
皆さん、突然ですが上の画像をご覧ください。
(画像引用:OpenCV公式サイトより)
これは、画像認識技術の応用例の一つです。コンピューターが映像の範囲内で移動する複数の人間を検知し、その移動をリアルタイムで追跡している様子が見て取れます。かなりの数の人がいるにも関わらず、ほとんどの人を正確に検出することができていますね。画像認識とは、このように画像の数値情報のパターンから写っている物体を認識する手法のことを指します。(本稿で度々登場する物体検出という用語も画像認識と同様の意味を持つと考えていいでしょう。)
また、これは画像認識の例ですが、高精度の画像認識を行うために必要不可欠なのが画像処理の技術です。画像処理とは、コンピュータを用いて画像に対して行う、色を変換したり変形させたり、ぼかしたりするなどの処理全般を指します。画像処理を行うことで、コンピュータが画像内の物体を認識しやすくなります。
そして、本稿で扱うOpenCV(読み:オープン・シーブイ)は、画像処理と画像認識の両方を実装できるPythonのライブラリです。前半で、OpenCVについて、主な機能や他の画像系ライブラリとの違いを解説します。後半では、OpenCVを用いて実際に「画像処理」、「物体検出(画像認識)」、「機械学習」の実装を行います。本稿を通して、画像処理・画像認識の基礎知識と実装スキルを身につけましょう。
OpenCVとは
本節では、OpenCVについて詳しく解説していきます。OpenCVの概要について説明したのち、OpenCVの主な機能を紹介します。また、PillowやScikit-imageなどの他の画像処理系ライブラリとの比較も行います。

<OpenCV公式サイトより> ※背景の挿入は筆者による
OpenCVの概要
OpenCVは、その名の通りオープンソースのコンピュータビジョン用ライブラリです。コンピュータビジョンは、コンピュータによる視覚についての研究分野の名称ですが、画像認識とほぼ同義と考えていただければわかりやすいかと思います。OpenCVは、元々はインテルが開発したプログラムで、現在でも開発が進められています。ごく一部のアルゴリズムは特許を取得されているため、それらを商用利用する際には確認が必要ですが、基本的に無料で利用することができ、商用利用も可能です。また、クロスプラットフォームのライブラリで、Linux、MacOS、Windowsや、iOS、AndroidといったOSとC++、Python、Javaの三つのプログラミング言語に対応しているため、あまり環境の制約を受けることなく活用することができます。
OpenCVの主な機能
OpenCVの主な機能について見ていきましょう。本稿では、OpenCVの主な機能を以下の5つに大別して解説します。
- 画像と動画の読み込み / 表示 / 保存
- 画像処理
- 機械学習
- 検出(画像認識)
- 三次元の処理
画像と動画の読み込み・表示・保存
画像を扱うためには画像を表示したり保存したりする機能がなければいけません。OpenCVにはこれらの基本的な機能は当然搭載されています。また、動画を扱うための機能や、図形や文字などを描画する機能もあり、様々な素材を扱うことができます。
画像処理
OpenCVで実行可能な画像処理の例として以下のようなものが挙げられます。本稿後半の実装では、犬の画像を用いて様々な画像処理を行いますので、ご期待ください。
- 色変換
カラー画像をグレースケール画像にしたり、BGR(Blue, Green, Red)で表示されている画像の色をRGB(Red, Green, Blue)に変換したりと、様々な変換方法があります。単に色を変換するだけでなく、他の処理と組み合わせることによって、画像内にある特定の色の物体を検出することなどもできます。 - 幾何変換(拡大・縮小・回転など)
画像を拡大・縮小したり、回転させたりすることができます。一見大したことのない処理に思えますが、物体検出の際に画像の向きや大きさなどを変えるだけでも検出の成否が変わることもあるため、重要な処理手法です。 - しきい値処理
グレースケール化された画像において、設定されたしきい値よりピクセルの値が大きい場合と小さい場合で別々の値を割り当てることで画像を変換する手法です。説明だけではイメージしづらいかと思いますので、後半の実装を確認してください。 - 平滑化
平滑化は、端的に言えばぼかしを入れる処理手法です。ぼかしの入れ方にも様々な手法があり、適切な手法を用いることで画像内のノイズを除去することができます。 - モルフォロジー変換
主に色が二種類の画像(二値画像)に対して行う処理で、画像上に写っている物体を膨張させたり縮小させたりすることができます。これも、平滑化と同様にノイズ除去に活用できます。 - 部分的な復元
落書きや傷がある写真などにおいて、周辺の画素の情報からその部分を復元するといった処理も可能です。
機械学習
OpenCVには、機械学習の機能も含まれています。OpenCVで活用できる手法はk近傍法、サポートベクターマシン、K-Meansクラスタリングで、これらの手法を文字分類や画像処理に活用することができます。例えば、クラスタリングの手法を用いて画像に含まれる色のデータを複数のクラスターに分けることで、色の種類を減らす処理なども可能です。本稿後半の実装では、k近傍法を用いてくずし字の分類予測を行います。
検出(画像認識)
