
皆さんは、scikit-learn(よみ:サイキット・ラーン)をご存知でしょうか。Pythonを使っている方、機械学習を学ばれている方なら一度は耳にしたことがあることでしょう。しかし、scikit-learnを知っている方の中でも、scikit-learnでいったい何ができるのか、その全貌を知っている方はそれほど多くはないのではないでしょうか。
そこで本稿では、scikit-learnの4つの特徴と、6つの主な機能について詳しく解説した上で、実際に回帰と分類の実装を行います。機械学習をこれから学ぼうとされている方はもちろん、scikit-learnを使っている皆さんも改めて、本稿でscikit-learnの良さを学びましょう。
scikit-learnとは
まずは、scikit-learnとはいったいどのようなライブラリで、どのような特徴があるのかを解説していきます。
scikit-learnの概要
scikit-learnは、オープンソースの機械学習ライブラリです。2007年にGoogle Summer of Code projectとしてDavid Cournapeau氏によって開発が始められ、今日でも国際的なコミュニティーの元で開発が続けられています。Numpy、SciPy、matplotlibといったPythonのライブラリ上で動作し、scikit-learnを使えば、誰でも手軽に機械学習の前処理やモデリング、評価指標の算出などを行うことができます。
scikit-learnの4つの特徴
次に、scikit-learnの4つの特徴について、詳しく説明していきます。なお、ここで説明する4つの特徴については、後半の実装の際にも再度確認します。
①アルゴリズムが豊富かつ使いやすい
1つ目の特徴は、アルゴリズムが豊富に用意されており、かつ使いやすいという点です。scikit-learnには、回帰、分類、クラスタリング、次元削減など、あらゆる分野のアルゴリズムが揃っています。また、同じ分野のアルゴリズムは実装の際のコードに共通性があり、様々なアルゴリズムを容易に使い分けることができるようになっています。
②アルゴリズムチートシートを参考に、簡単に適切な手法を選択できる
2つ目の特徴は、チートシートを参考にして簡単にアルゴリズムを選択できる点です。用意されているアルゴリズムがどれだけ豊富でも、どの手法を用いればいいのか分からなければ意味がありませんね。しかし、アルゴリズムのメカニズムは複雑であるため、どの手法を用いるのが適切なのかを知るためにあらゆる手法について詳しく学んでいては、いつまでたっても機械学習を実践することはできないでしょう。そんな悩みを解決してくれるのが下のアルゴリズムチートシートです。
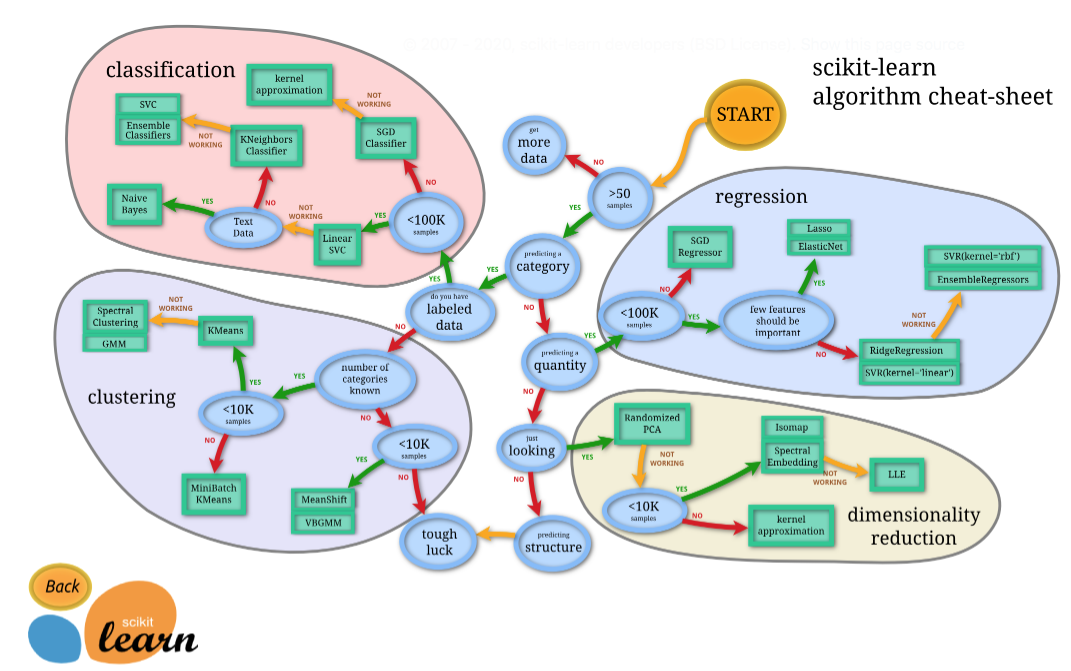
<scikit-learn公式より>
右上の「START」から、用いるデータの特徴に関するYesかNoの二択の選択肢を辿っていくと、データに合ったアルゴリズムを選択することができます。このチートシートを使うことで、全てのアルゴリズムに精通していなくても、機械学習の実装を試しながら学んでいくことができます。(※チートシートでは、scikit-learn内のアルゴリズムの一部しか紹介されていません。ゆえに、ある程度適切ではあるものの最適なアルゴリズムではない可能性があります。各分野のアルゴリズムの知識が付いてきたら自分で適切な手法を選択するようにしましょう。)
③サンプルのデータセットが用意されている
3つ目の特徴は、scikit-learnにはサンプルのデータセットが用意されている点です。機械学習を始める前に、学習に用いるデータを用意しなければいけません。今日では、多くのデータセットがインターネット上で公開されているため、それらを活用するというのも一つの手段ではあります(参考:機械学習データセット24選!)。しかし、整形されたデータですぐに機械学習を実装してみたい場合もあるでしょう。そんな時には、scikit-learnに用意されているデータセットを使うことをお勧めします。scikit-learnに用意されているデータセットは使いやすいように整形されているため、前処理に余計な手間がかかりません。また、ボストンの住宅価格、アヤメの種類、糖尿病患者、手書き数字など、様々な種類のデータが用意されているため、試してみたいアルゴリズムに合わせてデータを選択することも可能になっています。<参考: [ 公式 ]scikit-learnのデータセット一覧(英語)>
④公式サイトの解説が丁寧で便利
公式Webサイトの解説が非常に丁寧で便利であることも、scikit-learnの特徴の一つと言えるでしょう。ユーザーガイドには、scikit-learnの各アルゴリズムについて、仕組みや各モジュール・各クラスごとの引数の解説、実装例などが載せられています。これを参照すればオーソドックスな使い方はスムーズに習得できるでしょう。
