
昔から、様々なアニメや漫画、映画で「喋るロボット」と人間との関わりが描かれてきました。かつては夢物語に過ぎなかったであろう「喋るロボット」ですが、近年、それが現実のものになりつつあります。そして、そのようなコンピューターによる言語の認識を支えている技術が、「自然言語処理」です。
自然言語処理とは、英語や日本語など、人間が扱う言語(自然言語)をコンピューターによって正しく処理するための技術です。自然言語は非常にあいまいなものであるため、処理するためには非常に高度な技術を必要とします。
本稿では、自然言語処理の中でも基礎的な処理を担う「形態素解析」と、それを実行するための「MeCab」という形態素解析エンジンについての概要を説明します。その上で、Python上でMeCabを用いて簡単な形態素解析の実装を行います。
形態素解析とは
そもそも形態素解析(けいたいそかいせき、Morphological analysis)とはなんでしょうか。まず、形態素解析の概要と意義、大まかな内容を学びましょう。
形態素解析の概要
形態素解析とは、「文を単語(≒形態素)単位に分割し、各単語の品詞を特定する」解析技術のことです。具体的な内容に関しては、後ほど図を用いてご説明します。
形態素解析の意義
形態素解析を行うことによって、コンピューターは文の構成要素を認識することができます。そして、文の構成要素を認識することによって、より高度な自然言語処理を行うことができるようになるのです。形態素解析は高度な自然言語処理を行うための下準備と言えるでしょう。また、特に日本語に関しては、英語などと違って単語が連続して文を構成しているため、高い精度の形態素解析を行うことが比較的困難になっています。ゆえに、日本語を処理する場合には特に重要な技術と言えます。
形態素解析の内容
次に、形態素解析の内容を概観しましょう。形態素解析の内容は、大まかに分けて以下のようになっています。
1. 単語への分かち書き
2. 各単語の品詞の判定
3. 活用されている語の処理
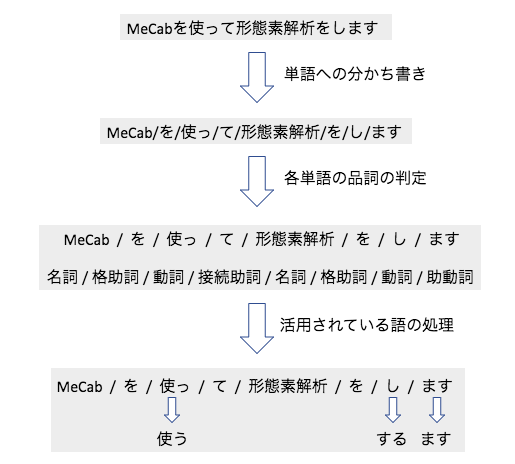
形態素解析では、まず、文を最小単位である単語に分割します。次に、各単語の品詞を判定します。その上で、日本語で言えば動詞や形容詞など、文中での役割に応じて活用されている単語を処理し、原形を求めます。解析エンジンは、事前に与えられた辞書を検索してこのプロセスを進めます。しかし、辞書を隅から隅まで検索していては膨大な処理を行うこととなってしまいます。また、前述のように日本語の文は単語ごとに区切られておらず、文章の意味が客観的に一つに定まらないこともあります。このような問題を少しでも軽減し、より正確な解析を行うため、解析エンジンも発達してきました。
MeCabとは
本節では、形態素解析を行うための解析エンジン「MeCab」の概要とその特徴を学びましょう。
MeCabの概要
MeCabはオープンソースの形態素解析エンジンです。京都大学情報学研究科と日本電信電話株式会社コミュニケーション科学基礎研究所による共同研究ユニットプロジェクトを通じて、工藤拓氏によって開発されました。名前は作者の好物が和布蕪(めかぶ)であることに由来するそうです。(参考:MeCab公式HP、工藤氏プロフィール)
MeCabの特徴
オープンソースの形態素解析エンジンには、MeCabの他にもJumanやChaSenなどがありますが、それらの解析エンジンと比べて、MeCabにはどのような特徴があるのでしょうか。主な特徴4点をまとめました。
高速かつ高精度の解析
MeCabは形態素解析エンジンの中でも、高速かつ高精度の解析を実現しています。まず、高速な解析を実現する鍵となっているのが、高速な辞書引きアルゴリズムです。前述のように、形態素解析では解析エンジンが辞書を引いて解析を進めます。そこに高速で処理できるアルゴリズムを用いることで、解析全体の時間が短縮されるのです。また、条件付き確率場(CRF)と呼ばれる学習モデルを採用しているため、少ないコーパスでも高い学習精度が得られます。具体的には、ChaSenという解析エンジンの学習モデルの3分の1程度のコーパスでも、同程度の精度が実現できるようです。ゆえに、採用する辞書や品詞体系に変更があった場合でも、高精度の解析を実現しやすいです。
最新の状態の辞書を利用可能
MeCabでは、標準的な辞書に加えて、オープンソースのmecab-ipadic-NEologdという辞書を活用することができます。この辞書は佐藤敏紀氏が作成したもので、Web上の言語資源から固有表現を取得して定期的に更新する仕組みになっているため、最新の語彙に対応しているのが大きな特徴です。Twitterのテキストデータなどの、最新の語彙が頻繁に出現するデータを分析する際に有効だと言えるでしょう。mecab-ipadic-NEologdの有用性に関しては、本稿の後半での実装にてご確認ください。(参考:mecab-ipadic-NEologdサイト、佐藤氏による性能検証)
形態素解析エンジンとして必要十分な機能