画像中の様々なものを検出・認識する機能としては以下のようなものがあります。
- 直線・円の検出
- エッジ検出
エッジとは、輝度が大きく変化する点のことで、物体の輪郭などがそれに当たります。 - 物体検出
画像中の物体を検出するいわゆる画像認識の機能です。顔や目など、基本的な物体については分類器がOpenCV内に用意されている上、学習に必要な大量の画像データさえ集めることができれば、自分で検出したい物体用の分類器を作ることもできます。
三次元の処理
さらに、OpenCVでは二次元の画像データから三次元の情報を推測し、以下のような処理をすることができます。
- 画像の歪みの補正
- 画像中に三次元の物体を描画
- 複数枚の二次元画像から実際の距離を推測
以上がOpenCVの主な機能です。ここに紹介しているものだけでも様々なことができますが、これでもOpenCVの機能の一部にすぎません。本稿では簡単にご説明しましたが、各機能の仕組みも含めてより詳しく知りたい方は、OpenCV-Pythonのチュートリアルをご覧いただくといいかと思います。
他の主な画像処理系ライブラリとの比較
OpenCVがいかに幅広い機能を備えているかは概ねお分かりいただけたかと思います。しかし、画像処理・画像認識系のライブラリには他にもPillow(読み:ピロウ)やScikit-image(読み:サイキット・イメージ)など有名なものがあります。では、これらのライブラリとOpenCVにはいったいどのような違いがあるのでしょうか。各ライブラリの特徴を確認し、OpenCVと比較してみましょう。
Pillow

<Pillow公式サイトより> ※背景の挿入は筆者による
PillowはPython Imaging Library (PIL)から派生したPython用画像処理ライブラリです。サムネイル画像の作成、画像のファイル形式の変更、画像の表示などの基本的な操作に加えて、画像のリサイズ、回転、アフィン変換、色変換、明るさの調整、二値変換、ぼかし、減色、画像の貼り付けなど、様々な処理を行うことができます。ただし、あくまで画像処理ライブラリであり、OpenCVのような機械学習や物体検出の機能は搭載されていないようです。画像処理だけが目的であればPillowを使ってみるのもいいでしょう。
Scikit-image

Scikit-imageは画像処理や物体検出のためのPython用ライブラリです。OpenCVやPillowと同様の様々な画像処理に加えて、画像内の特徴点や物体を検出することもできます。ただし、機械学習を行う際には他のライブラリを用いる必要があります。
NumPy

<NumPy公式サイトより>
画像データは数値データの集まりなので、数値計算ライブラリとしてよく知られているNumPy(読み:ナンパイ)も画像処理に活用することができます。単色化や減色などの処理が可能ですが、NumPyだけでは画像を読み込めないため、OpenCVやPillowといった画像の読み込みが可能なライブラリと併用する必要があります。(参考:NumPy入門コース)
Pillow、Scikit-image、NumPyなど、画像処理や画像認識の際に便利なライブラリがいくつもあることがお分かりいただけたと思います。その上で、OpenCVを用いるメリットの一つとして、画像処理、物体検出、そして機械学習までを一つのライブラリで行うことができる点が挙げられます。次節の実装ではこの特徴を活かし、OpenCVをフル活用して様々な実装をしていきましょう。
OpenCVによる画像処理、画像認識実践
本節では、いよいよOpenCVを用いて画像処理と画像認識を行います。具体的には、画像処理、物体検出、機械学習を用いた文字分類の順で実装・解説していきます。なお、本稿の実装においては、Google Colabを利用します。(参考:Google Colabの使い方)
まずは利用するライブラリをまとめてインポートしましょう。numpy、pandas、matplotlibに加えて、OpenCVのpython用ライブラリであるcv2をインポートします。また、OpenCVには、画像を表示する際に用いるcv2.imshowというメソッドがありますが、Google Colabで使うとエラーとなってしまうので、パッチとして用意されているcv2_imshowをインポートしておきましょう。
|
1 2 3 4 5 6 7 8 9 10 |
[In] : #ライブラリのインポート import numpy as np import pandas as pd import matplotlib.pyplot as plt import cv2 from google.colab.patches import cv2_imshow |
画像処理
実際に画像処理を行う前に、画像表示用の関数を定義しておきます。本稿の実装では、様々な画像処理を行うため、次の関数を用いて画像表示を簡略化します。この関数の引数に(元の画像、処理後の画像)を指定することで、元の画像と処理後の画像を二つ並べて表示することができます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