scikit-learnの6つの機能
scikit-learnとはどのようなライブラリで、どのような特徴があるのかお分かりいただけたでしょうか。本節では、scikit-learnの6つの具体的な機能について、機械学習の知識に関する解説も交えながらご説明します。
回帰
1つ目の機能が回帰です。回帰とは、二種類ある教師あり学習のうちの一つで、データセットを学習して新たな入力に対する出力の数値を予測する手法のことです。例えば、過去の気象データと位置情報を学習し、その地点の翌日の気温を予測する際には回帰を行います。また、本稿後半の実装では、ボストンの住宅価格のデータセットを用いて、町の犯罪率や高速道路へのアクセスの良さなどのデータから土地の住宅価格を予測する回帰を行います。
分類
2つ目の機能が分類です。分類はもう一つの教師あり学習で、データを学習して、新たな入力に対する出力のラベルを予測する手法のことです。回帰と同様に気象に関して例えるならば、過去の気象データと位置情報を学習し、その地点の翌日の天気(晴れ、曇り、雨、雪)を予測するのは、分類です。また、本稿の後半では、アヤメのデータセットを用いて、アヤメの花びらやがくの大きさから、そのアヤメがどの種類なのかを予測する分類を行います。
- 線形モデル
- サポートベクターマシン
- 確率的勾配降下法
- 最近傍
- ガウス過程
- 決定木
- アンサンブル学習
- ニューラルネットワーク
クラスタリング
3つ目の機能は教師なし学習のクラスタリングです。クラスタリングとは、データの特徴から関連の深いデータや似通ったデータを見つけ、クラスターに分ける(=グルーピングする)手法です。例えば、企業の購買データの分析などに応用されていて、クラスタリングの結果に基づいて顧客に商品をレコメンドすることもあります。scikit-learnでは、クラスタリングもK-meansをはじめ数多くのアルゴリズムで実行可能です。
次元削減
4つ目の機能は次元削減です。次元削減は教師なし学習の一種です。データセットの特徴量同士の関係を学習し、より簡潔かつ効率的に特徴量の情報を表現することなどを目的に、新たな特徴量を計算で導出して特徴量の数を削減する手法です。例えば、近年盛んに様々なメディアで取り上げられているビッグデータを処理する際に、データセットのあまりの大きさにコンピュータの処理性能が不足することがあります。そういった場合に、次元削減をすることでコンピュータの性能不足を補うことができます。scikit-learnでは、主成分分析や因子分析などで次元削減を行うことができます。
データの前処理
5つ目の機能はデータの前処理です。データの前処理といっても、pandasで行うようなデータの整形ではなく、機械学習が正しく実行されるためのデータの数値変換を行います。適切な前処理を行うことで、特定の特徴量が学習結果に過大な影響を与えることなどを防ぐことができます。例えば、データの平均を0、標準偏差を1にする標準化などを行います。なお、scikit-learnでは他にも、非線型変換や正規化、離散化などの処理を行うことができます。
モデルの評価と選択
scikit-learnを使うための準備
次に、scikit-learnを使うための準備について、簡単にご説明します。
pipでインストールする場合
パッケージマネージャーのpipを用いる場合、WindowsユーザーもMacユーザーも、手順は同じです。まず、Pythonの公式サイトからPythonをインストールしましょう。そのあと、ターミナル(Windowsの場合はコマンドプロンプト)に
pip install -U scikit-learn
と入力することでscikit-learnをPythonで使うことができます。なお、
python -m pip show scikit-learn
と入力した際にscikit-learnのバージョンとインストール先が表示されれば、インストールは正常に完了しています。
Google Colabの場合
インストールするよりもお手軽にscikit-learnを使ってみたい方には、Google Colabがおすすめです。Google Colabにはscikit-learnが元から用意されているため、ノートブックを作成したらすぐに利用可能です。(参考:Google Colabの使い方)
なお、pipではなくcondaでPCにインストールしたい方や、Linuxをご利用の方は、scikit-learn公式サイトをご確認ください。
scikit-learnによる機械学習実装