具体的な機能の面でも特徴があります。MeCabには、前処理や後処理で対応可能な機能は含まれていません。代わりにAPIが充実しているため、スムーズに前処理・後処理を行うことができます。APIはPython、Ruby、Java、C/C++、など、多様な言語に対応しています。さらに、機能を厳選する一方で、形態素解析エンジンとしての性質を活かした機能が盛り込まれている点にも注目すべきでしょう。具体例として、「ソフト分かち書き」が挙げられます、これは、形態素解析と文字単位解析という二つの手法を一つに融合し、パラメータによって両者の違いを連続的に表現した機能です。この機能によって、二つの手法の特徴をうまく活かすことができます。
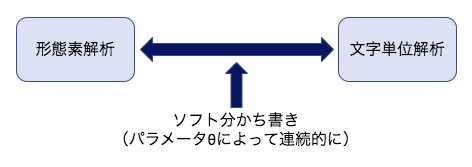
高い汎用性:システムと辞書の分離
4つ目の特徴として、MeCabの高い汎用性についてご説明します。MeCabでは、形態素解析システムと辞書・コーパスは完全に分離されています。そのため、辞書さえあれば日本語だけでなく他の言語の解析も可能であり、様々な分析・研究に応用することができるでしょう。
MeCabのための環境構築
MeCabの特徴については理解していただけたでしょうか。ここからは、MeCabを使って実際に形態素解析をするために、環境を構築していきましょう。本節では、MacOSへのインストール方法とGoogle Colab上での利用方法を解説していきます。(参考:Google Colabの使い方)
※Windowsへのインストール方法については、MeCab公式ホームページをご覧ください。
Macへのインストール方法
本稿の執筆に利用したMacの環境は以下の通りです。
- Mac OS High Sierra 10.13.4
- Anaconda4.8.3
- Python3.6.9
では、インストール手順を順に説明していきます。
1. Homebrewをインストールする
MacOSにMecabをインストールするには、HomebrewというmacOSおよびLinux用のパッケージマネージャーを利用するのが便利です。PCにインストールされていない方は、Homebrewのホームページに記載されているインストール用のコードをターミナルに貼り付けて、実行してください。なお、管理者でログインしていない場合にはインストールできない場合があるのでご注意ください。

2. MeCabおよび形態素解析に必要な辞書をインストールする
Homebrewがインストールできたら、ターミナル上でbrewコマンドを用いてMeCabとメジャーな辞書であるIPA辞書を、pipを用いてPythonからMeCabを呼び出すためのラッパーをインストールしましょう。
$ brew install mecab
$ brew install mecab-ipadic
$ pip install mecab-python3
3. Terminalで動作確認を行う。
インストール完了後に、以下のようにターミナルでpythonを起動し、MeCabをインポートしてエラーが出なければ、準備は完了です。
$ python
import MeCab
4. mecab-ipadic-NEologdのインストール
MeCabの特徴の項目でもご紹介した、最新の語彙に対応している辞書をインストールしましょう。以下のコードの一行目で必要なライブラリをインストールした上で、二行目以下のコードを実行すれば、mecab-ipadic-NEologdをインストールすることができます。
$ brew install mecab mecab-ipadic git curl xz
$ git clone –depth 1 git@github.com:neologd/mecab-ipadic-neologd.git
$ cd mecab-ipadic-neologd
$ ./bin/install-mecab-ipadic-neologd -n
Google Colabでの利用方法
次に、Google Colabでの利用方法について解説します。ここでは、そのままGoogle Colab上で簡単な形態素解析を行います。
まず、Google Colabを開いたら、必要なツールをインストールしていきます。swigとは、C/C++で書かれたプログラムをPythonなどの他の言語に接続するためのツールです。また、Unidic-liteはUnidicという辞書の軽量版です。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
[In ] : # swigのインストール !apt install aptitude swig #MeCabおよびその他の必要なライブラリのインストール !aptitude install mecab libmecab-dev git make curl xz-utils file -y #mecab-python3のインストール !pip install mecab-python3 # Unidic-liteのインストール !pip install unidic-lite |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