[In] : #画像を表示するための関数を定義 def show_img(Input,Output): plt.subplot(121) #画像の位置を指定 plt.imshow(Input) #画像を表示 plt.title('Input') #画像の上にInputと表記 plt.xticks([]) #x軸の目盛りを非表示 plt.yticks([]) #y軸の目盛りを非表示 plt.subplot(122) #画像の位置を指定 plt.imshow(Output) #画像を表示 plt.title('Output') #画像の上にOutputと表記 plt.xticks([]) #x軸の目盛りを非表示 plt.yticks([]) #y軸の目盛りを非表示 |
画像の読み込み
まずはGoogle Colab上にアップロードした画像を読み込みます。本稿では、画像処理の実装のために犬の画像を利用します。同じ画像で実装を行いたい方はこちらのサイトからダウンロードして、Google Colab上にアップロードしてください。画像の読み込みにはcv2.imreadを用い、読み込みの際には第二引数に0を指定することでグレースケール化を行います。グレースケール化とは、単純に言えば画像を白黒にし、ピクセルの明るさの違いのみを表現する方法です。これを行うことによって、画像のデータ量を減らし、処理にかかる時間を短縮することができます。
|
1 2 3 4 5 6 |
[In] : #画像をグレースケール化して読み込み ※画像ファイル名の箇所は適宜変更してください。 original = cv2.imread('dog_image.jpg',0) |
画像サイズ変更
画像サイズの変更を行いましょう。アップロードした画像のサイズが大きいため、cv2.resizeを用いて画像サイズを横250ピクセル、縦180ピクセルに変更してみます。cv2.resizeの引数には(画像データ,(変更後の横、変更後の縦))の順に値を入力します。なお、matplotlibを用いると自動的にサイズを調整された画像が表示されてしまうため、ここでは先ほど定義した関数は用いずに、cv2_imshowを用います。
|
1 2 3 4 5 6 7 8 9 10 |
[In] : #画像のサイズを変更 img0 = cv2.resize(original,(250,180)) #画像を表示 cv2_imshow(original) cv2_imshow(img0) |

画像サイズを小さくすることができました。なお、Google Colab以外で実装する場合には、画像が別のWindowで表示されるため、以下のコードが必要となります。本稿では、以後省略します。
|
1 2 3 4 5 6 7 |
[In] : #Google Colab以外でOpenCVを用いて画像を表示する場合に必要なコード cv2.waitKey(0) #キーボードが押されるまで待機 cv2.destroyAllWindows() #全てのウィンドウを閉じる |
画像の色を変換
次に、画像の色を変換します。matplotlibでは画像の色データがRGBの順になっているものとして扱われるため、元の画像データの色がこの順でない場合、変換する必要があります。今回は、cv2.cvtCOLORを用いてBGRからRGBに変換します。これによって、matplotlibを用いた場合にも上の画像と同様にグレースケール化した画像が表示されます。
|
1 2 3 4 5 6 7 8 9 10 |
[In] : #画像の色をmatplotlibに合わせて変換 img = cv2.cvtColor(img0, cv2.COLOR_BGR2RGB) #画像を表示 show_img(img0,img) |

画像の平行移動
次に、画像を平行移動させてみましょう。手順は以下のようになります。まず、画像の移動量を決めて変数に格納します。この際に、numpyのfloat32型のデータを2×3の行列に格納すること、下の例の0と1の値は変化させないことに注意してください。なお、以下の例は右に50ピクセル、下に30ピクセル移動させるように値を指定してありますが、これらの値を変化させることで上下左右に指定したピクセル分だけ移動させることができます。。次に、cv2.warpAffineを用いて画像を平行移動させます。cv2.warpAffineの引数には、(画像データ、2×3の行列で移動量を格納した変数、出力する画像のサイズ)を入力します。今回は、元の画像データのサイズと同じサイズにして出力してみましょう。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
[In] : #画像の移動量を決定して変数に格納 M = np.float32([[1,0,50],[0,1,30]]) #画像を平行移動 moved = cv2.warpAffine(img,M,(250,180)) #関数を利用して画像を表示 show_img(img,moved) |

画像の回転と拡大・縮小