いよいよ、scikit-learnを用いた機械学習の実装に取り掛かります。本稿では、皆さんにscikit-learnで実装可能な機械学習手法の豊富さや、チートシートの利便性、scikit-learnに用意されているデータセットの内容について知っていただくため、以下のような流れで実装を行います。
0. ライブラリ・データセットの準備
1. 分類の実装(iris(アヤメ)データセット)
2. 回帰とモデル選択の実装(ボストン住宅価格データセット)
まずは、ライブラリとデータセットの準備から行いましょう。
ライブラリ・データセットの準備
本稿の実装では、pandasとscikit-learnを用います。pandasは効率的にデータを処理・整形するためのライブラリです。また、scikit-learnから、本稿の実装で用いるアヤメ(iris)のデータセットと、ボストンの住宅価格のデータセットをインポートしておきましょう。
|
1 2 3 4 5 6 7 8 |
[In ] : #必要なライブラリとデータセットをインポート import pandas as pd import sklearn from sklearn.datasets import load_iris, load_boston |
分類の実装(iris(アヤメ)データセット)
アヤメの種類に関するデータセットで、アヤメの種類の予測を行います。まずは、データを読み込んで中身を確認した後に、訓練データとテストデータに分割しましょう。
データの確認と分割
|
1 2 3 4 5 6 7 8 9 10 |
[In ] : #irisデータセットの読み込み iris = load_iris() #特徴量をデータフレームに格納して、最初の五行を表示 iris_features = pd.DataFrame(data = iris.data, columns = iris.feature_names) iris_features.head() |
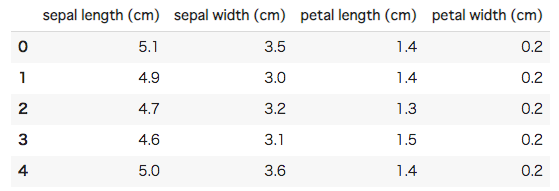
特徴量の最初の五行を表示してみました。sepalというのが「がく」で、petalというのが「花弁(花びら)」に当たります。がくと花弁それぞれの長さと幅から、アヤメの種類を当てる分類問題を解くためのデータセットになっています。

次に、特徴量の基本統計量を確認しましょう。
|
1 2 3 4 5 6 |
[In ] : #特徴量の基本統計量を確認 iris_features.describe() |
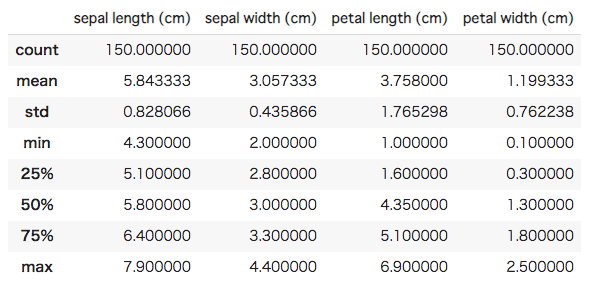
上記の表では、上から順にデータ数、平均値、標準偏差、最小値、第1四分位数、中央値、第3四分位数、最大値が表示されています。これらの情報から、データに対して具体的なイメージを持つことができ、明らかにおかしいデータが含まれていないかを確認することもできます。さらに、特徴量に欠損値がないかも一応確認してみましょう。
|
1 2 3 4 5 6 |
[In ] : #特徴量の欠損値の数を確認 iris_features.isnull().sum() |
|
1 2 3 4 5 6 7 8 9 |
[Out ] : sepal length (cm) 0 sepal width (cm) 0 petal length (cm) 0 petal width (cm) 0 dtype: int64 |
基本統計量を表示した際にcount(データ数)が全て150だったことから予想はつきましたが、やはり欠損値はないようです。このように、扱いやすくデータが整形されているのもサンプルデータセットの特徴です。それでは、ラベルも確認してみましょう。
|
1 2 3 4 5 6 7 8 9 |
[In ] : #ラベルをシリーズに格納 iris_label =pd.Series(iris.target) #ラベルごとのデータ数を表示 iris_label.value_counts() |
|
1 2 3 4 5 6 7 8 |
[Out ] : 2 50 1 50 0 50 dtype: int64 |
0、1、2のラベルがそれぞれ50ずつあるようですね。これらの数字はそれぞれがアヤメの種類に対応しています。
データセットの中身が確認できたところで、model_selectionモジュールのtrain_test_splitメソッドを用いて、データを訓練データとテストデータに分割しましょう。train_test_splitの引数には、前から順に特徴量、ラベル、テストデータにする割合、再現性を持たせるため乱数生成のシードを指定するrandom_state引数を入力します。
|
1 2 3 4 5 6 7 |
