_name, content_type): payload = '\n'.join(data) response = runtime.invoke_endpoint(EndpointName=endpoint_name, ContentType=content_type, Body=payload) result = response['Body'].read() result = result.decode("utf-8") result = result.split(',') preds = [float((num)) for num in result] preds = [round(num) for num in preds] return preds def batch_predict(data, batch_size, endpoint_name, content_type): items = len(data) arrs = [] for offset in range(0, items, batch_size): if offset+batch_size < items: results = do_predict(data[offset:(offset+batch_size)], endpoint_name, content_type) arrs.extend(results) else: arrs.extend(do_predict(data[offset:items], endpoint_name, content_type)) sys.stdout.write('.') return(arrs) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
%%time import json with open('test.libsvm', 'r') as f: payload = f.read().strip() labels = [int(line.split(' ')[0]) for line in payload.split('\n')] test_data = [line for line in payload.split('\n')] preds = batch_predict(test_data, 100, xgboost_endpoint, 'text/x-libsvm') print ('\nerror rate=%f' % ( sum(1 for i in range(len(preds)) if preds[i]!=labels[i]) /float(len(preds)))) |
これで・・切り分けておいた10%のテストデータを使って、構築したモデルで予測が完了しました。機械学習をやっていると、いつもこの瞬間がドキドキします。癖になりますよね(笑)
予測結果の評価ですが、様々な評価方法が存在します。今回は非常にシンプルに、実際の正解データと予測データを付け合わせたテーブルをPandasで作成して、そちらを確認してみましょう。
|
1 2 3 4 |
pd.crosstab(index=np.array(labels), columns=np.array(preds)) |
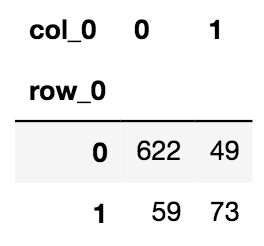
こちらが今回の結果となります。テストデータ803件を訓練済みXGBoostモデルで予測をしたところ、ミリオンセラーと予測した122件のゲームソフトのうち、73件が実際にミリオンセラーでした!
加えて、今回のモデルでは、803件のゲーム中、681件はミリオンセラーにならないと予測して、実際は622件が100万本届かなかったゲームと言えます。(うち59件はミリオンセラーとなりました)
【重要】
チュートリアル終了後にインスタンスを放置しておくと、無駄な料金が発生していまします。チュートリアル終了後は、必ずインスタンスの停止または削除を行いましょう!
まとめ
Amazon SageMakerでXGBoostを使った機械学習チュートリアルですが、いかがでしたでしょうか?SageMakerは全てのエンジニアが気軽に機械学習ができることを目的として作られたサービスです。
いくつか癖のある、覚えなくてはいけない箇所(特にモデルホスティング)はあるものの、一概として非常に簡単に、しかも素早く機械学習を実装できるという点では優れたサービスです!
また、機械学習を初めてばかりで、もっと触ってみたいとお考えの方は、下記の初心者向けチュートリアルも是非やってみてください。(下記はAmazon SageMakerではなく、Jupyter Notebookと各ライブラリを使って実施してます)
以上、SageMakerの初心者向けチュートリアル第二弾でした!近日中に今回使用したXGBoostの詳細チュートリアルも予定していますので、興味のある方はコデクサのfacebookまたはTwitterのフォローをお願い致します!