次は画像を回転させます。手順は先ほどの平行移動と似ていますが、今度は画像の行数・列数を直接入力せず、img.shapeから変数に格納して用いましょう。こうすることで、元の画像のサイズがわかっていない場合でも同様に回転させることが可能になります。では、具体的な手順を解説します。まず、画像の行数・列数をそれぞれ変数rowsとcolsに格納します。次に、cv2.getRotationMatrix2Dを用いて回転の仕方を示す行列を変数に格納します。cv2.getRotationMatrix2Dの引数には、(回転の中心、回転の角度、拡大・縮小の度合い)の順に入力します。今回は、回転の中心は画像の中心に、回転の角度は左に60度に、拡大・縮小の度合いは0.5に縮小するように指定してみましょう。回転の仕方を変数に格納した後は、先ほどの平行移動と同様に、cv2.warpAffineを用いて画像を処理して、関数を利用して表示します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
[In] : #画像の行数・列数を変数に格納 rows,cols = img.shape[:2] #画像の回転量を決定して変数に格納 M = cv2.getRotationMatrix2D((cols/2,rows/2),60,0.5) #画像を回転 rotated = cv2.warpAffine(img,M,(cols,rows)) #関数を利用して画像を表示 show_img(img,rotated) |

画像のせん断
さて、次は画像のせん断を行います。せん断とは、四角形の画像を平行四辺形に変形する処理で、元の画像中の3つの点と、その三点の処理後の位置をそれぞれ2×3の行列で指定することにより実行することができます。具体的には、処理前の画像中の3点の位置をpts1に、それら3点の処理後の位置をpts2にそれぞれ格納し、cv2.getAffineTransform(pts1,pts2)として変数に格納することで、せん断の処理を指定します。以下は、これまでの処理と同様に、cv2.warpAffineを用いて処理し、画像を表示します。以下の例をご覧ください。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
[In] : #画像の変換の度合いを決定して変数に格納 pts1 = np.float32([[40,40],[400,50],[10,220]]) pts2 = np.float32([[20,100],[400,50],[100,270]]) M = cv2.getAffineTransform(pts1,pts2) #画像をせん断 affine = cv2.warpAffine(img,M,(cols,rows)) #関数を利用して画像を表示 show_img(img,affine) |

画像の平滑化
次に解説するのが画像の平滑化です。簡単に言えば画像をぼかす処理です。この処理は非常にシンプルに行うことができ、cv2.blurの引数に画像データとぼかしに用いるフィルターのサイズを(横、縦)の順に指定するだけです。フィルターのサイズが大きければ大きいほど強いぼかしがかかり、小さければ小さいほどぼかしは弱くなります。
|
1 2 3 4 5 6 7 8 9 |
[In] : #画像の平滑化 blurred = cv2.blur(img,(10,10)) #関数を利用して画像の表示 show_img(img,blurred) |

画像のしきい値処理
しきい値処理も比較的シンプルに実装することができます。しきい値処理にはcv2.thresholdを用い、引数には(画像データ、しきい値、しきい値以上の値が変換される値、しきい値処理の手法)を指定します。以下の例で用いているBINARYという手法は単純にしきい値以上を白、しきい値以下を黒に変換する手法です。他にもBINARY_INVやTRUNCなどいくつもの設定が存在するので、ぜひ試してみてください。(参考:各設定の解説(英語))
|
1 2 3 4 5 6 7 8 9 |
[In] : #しきい値処理 ret,binary = cv2.threshold(img,120,255,cv2.THRESH_BINARY) #関数を利用して画像の表示 show_img(img,binary) |

画像のエッジ検出
本稿で実装する最後の画像処理手法は画像のエッジ検出です。cv2.Cannyを用いてエッジ検出を行います。cv2.Cannyの引数には、(画像データ、下の閾値、上の閾値)を指定します。下の閾値と上の閾値の値を変化させることで、検出されるエッジの量が変化します。では、実際にエッジ検出をやってみましょう。
|
1 2 3 4 5 6 7 8 9 |
[In] : #エッジ検出 edges = cv2.Canny(img,180,300) #関数を利用して画像の表示 show_img(img,edges) |
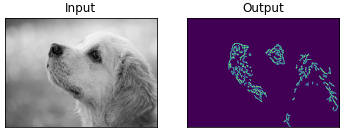
画像内の物体検出(顔・目)
次に実装する機能が画像内の物体検出です。本稿では、OpenCVにあらかじめ用意されている分類器を利用して人の顔の画像から顔と目を検出してみようと思います。まず、人の顔の画像をGoogle Colab上にアップロードした上で読み込みます。本稿では、「ぱくたそ」というサイトに掲載されているモデルのフリー画像を利用させていただきます。同じ画像を利用したい方は、「ぱくたそ」の利用規約をご確認の上、下記URLからダウンロードしてください。なお、本稿の画像1は元画像の左上1280×853ピクセルを、画像2は元画像の中央上部1280×853ピクセルを「ぱくたそ」からダウンロードする際にトリミングしています。
|
1 2 3 4 5 6 7 |