[In ] : #学習データとテストデータに分割 from sklearn.model_selection import train_test_split features_train, features_test, label_train, label_test = train_test_split(iris_features, iris_label,test_size =0.5, random_state=0) |
分割した訓練データとテストデータの構造を確認してみましょう
|
1 2 3 4 5 6 7 8 9 |
[In ] : #学習データとテストデータの構造を確認 print(features_train.shape) print(features_test.shape) print(label_train.shape) print(label_test.shape) |
|
1 2 3 4 5 6 7 8 |
[Out ] : (75, 4) (75, 4) (75,) (75,) |
特徴量は75行4列、ラベルは75行1列に分割できていることがわかります。
分類のモデル実装
いよいよ、分類のためのモデルを実装していきます。と言っても、選べるモデルは非常に豊富であるため、ここでは先ほどご紹介したチートシートを活用してみましょう。
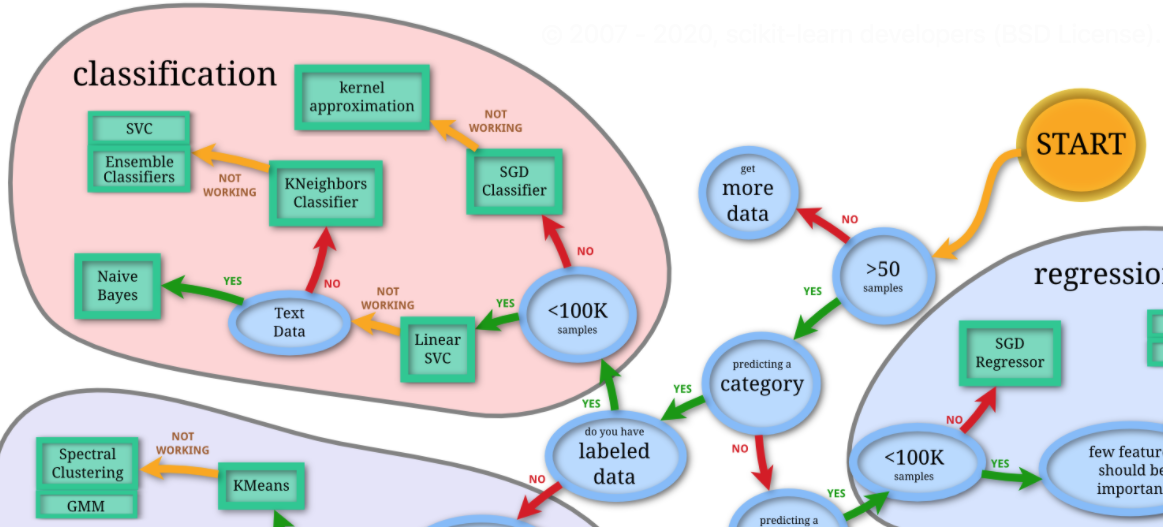
右上のSTARTから順に辿っていくと、今回の場合はSTART→Yes→Yes→Yes→Yesとなり、Linear SVCが推奨されました。早速svm(サポートベクターマシン)モジュールをインポートし、LinearSVCクラスのインスタンスを作成してfitメソッドで学習させましょう。先ほどのデータの分割と同様に、何回やっても、どの環境で実行しても結果が同じになるように、インスタンス作成時にrandom_state引数を指定します。また最大のイテレーション回数を指定するmax_iter引数へ3000と指定します。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
[In ] : #必要なモジュールをインポート from sklearn import svm #LinearSVMのインスタンスを作成 Linsvc = svm.LinearSVC(random_state=0, max_iter=3000) #LinearSVMでデータを学習 Linsvc.fit(features_train,label_train) |
|
1 2 3 4 5 6 7 8 |
[Out ] : LinearSVC(C=1.0, class_weight=None, dual=True, fit_intercept=True, intercept_scaling=1, loss='squared_hinge', max_iter=3000, multi_class='ovr', penalty='l2', random_state=0, tol=0.0001, verbose=0) |
モデルにデータを学習させたので、アヤメの種類を予測します。予測には、LinearSVCのインスタンスのpredictメソッドを用います。
|
1 2 3 4 5 6 7 |
[In ] : #LinearSVMでアヤメの種類を予測 label_pred_Linsvc = Linsvc.predict(features_test) print(label_pred_Linsvc) |
|
1 2 3 4 5 6 7 |
[Out ] : [2 1 0 2 0 2 0 1 1 1 2 1 1 1 1 0 1 1 0 0 2 2 0 0 2 0 0 1 1 0 2 2 0 2 2 1 0 2 1 1 2 0 2 0 0 1 2 2 1 2 1 2 2 1 2 2 2 2 1 2 2 0 2 1 1 1 1 2 0 0 2 1 0 0 1] |
無事に予測ができましたが、試しにチートシート上でLinearSVCがうまく予測できない場合に推奨されているK近傍法(Kneighbor)と、オーソドックスな分類手法であるロジスティック回帰モデル(LogisticRegression)でもそれぞれ分類予測を行います。先ほどのLinearSVCでの分類予測とコードが類似している点にもご注目ください。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