[Out ] : Reading package lists... Done Building dependency tree Reading state information... Done The following package was automatically installed and is no longer required: libnvidia-common-440 〜中略〜 Created wheel for unidic-lite: filename=unidic_lite-1.0.6-cp36-none-any.whl size=47560449 sha256=19c5078854a197e6b96a34baad3385180f84b41731e7e6e1a25a7c5970f4ce92 Stored in directory: /root/.cache/pip/wheels/79/94/4a/6af3d97a33e4e8bb1ba013a906f09a36d764bbb80b1a510126 Successfully built unidic-lite Installing collected packages: unidic-lite Successfully installed unidic-lite-1.0.6 |
これで、MeCabをPython上で利用するための準備は整いました。早速、簡単な文で実際に形態素解析を実行してみましょう。MeCabをインポートし、Taggerクラスのインスタンスを作成します。
|
1 2 3 4 5 6 7 |
[In ] : import MeCab mecab = MeCab.Tagger() |
次に、サンプルのテキストデータを作成し、parseToNodeメソッドで形態素解析を行います。
|
1 2 3 4 5 6 7 |
[In ] : sample_text = '先月、ぺこぱのお笑いライブに行ってきた。' node = mecab.parseToNode(sample_text) |
無事に形態素解析ができたら、解析結果を表示する前にデータ構造を確認しましょう。上記のコードで形態素解析をすると、node.surfaceにテキストの形態素が、node.featureに各形態素の特徴が格納されます。次の形態素に移りたいときは、next.nodeをnodeに代入します。1語目は文の開始記号なので、2語目にあたる「先月」とその情報を表示してみましょう。
|
1 2 3 4 5 6 7 8 |
[In ] : node = node.next print(node.surface) print(node.feature) |
|
1 2 3 4 5 6 7 |
[Out ] : 先月 名詞,普通名詞,副詞可能,*,*,*,センゲツ,先月,先月,センゲツ,先月,センゲツ,漢,*,*,*,*,センゲツ,センゲツ,センゲツ,センゲツ,*,*,1,C1,* |
解析後のデータ構造が分かったところで、以下の手順で解析結果を表示しましょう。
- nodeを解析直後の状態に戻す
- while文で繰り返し処理を指示
- node.surfaceに格納されている単語を取得
- node.featureに格納されている単語の情報をカンマで分割し、品詞の情報のみを取得
- 単語と品詞を表示
- node.nextで処理の対象を次の単語に進める
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
[In ] : #1、nodeを解析直後の状態に戻す node = mecab.parseToNode(sample_text) #2、繰り返し処理 while node: #3、単語を取得 word = node.surface #4、品詞を取得 pos = node.feature.split(",")[1] #5、単語と品詞を表示 print('{0} , {1}'.format(word, pos)) #6、次の単語に進める node = node.next |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
[Out ] : , * 先月 , 普通名詞 、 , 読点 ぺこ , * ぱ , 一般 の , 格助詞 お , * 笑い , 普通名詞 ライブ , 普通名詞 に , 格助詞 行っ , 非自立可能 て , 接続助詞 き , 非自立可能 た , * 。 , 句点 , * |
形態素解析の結果を表示することができました。それでは次に、前述の最新語彙対応辞書「mecab-ipadic-NEologd」を利用できるようにしましょう。
|
1 2 3 4 5 6 7 8 |
[In ] : # GitHubからmecab-ipadic-NEologdをダウンロード !git clone --depth 1 https://github.com/neologd/mecab-ipadic-neologd.git !echo yes | mecab-ipadic-neologd/bin/install-mecab-ipadic-neologd -n -a |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