[In] : #画像1・2を読み込み face = cv2.imread('face_image.jpg') face2 = cv2.imread('face_image2.jpg') |
|
1 2 3 4 5 6 7 |
[In] : #画像1・2のサイズを変更 face = cv2.resize(face,(330,220)) face2 = cv2.resize(face2,(300,200)) |
|
1 2 3 4 5 6 7 |
[In] : #カスケード型分類器を読み込み face_cascade = cv2.CascadeClassifier('haarcascade_frontalface_alt.xml') eye_cascade = cv2.CascadeClassifier('haarcascade_eye.xml') |
|
1 2 3 4 5 6 |
[In] : #顔を検出 faces = face_cascade.detectMultiScale(face, 1.1, 3) |
|
1 2 3 4 5 6 7 8 9 10 11 12 |
[In] : #検出した顔を黒い線で囲み、顔の範囲の中から目を検出して白い線で囲む for (x,y,w,h) in faces: face = cv2.rectangle(face,(x,y),(x+w,y+h),(1,1,1),2) roi_color = face[y:y+h, x:x+w] eyes = eye_cascade.detectMultiScale(roi_color) for (ex,ey,ew,eh) in eyes: cv2.rectangle(roi_color,(ex,ey),(ex+ew,ey+eh),(255,255,255),2) |
|
1 2 3 4 5 6 |
[In] : #画像を表示 cv2_imshow(face) |

顔と目を正しく検出できていますね。次に、もう一つの画像でも同様に顔と目を検出できるかどうか試してみましょう。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
[In] : #顔を検出して黒い線で囲み、目を検出して白い線で囲む faces2 = face_cascade.detectMultiScale(face2, 1.1, 3) for (x,y,w,h) in faces2: face2 = cv2.rectangle(face2,(x,y),(x+w,y+h),(1,1,1),2) roi_color = face2[y:y+h, x:x+w] eyes = eye_cascade.detectMultiScale(roi_color) for (ex,ey,ew,eh) in eyes: cv2.rectangle(roi_color,(ex,ey),(ex+ew,ey+eh),(255,255,255),2) #画像を表示 cv2_imshow(face2) |

なんと、この画像では顔と目を検出することができませんでした。実際には画像に対象が写っているにも関わらず、検出がうまくいかない理由は様々ですが、先ほど学んだ画像処理の手法を活用して解決できることがあります。今回は、顔が傾いて写っているのが原因ではないかと推測できるため、画像を15度左に回転させた上でもう一度顔と目の検出を行ってみたいと思います。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
[In] : #画像の行数・列数を変数に格納 rows,cols = img.shape[:2] #画像の回転量を決定して変数に格納 M = cv2.getRotationMatrix2D((cols/2,rows/2),15,1) #画像を回転 face2 = cv2.warpAffine(face2,M,(cols,rows)) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
[In] : #顔を検出して黒い線で囲み、目を検出して白い線で囲む faces2 = face_cascade.detectMultiScale(face2, 1.1, 3) for (x,y,w,h) in faces2: face2 = cv2.rectangle(face2,(x,y),(x+w,y+h),(1,1,1),2) roi_color = face2[y:y+h, x:x+w] eyes = eye_cascade.detectMultiScale(roi_color) for (ex,ey,ew,eh) in eyes: cv2.rectangle(roi_color,(ex,ey),(ex+ew,ey+eh),(255,255,255),2) #画像を表示 cv2_imshow(face2) |

今度は問題なく顔と目を検出できました。なお、今回は顔が傾いているとうまく検出できませんでしたが、様々な傾きの顔を学習させた分類器を作成すれば対応可能かと思います。しかし、検出の際に画像を回転させる場合でも、対象の傾きにも対応した分類器を作成する場合でも、画像を回転させる手法を用いることになります。さらに、今回は画像の回転を例にあげましたが、当然他の画像処理の手法も検出精度の向上には不可欠です。この実装を通して、画像処理の手法は物体検出において非常に重要なことがお分かりいただけたのではないでしょうか。