[In ] : #必要なモジュールをインポート from sklearn.neighbors import KNeighborsClassifier #K近傍法のインスタンスを作成 Kneighbor = KNeighborsClassifier(n_neighbors=5) #K近傍法でデータを学習 Kneighbor.fit(features_train,label_train) #K近傍法でアヤメの種類を予測 label_pred_KNeighbor = Kneighbor.predict(features_test) print(label_pred_KNeighbor) |
|
1 2 3 4 5 6 7 |
[Out ] : [2 1 0 2 0 2 0 1 1 1 2 1 1 1 1 0 1 1 0 0 2 1 0 0 2 0 0 1 1 0 2 1 0 2 2 1 0 2 1 1 2 0 2 0 0 1 2 2 1 2 1 2 1 1 2 2 1 2 1 2 1 0 2 1 1 1 1 2 0 0 2 1 0 0 1] |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
[In ] : #(参考) #必要なモジュールをインポート from sklearn.linear_model import LogisticRegression #ロジスティック回帰のインスタンスを作成 LogReg = LogisticRegression(random_state=0) #ロジスティック回帰でデータを学習 LogReg.fit(features_train,label_train) #ロジスティック回帰でアヤメの種類を予測 label_pred_LogReg = LogReg.predict(features_test) print(label_pred_LogReg) |
|
1 2 3 4 5 6 7 |
[Out ] : [2 1 0 2 0 2 0 1 1 1 2 1 1 1 1 0 1 1 0 0 2 1 0 0 1 0 0 1 1 0 2 1 0 2 2 1 0 2 1 1 2 0 2 0 0 1 2 2 1 2 1 2 1 1 2 1 1 2 1 2 1 0 2 1 1 1 1 2 0 0 2 1 0 0 1] |
3つのモデルで予測ができたので、今度はそれぞれの予測モデルの性能を比較してみましょう。そのための評価指標として、今回は正解率(accuracy)を用い、混同行列と併せて表示します。正解率は、全ての予測のうち、正しく分類できていた予測の割合を表します。また、混同行列は、実際のラベルと予測のラベルを行列形式で表示したものです。(混同行列や分類問題におけるその他の評価指標について詳しく知りたい方は、評価指標の記事も併せてご覧ください。)
|
1 2 3 4 5 6 7 8 |
[In ] : #LinearSVMによる予測の混同行列、正解率を表示 from sklearn.metrics import confusion_matrix print('confusion matrix = \n', confusion_matrix(y_true = label_test, y_pred = label_pred_Linsvc)) print('accuracy = ', Linsvc.score(features_test,label_test)) |
|
1 2 3 4 5 6 7 8 9 |
[Out ] : confusion matrix = [[21 0 0] [ 0 25 5] [ 0 1 23]] accuracy = 0.92 |
|
1 2 3 4 5 6 7 8 |
[In ] : #K近傍法による分類の混同行列、正解率を表示 from sklearn.metrics import confusion_matrix print('confusion matrix = \n', confusion_matrix(y_true = label_test, y_pred = label_pred_KNeighbor)) print('accuracy = ', Kneighbor.score(features_test,label_test)) |
|
1 2 3 4 5 6 7 8 9 |
[Out ] : confusion matrix = [[21 0 0] [ 0 29 1] [ 0 2 22]] accuracy = 0.96 |
|
1 2 3 4 5 6 7 8 |
[In ] : #(参考)ロジスティック回帰による分類の混同行列、正解率を表示 from sklearn.metrics import confusion_matrix print('confusion matrix = \n', confusion_matrix(y_true = label_test, y_pred = label_pred_LogReg)) print('accuracy = ', LogReg.score(features_test,label_test)) |