[Out ] : Cloning into 'mecab-ipadic-neologd'... remote: Enumerating objects: 75, done. remote: Counting objects: 100% (75/75), done. remote: Compressing objects: 100% (74/74), done. remote: Total 75 (delta 5), reused 54 (delta 0), pack-reused 0 〜中略〜 Usage: $ mecab -d /usr/lib/x86_64-linux-gnu/mecab/dic/mecab-ipadic-neologd ... [install-mecab-ipadic-NEologd] : Finish.. [install-mecab-ipadic-NEologd] : Finish.. <br> |
|
1 2 3 4 5 6 7 8 9 10 11 |
[In ] : # MeCabがmecab-ipadic-NEologdにアクセスできるよう、パスを通す import subprocess cmd='echo `mecab-config --dicdir`"/mecab-ipadic-neologd"' path = (subprocess.Popen(cmd, stdout=subprocess.PIPE, shell=True).communicate()[0]).decode('utf-8') mecab=MeCab.Tagger("-d {0}".format(path)) |
これで、MeCabがmecab-ipadic-NEologdを参照するようになりました。 それでは、先ほどと同じ文を形態素解析してみましょう。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
[In ] : sample_text = '先月、ぺこぱのお笑いライブに行ってきた。' node = mecab.parseToNode(sample_text) #繰り返し処理 while node: #単語を取得 word = node.surface #品詞を取得 pos = node.feature.split(",")[1] #単語と品詞を表示 print('{0} , {1}'.format(word, pos)) #次の単語に進める node = node.next |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
[Out ] : , * 先月 , 副詞可能 、 , 読点 ぺこぱ , 固有名詞 の , 連体化 お笑いライブ , 固有名詞 に , 格助詞 行っ , 自立 て , 接続助詞 き , 非自立 た , * 。 , 句点 , * |
このような結果になりました。先ほどの結果と比べると、mecab-ipadic-NEologdでは「ぺこぱ」が固有名詞として認識されていることがわかります。このように、新しい語彙にも対応しているので、Twitterなどの新しい語彙が多く出現するテキストデータを分析する場合に有用だと言えるでしょう。一方で、「お笑いライブ」も固有名詞として認識しているなど、いくつかの違いがあります。形態素解析は、利用する辞書によって解析結果が異なるため、分析対象に適した辞書を選択することが重要です。
MeCabによる形態素解析実践
ここでは、MeCabによる形態素解析を活用して、簡単なテキスト分析を実装します。本稿では、先日終了したばかりの東京都知事選挙における、得票数上位の三候補の政策に関する文章を解析し、図示します。
テキストデータの解析
まず、以下の二つのプログラムをインポートしておきましょう。一つ目は、Python標準ライブラリのreモジュールで、テキストデータを正規表現に加工するために使います。もう一つは、Pythonの標準ライブラリであるcollectionsのCounterクラスで、語の出現回数をカウントするために使います。
|
1 2 3 4 5 6 7 |
[In ] : import re from collections import Counter |
それでは、早速形態素解析を行なっていきましょう。用いるテキストデータは、各候補者のウェブサイトの政策に関するページ上のテキストデータです。なお、サイトの画像内のテキストは今回のデータには含んでいません。山本太郎氏のテキストデータに関しては、政策の内容を正確に捉えるため、「>>>より詳しく」の先のページのテキストもデータに含めています。以下に、各候補者の政策ページと本稿で用いるテキストデータのファイルURLを載せておきます。ぜひ、テキストデータをダウンロードして、ご自身の環境で解析してみてください。
※テキストデータはブラウザで開くと文字化けしてしまう場合がありますが、ダウンロードしていただければ問題なく利用していただけます。
参考:各候補者の政策ページと、本稿で用いるテキストデータ(2020年7月3日に作成)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
[In ] : # 小池百合子氏の政策ページ解析 # ファイル読み込み Koike = r'Yuriko_Koike_Policy.txt' with open(Koike) as K: K_text = K.read() #テキストデータの確認 print(K_text) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