機械学習(K近傍法)による文字分類
さて、最後にOpenCVを用いて機械学習による文字分類を行います。機械学習による文字分類はScikit-learnなどの機械学習ライブラリを用いても可能ですし、OpenCVよりも使い慣れたライブラリがある方も多いかと思います。しかし、画像処理および物体検出から機械学習までをまとめて実装できるのがOpenCVの特徴の一つですので、本稿ではあえてOpenCVで機械学習を行ってみたいと思います。
データセットの準備とデータの確認
今回機械学習に用いるデータはKaggleにて公開されている「Kuzushizi-MNIST」略して「KMNIST」というデータセットです。KMNISTは「日本古典籍くずし字データセット」を基に人文学オープンデータ共同利用センター(CODH)が作成したデータセットです。KMNISTデータセットはKaggleよりダウンロードすることが可能です。以下のURLから5つのファイルのダウンロードをお願いします。なお、データセットのダウンロードにはKaggleの無料アカウントが必要です。
【データ取得元】
【ダウンロードデータファイル名】
- kmnist_classmap.csv
- kmnist-test-imgs.npz
- kmnist-test-labels.npz
- kmnist-train-imgs.npz
- kmnist-train-labels.npz
【データセット クレジット】
『KMNISTデータセット』(CODH作成) 『日本古典籍くずし字データセット』(国文研ほか所蔵)を翻案 doi:10.20676/00000341
画像データの2つはZIP形式で圧縮されています。お手持ちの解凍ソフトでローカルに解凍してください。
ダウンロードしたデータセットを利用するため、Google Colabを利用している方は実装を行うファイル上にアップロードしてください。また、ローカル環境で実装する方は、ダウンロードしたファイルを適切なフォルダに配置してください。そうしたら、KMNISTのデータを変数に格納しましょう。ダウンロードしたデータは数字と文字の対応表、特徴量とラベルそれぞれの訓練データとテストデータですので、以下のように適切な変数名をつけて利用します。
|
1 2 3 4 5 6 7 8 9 10 |
[In] : #KMINSTのデータを変数に格納 classes = pd.read_csv('kmnist_classmap.csv') X_train = np.load('kmnist-train-imgs.npz')["arr_0"] y_train = np.load('kmnist-train-labels.npz')["arr_0"] X_test = np.load('kmnist-test-imgs.npz')["arr_0"] y_test = np.load('kmnist-test-labels.npz')["arr_0"] |
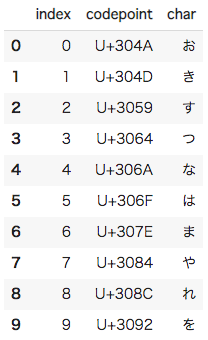
はじめに、classesを開いてみましょう。classesには数字と文字の対応表が格納されています。このデータセットに含まれているくずし字は、以下の10種類のようです。この対応表を用いることで数値データとくずし字を相互に変換することができます。
|
1 2 3 4 5 6 |
[In] : #数字と文字の対応表を表示 classes |
次に、特徴量とラベルそれぞれの訓練データとテストデータのサイズを確認してみましょう。
|
1 2 3 4 5 6 7 8 9 |
[In] : #データのサイズを確認 print(X_train.shape) print(X_test.shape) print(y_train.shape) print(y_test.shape) |
|
1 2 3 4 5 6 7 8 |
[Out] : (60000, 28, 28) (10000, 28, 28) (60000,) (10000,) |
特徴量すなわちくずし字の画像データは、28ピクセル×28ピクセルのデータで、60000の訓練データと10000のテストデータに分割されていることがわかります。また、特徴量の分割に対応して、ラベルも60000の訓練データと10000のテストデータに分割されています。
次に、くずし字を表示してみましょう。2021年ということで、訓練データの2021番目に格納されているくずし字を表示してみます。なお、plt.cm.grayを用いて白黒で表示します。
|
1 2 3 4 5 6 7 |
[In] : #画像を表示 plt.imshow(X_train[2021], cmap = plt.cm.gray) plt.show() |
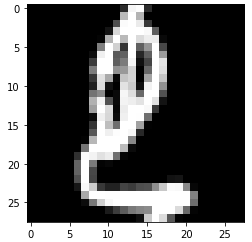
さすがくずし字といったところでしょうか。先ほどの対応表に記載されている10種類のひらがなのどれに該当するのかわかりませんね。。。ということで、ラベルと先ほどの対応表からこの文字がどのひらがななのかを確認してみましょう。
|
1 2 3 4 5 6 |
[In] : print(y_train[2021]) print(classes) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