|
1 2 3 4 5 6 7 8 9 |
[Out ] : confusion matrix = [[21 0 0] [ 0 29 1] [ 0 4 20]] accuracy = 0.9333333333333333 |
この混同行列は、左上から右下への対角線上に位置する要素が正解した予測の数になっています。正解率と合わせてみても、今回の分類ではK近傍法が最もうまく予測できていると言えそうです。K近傍法はオーソドックスなロジスティック回帰モデルと比べても性能がよかったことから、チートシートの有用性をお分かりいただけるかと思います。
回帰とモデル選択の実装(ボストン住宅価格データセット)
次に、ボストンの住宅価格に関するデータセットを用いて、回帰を行い、住宅価格を予測します。さらに、モデル選択についての手法であるクロスバリデーションも適用します。まずは、先ほどと同様にデータの中身を確認したあと、訓練データとテストデータに分割します。
データの確認
データセットの読み込みと、最初の5行の表示から始めましょう。
|
1 2 3 4 5 6 7 8 9 10 |
[In ] : #ボストン住宅価格データセットを読み込み boston = load_boston() #特徴量をデータフレームに格納して、最初の五行を表示 boston_features = pd.DataFrame(data = boston.data, columns = boston.feature_names) boston_features.head() |
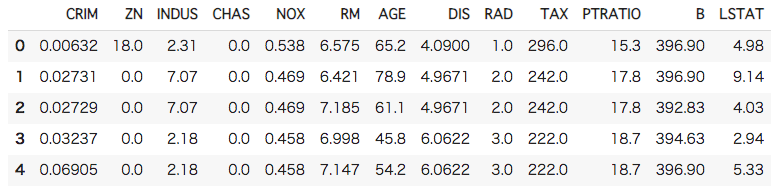
先ほどよりも特徴量が多く、数値の単位も様々であることがわかります。それぞれの変数の意味は以下の通りです。
- CRIM 町の人口あたり犯罪率
- ZN 25000平方フィート以上の住宅地の割合
- INDUS 町ごとの非小売業の土地の割合
- CHAS Charles川に関するダミー変数(川に接していたら1、そうでなければ0)
- NOX 一酸化窒素濃度(1000万分の1)
- RM 住居当たりの平均部屋数
- AGE 1940年より前に建設された物件の割合
- DIS ボストンの5つの雇用センターまでの重み付けされた距離
- RAD 放射状高速道路へのアクセスしやすさ
- TAX 10000ドル当たりの固定資産税総額
- PTRATIO 町ごとの生徒と教師の比率
- B 1000(Bk – 0.63)^2 ※Bkは町の黒人比率
- LSTAT 低所得の人々の割合
次に、基本統計量を表示して全体像を掴みましょう。
|
1 2 3 4 5 6 |
[In ] : #特徴量の基本統計量を確認 boston_features.describe() |
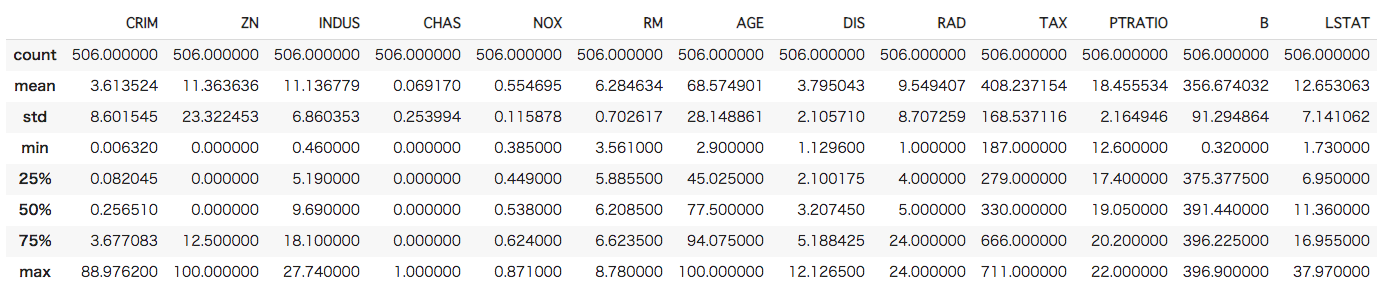
犯罪率や住宅地比率だけをみても、町ごとの性質に大きな差があることがわかります。このデータでも一応欠損値の有無を確認しておきましょう。
|
1 2 3 4 5 6 |
[In ] : #特徴量の欠損値の数を確認 boston_features.isnull().sum() |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
[Out ] : CRIM 0 ZN 0 INDUS 0 CHAS 0 NOX 0 RM 0 AGE 0 DIS 0 RAD 0 TAX 0 PTRATIO 0 B 0 LSTAT 0 dtype: int64 |
やはり欠損値はありません。スムーズに学習に入れるため非常にありがたいですね。次に、ターゲットをpandasのSeriesというデータ構造に格納して基本統計量を確認します。
|
1 2 3 4 5 6 7 8 9 |
[In ] : #ターゲットをシリーズに格納 boston_target = pd.Series(data = boston.target) #ターゲットの基本統計量を確認 boston_target.describe() |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
[Out ] : count 506.000000 mean 22.532806 std 9.197104 min 5.000000 25% 17.025000 50% 21.200000 75% 25.000000 max 50.000000 dtype: float64 |