[Out ] : 第2波への備え都民の命と健康を守る新型コロナウイルス感染症対策 東京版CDC(疾病対策予防センター)の創設 PCRほか各種検査体制の強化 重症・軽症患者の医療体制の整備 病院・医療従事者へのサポート強化 〜中略〜 都有財産の有効活用促進 3「グレーター東京」(大東京圏)構想の推進 権限・財源セットでの国から地方自治体への権限移譲による地方分権 感染症・災害対策などに備えた広域連携、二重・三重行政の解消 「東京発」規制緩和・岩盤規制突破モデルの構築・推進 |
テキストデータを表示しました。基本的に、テキストを分析する際にはノイズとなりうる記号は削除して綺麗なデータにします。しかし、本稿の分析においては、使用するテキストデータが通常の文章ではなく、箇条書きされている箇所やかっこによって単語が区切られている箇所があります。ゆえに、かっこや数字を取り除いてしまうと形態素が適切に解析されない可能性もあると考え、このまま分析することとします。
|
1 2 3 4 5 6 7 8 9 10 |
[In ] : # Mecab で形態素解析 K_parsed = mecab.parse(K_text) #解析結果の確認 K_parsed |
|
1 2 3 4 5 6 |
[Out ] : 第\t接頭詞,数接続,*,*,*,*,第,ダイ,ダイ\n 〜中略〜 \n推進\t名詞,サ変接続,*,*,*,*,推進,スイシン,スイシン\nEOS\n |
解析結果は上のようになりました。問題なく解析されていますが、このままでは解釈が難しいため、以下の処理を行います。
- 行(\n)単位に分割
- 各行のタブ(\t)を除去
- 名詞・一般に該当する単語をリストに格納
- 出現頻度上位15語を抽出して表示
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
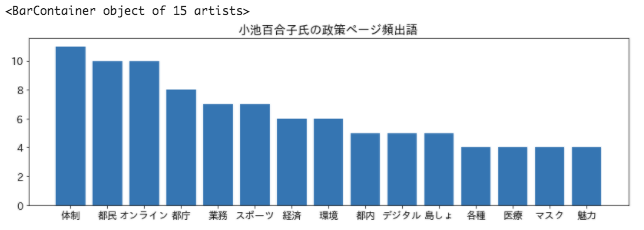
[In ] : #行単位に分割 K_parsed_lines = K_parsed.split('\n') #処理に使うリストを作成 K_parsed_words = [] K_words = [] #各行のタブ(\t)を除去 for K_parsed_line in K_parsed_lines: K_parsed_words.append(re.split('[\t,]', K_parsed_line)) #名詞・一般に該当する単語をリストに格納 for K_parsed_word in K_parsed_words: if ( K_parsed_word[0] not in ('EOS', '') and K_parsed_word[1] == '名詞' and K_parsed_word[2] == '一般'): K_words.append(K_parsed_word[0]) # 出現頻度上位15語を抽出して表示 K_counter = Counter(K_words) for K_word, K_count in K_counter.most_common(15): print('%s : %s' % (K_word, K_count)) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
[Out ] : 体制 : 11 都民 : 10 オンライン : 10 都庁 : 8 業務 : 7 スポーツ : 7 経済 : 6 環境 : 6 都内 : 5 デジタル : 5 島しょ : 5 各種 : 4 医療 : 4 マスク : 4 魅力 : 4 |
小池百合子氏の政策の形態素解析および頻出語の抽出は上記のような結果になりました。このようにテキストデータを分析すれば、これまでテキストデータを読むだけでは得られなかった、より客観的かつ斬新な知見を得られる可能性があることがお分かりいただけたかと思います。
それでは、同様の処理を行った宇都宮健児氏、山本太郎氏の政策頻出語リストも併せてご覧下さい。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
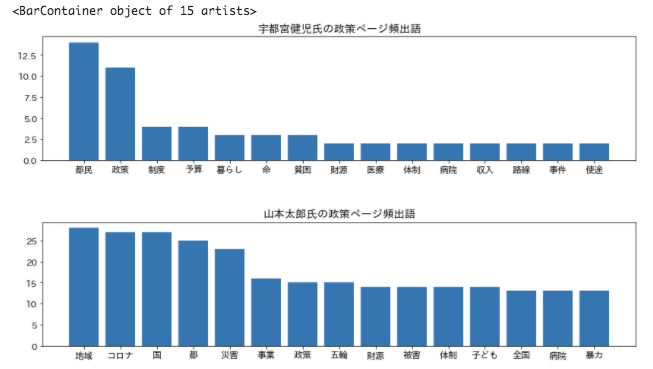
[In ] : # 宇都宮健児氏の政策解析 # ファイル読み込み Utsunomiya = r'Kenji_Utsunomiya_Policy.txt' with open(Utsunomiya) as U: U_text = U.read() # Mecab で形態素解析 U_parsed = mecab.parse(U_text) # 行単位に分割 U_parsed_lines = U_parsed.split('\n') # 処理に使うリストを作成 U_parsed_words = [] U_words = [] # 各行のタブ(\t)を除去 for U_parsed_line in U_parsed_lines: U_parsed_words.append(re.split('[\t,]', U_parsed_line)) # 名詞・一般に該当する単語をリストに格納 for U_parsed_word in U_parsed_words: if ( U_parsed_word[0] not in ('EOS', '') and U_parsed_word[1] == '名詞' and U_parsed_word[2] == '一般'): U_words.append(U_parsed_word[0]) # 出現頻度上位15語を抽出して表示 U_counter = Counter(U_words) for U_word, U_count in U_counter.most_common(15): print('%s : %s' % (U_word, U_count)) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