[Out] : 8 index codepoint char 0 0 U+304A お 1 1 U+304D き 2 2 U+3059 す 3 3 U+3064 つ 4 4 U+306A な 5 5 U+306F は 6 6 U+307E ま 7 7 U+3084 や 8 8 U+308C れ 9 9 U+3092 を |
ラベルの訓練データの2021番目には8が格納されており、対応表と突き合わせると先ほどの文字が「れ」であることがわかりました。
データの前処理
ここまでで、KMNISTデータセットについては概ね理解していただけたかと思います。ここからは機械学習の準備を進めていきましょう。ここでの工程は以下の三つです。
- 画像データを1行に変換
- データの型を変換
- 画像データの正規化
まず、画像データを28行×28列のデータから1行×784列のデータに変形します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
[In] : #画像データを二次元から一次元に変換 X_train = X_train.reshape(60000,784) X_test = X_test.reshape(10000,784) #データのサイズを再度確認 print(X_train.shape) print(X_test.shape) print(y_train.shape) print(y_test.shape) |
|
1 2 3 4 5 6 7 8 |
[Out] : (60000, 784) (10000, 784) (60000,) (10000,) |
次に、各データの型を変更します。元のデータ型だとエラーが起こりますが、特徴量(画像データ)をnp.float32に、ラベルをnp.int64にすることで問題なく学習を進めることができます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
[In] : #各データのデータ型の変更 X_train = X_train.astype(np.float32) X_test = X_test.astype(np.float32) y_train = y_train.astype(np.int64) y_test = y_test.astype(np.int64) #各データのデータ型の確認 print(X_train.dtype) print(X_test.dtype) print(y_train.dtype) print(y_test.dtype) |
|
1 2 3 4 5 6 7 8 |
[Out] : float32 float32 int64 int64 |
最後に、画像データの正規化を行います。正規化とは、データの値を0〜1の範囲に収まるように変換することです。正規化を行うことによって、より効率的に学習を行えるようになります。本稿で用いている画像データは、各ピクセルの色が0〜255のいずれかで表現されているので、全てのピクセルの値を255で割ることによって、最小値が0、最大値が1のデータセットにすることができます。正規化を行なった後で、試しにデータの一部を表示してみます。
|
1 2 3 4 5 6 7 8 |
[In] : #画像データの正規化 X_train = X_train / 255 X_test = X_test / 255 print(X_train[1,150:170]) |
|
1 2 3 4 5 6 7 8 |
[Out] : [0.03921569 0.30588236 0.99215686 1. 1. 0.6509804 0.01568628 0. 0.03529412 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. ] |
訓練データの1枚目の画像から、151〜171番目のピクセルの値を表示しました。0〜1の値に収まっていることが見て取れますね。
k近傍法による学習と予測の実装
機械学習に入る前に、本稿で用いる手法「k近傍法」の概要を説明します。k近傍法は、単純に言うと「新しいサンプルと特徴が似ているいくつかのサンプルのラベルを参考にして、新しいサンプルのラベルを予測する分類手法」です。より具体的に言うならば、k近傍法では特徴量から各サンプルの空間上の位置を算出し、各サンプルを空間上にプロットします。そして、新しい点に対して各サンプルとの距離を計算し、距離が近い複数の(k個の)点のラベルから新しい点のラベルを予測します。下のモデル図でイメージを掴みましょう。
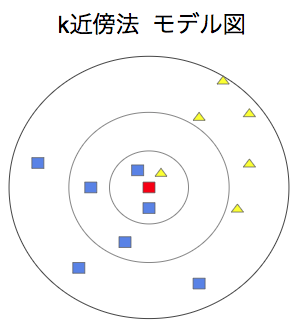
青い四角形と黄色い三角形をそれぞれの特徴から図のように二次元空間にプロットしたとします。そこで、新しいサンプル(赤い四角)が四角形であるのか三角形であるのかをK近傍法で予測します。仮にk=5、すなわち距離が近い5つのサンプルのラベルを参考にする場合、5つのサンプルのラベルは(四角、三角、四角、四角、四角)となるため、新しいサンプルは四角形だと予測することができます。上の図は厳密なものではありませんが、このようなイメージで理解していただくと良いかと思います。