こちらも、最小値と最大値で10倍もの差がありますね。グラフにしてみても面白いですが、本稿では割愛します。Pythonでの可視化については、seabornの記事で詳しく解説していますので、ぜひご覧ください。最後に、先ほどと同様にデータを学習データとテストデータに分割します。
|
1 2 3 4 5 6 7 |
[In ] : #学習データとテストデータに分割 from sklearn.model_selection import train_test_split features_train, features_test, target_train, target_test = train_test_split(boston_features, boston_target,test_size =0.5, random_state=0) |
回帰のモデル実装
では、回帰のモデルを実装していきましょう。回帰でも、チートシートを参考にアルゴリズムを選択します。
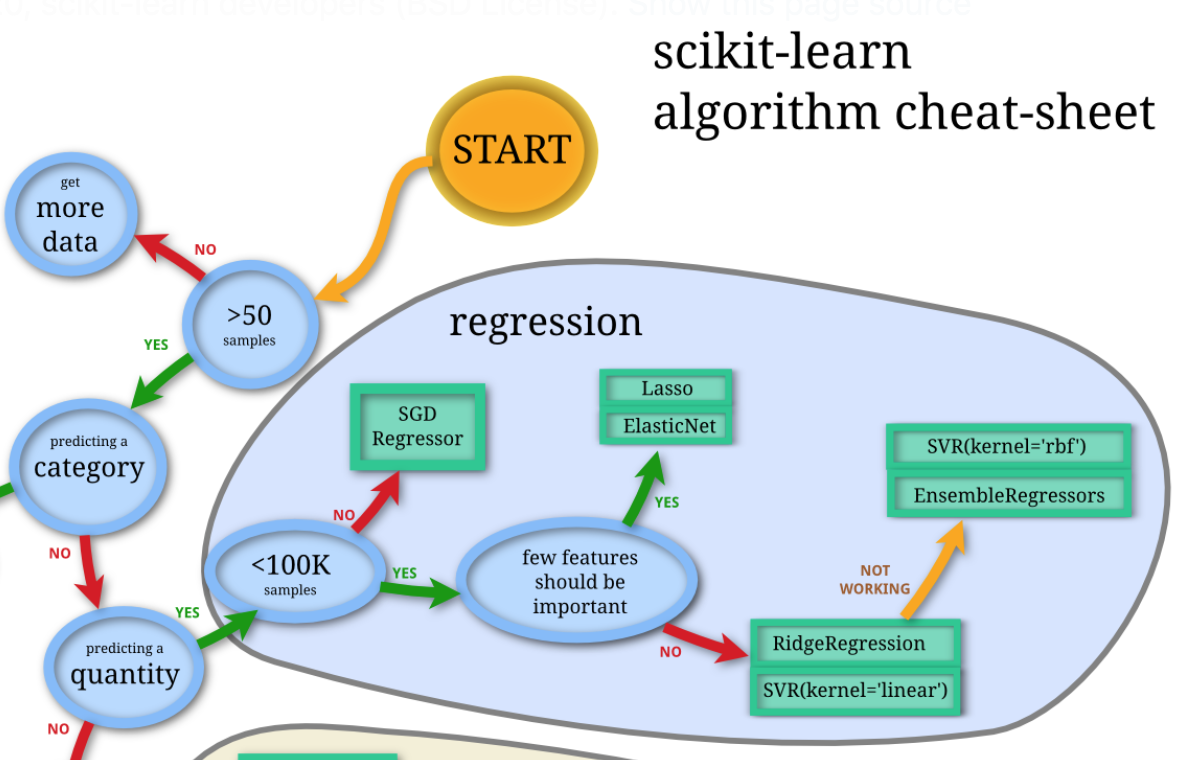
今度はSTART→Yes→No→Yes→Yesとなりfew features should be important(少数の特徴量が重要である)まで来ました。この質問に関しては、データを確認しただけでは判断がつかないため、YesとNoの先のアルゴリズムからひとつずつ、LassoとRidgeRegressionを選んで実装することとします。また、参考に通常の線形回帰モデルでも予測を行います。なお、本稿では、各アルゴリズムのインスタンスを作成する際の引数には、scikit-learnの公式サイトで紹介されている例を参考に、同じ値を入れることとします。各アルゴリズムの引数についてより詳しく知りたい方は、scikit-learn公式サイトをご確認ください。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
[In ] : #必要なモジュールをインポート from sklearn.linear_model import Lasso #Lassoモデルのインスタンスを作成 Lasso = Lasso(alpha=0.1,random_state=0) #Lassoモデルで学習 Lasso.fit(features_train,target_train) #学習させたLassoモデルで住宅価格を予測 target_pred_Lasso = Lasso.predict(features_test) print(target_pred_Lasso) |
|
1 2 3 4 5 |
[Out ] : [24.92016544 24.37622341 28.73960915 12.65498587 20.12822066 <中略> 32.41046412 12.86124324 -1.09808088 19.11209164 13.77278576] |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
[In ] : #必要なモジュールをインポート from sklearn.linear_model import Ridge #Ridgeモデルのインスタンスを作成 Ridge = Ridge(alpha=0.5,random_state=0) #Ridgeモデルで学習 Ridge.fit(features_train,target_train) #Ridgeモデルで住宅価格を予測 target_pred_Ridge = Ridge.predict(features_test) print(target_pred_Ridge) |
|
1 2 3 4 5 6 |
[Out ] : [24.80360943 24.73539403 30.39780122 12.40553362 20.79803971 <中略> 32.56969078 12.79231805 0.23770741 19.38262706 14.66214473] |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
[In ] : #(参考) #必要なモジュールをインポート from sklearn.linear_model import LinearRegression #線形モデルのインスタンスを作成 LinReg = LinearRegression() #線形モデルで学習 LinReg.fit(features_train,target_train) #線形モデルで住宅価格を予測 target_pred_LinReg = LinReg.predict(features_test) print(target_pred_LinReg) |
|
1 2 3 4 5 |