[Out ] : 都民 : 14 政策 : 11 制度 : 4 予算 : 4 暮らし : 3 命 : 3 貧困 : 3 財源 : 2 医療 : 2 体制 : 2 病院 : 2 収入 : 2 路線 : 2 事件 : 2 使途 : 2 |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
[In ] : # 山本太郎氏の政策解析 # ファイル読み込み Yamamoto = r'Taro_Yamamoto_Policy.txt' with open(Yamamoto) as Y: Y_text = Y.read() # Mecab で形態素解析 Y_parsed = mecab.parse(Y_text) # 行単位に分割 Y_parsed_lines = Y_parsed.split('\n') # 処理に使うリストを作成 Y_parsed_words = [] Y_words = [] # 各行のタブ(\t)を除去 for Y_parsed_line in Y_parsed_lines: Y_parsed_words.append(re.split('[\t,]', Y_parsed_line)) # 名詞・一般に該当する単語をリストに格納 for Y_parsed_word in Y_parsed_words: if ( Y_parsed_word[0] not in ('EOS', '') and Y_parsed_word[1] == '名詞' and Y_parsed_word[2] == '一般'): Y_words.append(Y_parsed_word[0]) # 出現頻度上位15語を抽出して表示 Y_counter = Counter(Y_words) for Y_word, Y_count in Y_counter.most_common(15): print('%s : %s' % (Y_word, Y_count)) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
[Out ] : 地域 : 28 コロナ : 27 国 : 27 都 : 25 災害 : 23 事業 : 16 政策 : 15 五輪 : 15 財源 : 14 被害 : 14 体制 : 14 子ども : 14 全国 : 13 病院 : 13 暴力 : 13 |
解析結果の図示
次に、上記の解析結果を簡単に棒グラフで図示したいと思います。matplotlibで日本語を表示するために必要なjapanize-matplotlibをインストールした上で、他の必要なライブラリと合わせてインポートします。
※1:japanize-matplotlibは、インポートする際にはハイフンをアンダーバーにする必要があります。ご注意ください。
※2:japanize-matplotlibの綴りにご注意ください。japaneseではありません。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
[In ] : #japanize-matplotlibのインストール !pip install japanize-matplotlib #必要なライブラリのインポート import pandas as pd import matplotlib.pyplot as plt %matplotlib inline import japanize_matplotlib |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
[Out ] : Collecting japanize-matplotlib Downloading https://files.pythonhosted.org/packages/2c/aa/3b24d54bd02e25d63c8f23bb316694e1aad7ffdc07ba296e7c9be2f6837d/japanize-matplotlib-1.1.2.tar.gz (4.1MB) |████████████████████████████████| 4.1MB 2.6MB/s Requirement already satisfied: matplotlib in /usr/local/lib/python3.6/dist-packages (from japanize-matplotlib) (3.2.2) Requirement already satisfied: numpy>=1.11 in /usr/local/lib/python3.6/dist-packages (from matplotlib->japanize-matplotlib) (1.18.5) 