それでは、実際にモデルにデータを学習させ、予測を行います。まず、OpenCVのcv2.ml.KNearst_createを用いてk近傍法のインスタンスを作成します。
|
1 2 3 4 5 6 |
[In] : #k近傍法のインスタンスを作成 knn = cv2.ml.KNearest_create() |
モデルによるデータの学習を行います。knn.trainの引数に(特徴量の訓練データ、cv2.ml.ROW_SAMPLE、ラベルの訓練データ)を指定します。cv2.ml.ROW_SAMPLEは、訓練データがそれぞれ1行のデータであることを示す引数です。
|
1 2 3 4 5 6 |
[In] : #モデルによる学習 knn.train(X_train,cv2.ml.ROW_SAMPLE,y_train) |
|
1 2 3 4 5 |
[Out] : True |
knn.findNearestで学習したモデルによる予測を行います。引数には、特徴量のテストデータと予測の際に参照する近距離の値の数を指定します。このk近傍法のモデルは4種類の値を出力します。本稿では距離が近い5つの文字を予測に用いるように指定したため、return valueと予測値に加えて、各画像の文字と距離が近かった文字上位5つ、それら5つの文字までの距離の4種類です。後者二つはknn.findNearestの第二引数の値によって変化します。k近傍法は新たな点に対して全ての画像との距離を算出する手法であるため、計算量が非常に多く、実行環境によっては多少時間がかかる可能性がある点にはご留意ください。ちなみにGoogle Colab上で実行した場合には、処理に数分程度時間がかかりました。
|
1 2 3 4 5 6 |
[In] : #学習したモデルによる予測 ret,predicted,neighbors,dist = knn.findNearest(X_test,k=5) |
予測ができたら、正解ラベル、予想値、予想の正解率を表示します。なお、予想の正解率はラベルのテストデータと予想値の一致数をテストデータのサンプル数10000で割って求めています。
|
1 2 3 4 5 6 7 8 9 |
[In] : #正解ラベル、予想値、正解率を表示 print("y_test:", y_test) print("predicted:", predicted.T) score = np.sum(y_test == predicted.T)/10000 print("Score:", score) |
|
1 2 3 4 5 6 7 |
[Out] : y_test: [2 9 3 ... 9 4 2] predicted: [[2. 9. 3. ... 9. 4. 2.]] Score: 0.9066 |
シンプルなk近傍法での予測でしたが、90.66%とまずまずの正解率を出すことができていますね。
最後に、予測の際に出力された距離の近さ上位5つの文字とそれら5つの文字までの距離も表示してみましょう。
|
1 2 3 4 5 6 7 |
[In] : #予測の詳細(距離の近さ上位5つの文字、5つの文字までの距離)を表示 print(neighbors) print(dist) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
[Out] : [[2. 2. 2. 2. 2.] [9. 9. 9. 9. 9.] [3. 3. 3. 3. 3.] ... [9. 9. 9. 9. 9.] [4. 4. 4. 4. 4.] [2. 2. 2. 8. 2.]] [[15.663882 17.158724 17.50505 18.134102 18.247566] [30.09421 37.115906 42.739445 45.71484 47.19342 ] [30.3142 35.68461 39.314682 44.805183 46.276993] ... [71.988785 78.130745 78.78104 82.05212 84.749115] [57.134342 68.31008 69.406296 72.67645 73.22733 ] [28.465158 39.65799 40.94851 42.43521 43.218506]] |
まず、距離が近い上位五つの文字に関しては概ね予想通りに予測されています。しかし、最後の行を見ると、4つ目の値が8になっています。先ほどの対応表を確認すると2は「す」で8は「れ」なので、「す」という文字との距離の近さの順位で4番目に「れ」が入ってしまったということになります。また、これら五つの文字への距離は下の行列で示されていますが、画像によってもっとも近い文字への距離にもばらつきがあることがわかります。
まとめ
いかがでしたか?本稿ではOpenCVの機能についての解説や他のライブラリとの比較、3つの実装を行いました。かなり盛りだくさんの内容でしたが、OpenCVについてかなり理解を深めていただけたのではないかと思います。
codexaでは、OpenCVを用いた基本的な画像処理から畳み込みニューラルネットワークの活用までまとめた画像認識のコース「はじめての画像認識」もご用意しています。低価格でご利用いただけますので、ぜひこちらも活用して画像認識についてさらなる知識とスキルを身につけてください。
最後までお読みいただきありがとうございました!