〜中略〜 Installing collected packages: japanize-matplotlib Successfully installed japanize-matplotlib-1.1.2 /usr/local/lib/python3.6/dist-packages/japanize_matplotlib/japanize_matplotlib.py:15: MatplotlibDeprecationWarning: The createFontList function was deprecated in Matplotlib 3.2 and will be removed two minor releases later. Use FontManager.addfont instead. font_list = font_manager.createFontList(font_files) |
|
1 2 3 4 5 6 7 |
[In ] : # 使用するデータを確認 print(K_counter.most_common(15)) |
|
1 2 3 4 5 6 |
[Out ] : [('体制', 11), ('都民', 10), ('オンライン', 10), ('都庁', 8), ('業務', 7), ('スポーツ', 7), ('経済', 6), ('環境', 6), ('都内', 5), ('デジタル', 5), ('島しょ', 5), ('各種', 4), ('医療', 4), ('マスク', 4), ('魅力', 4)] |
データを確認したところ、語と出現数がセットで格納されているので、グラフ化しやすいようにpandasのデータフレームに変換します。
|
1 2 3 4 5 6 7 8 |
[In ] : # データフレームに変換し、確認 K_df = pd.DataFrame(K_counter.most_common(15)) print(K_df) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
[Out ] : 0 1 0 体制 11 1 都民 10 2 オンライン 10 3 都庁 8 4 業務 7 5 スポーツ 7 6 経済 6 7 環境 6 8 都内 5 9 デジタル 5 10 島しょ 5 11 各種 4 12 医療 4 13 マスク 4 14 魅力 4 |
それでは、実際に棒グラフで図示してみましょう。他の二候補者のグラフと併せてご覧下さい。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
[In ] : # データを変数に格納 x1 = K_df[0] y1 = K_df[1] # グラフのサイズ、ラベルの文字サイズを指定 fig = plt.figure(figsize=(14.0,4.0)) fig = plt.rcParams["font.size"]=13 # 棒グラフで図示 plt.title("小池百合子氏の政策ページ頻出語") plt.bar(x1,y1) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
[In ] : # グラフのサイズ、グラフ同士の間隔、ラベルの文字サイズを指定 fig = plt.figure(figsize=(14.0,8.5)) fig = plt.subplots_adjust(hspace = 0.5) fig = plt.rcParams["font.size"]=13 #宇都宮健児氏の政策 plt.subplot(2,1,1) # データフレームに変換 U_df = pd.DataFrame(U_counter.most_common(15)) # データを変数に格納 x2 = U_df[0] y2 = U_df[1] # 棒グラフで図示 plt.title("宇都宮健児氏の政策ページ頻出語") plt.bar(x2,y2) #山本太郎氏の政策 plt.subplot(2,1,2) # データフレームに変換 Y_df = pd.DataFrame(Y_counter.most_common(15)) # データを変数に格納 x3 = Y_df[0] y3 = Y_df[1] # 棒グラフで図示 plt.title("山本太郎氏の政策ページ頻出語") plt.bar(x3,y3) |
まとめ
いかがでしたでしょうか。形態素解析の概要とMeCabの特徴の説明、そして形態素解析の実装と盛りだくさんの内容となりましたが、少しでも形態素解析についての理解が深められていれば幸いです。しかし、形態素解析は自然言語処理という大きな分野の一技術です。形態素解析の後のプロセスとして、構文解析・意味解析・文脈解析と、まだまだこの分野には学ぶべき内容が数多くありますので貪欲に学びを深めていきましょう。


こんにちは、mecab-python3の開発者です。
「必要なライブラリー」のところですが、mecab-python3を使う場合、基本的になにかを事前にインストールする必要はありません。2018年以前にその必要はありましたが、v0.996.1からwheelを提供していますので、pip install mecab-python3だけでインストールできます。