[Out ] : [24.70960325 25.12631354 30.76503263 12.41405512 21.29599499 <中略> 32.60489109 12.78765107 1.20660832 19.44277125 15.3198648 ] |
3つのモデルで予測ができたところで、モデルの性能を評価するために評価指標を計算します。ここでは、決定係数を用いることとします。なお、決定係数とは、簡単に言えば「実際の値のうち予測モデルで説明できた割合」を表す評価指標で0〜1の範囲で変動し、大きければ大きいほどモデルの性能がいいということになります。
|
1 2 3 4 5 6 |
[In ] : #Lassoモデルによる回帰の評価(決定係数の表示) print("R-squared : ",Lasso.score(features_test,target_test)) |
|
1 2 3 4 5 |
[Out ] : R-squared : 0.6537204778207004 |
|
1 2 3 4 5 6 |
[In ] : #Ridgeモデルによる回帰の評価(決定係数の表示) print("R-squared : ",Ridge.score(features_test,target_test)) |
|
1 2 3 4 5 |
[Out ] : R-squared : 0.6625759807022442 |
|
1 2 3 4 5 6 |
[In ] : #(参考)線形モデルによる回帰の評価(決定係数の表示) print("R-squared : ",LinReg.score(features_test,target_test)) |
|
1 2 3 4 5 |
[Out ] : R-squared : 0.6662719929919441 |
今回は、モデル間で性能に大差はないという結果になりました。線形モデルが最も性能が良かったですが、チートシートにしたがって用いた二つのモデルもまずまずの性能を出せたと言えるでしょう。
モデルの評価と選択:クロスバリデーション(交差検証) の実装
ここまで、scikit-learnの機能のうち、「分類」と「回帰」の実装について解説して来ました。ここでは、もうひとつの機能を簡単に実装してみたいと思います。それは、「モデルの評価と選択」のための機能です。実をいうと、データセットの訓練データ・テストデータへの分割や、分類の評価のところで表示した混同行列もこの機能によるものです。ここではクロスバリデーション(交差検証)という手法をご紹介します。
クロスバリデーションとは、データセットを訓練データとテストデータに分割してモデルに学習させてスコアを出すというプロセスを複数回繰り返し、全てのスコアの平均で性能を測ることで、より一般的な予測性能が高いモデルを選択するという手法です。例えば先ほどの回帰の例でいうと、この手法を用いることで、たまたまLassoモデルには不利な形でデータセットが分割されたためにLassoモデルの性能が低くなってしまったというケースを回避できる可能性が高まります。
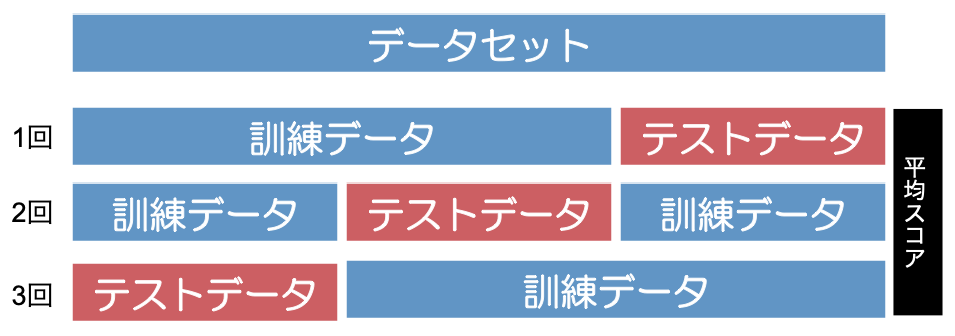
では、繰り返しの回数を5回に設定してクロスバリデーションを実装してみましょう。まずはLassoモデルでクロスバリデーションを行います。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
[In ] : #必要なモジュールのインポート from sklearn.model_selection import ShuffleSplit, cross_val_score #データセットをランダムに5分割するための変数cvを定義 cv = ShuffleSplit(n_splits=5, test_size = 0.2, random_state=0) #cvを用いてクロスバリデーションを実行 scores = cross_val_score(Lasso, boston_features, boston_target, cv=cv) #結果を表示 print(scores) print("R-squared_Average : {0:.2f}".format(scores.mean())) |
|
1 2 3 4 5 6 |
[Out ] : [0.55697477 0.65577592 0.59410602 0.78246293 0.78063311] R-squared_Average : 0.67 |
この結果から、データの分割の仕方によって結果が大きく変動していることがわかりますね。では、次にRidgeモデル、線形モデルについても同様にクロスバリデーションを行います。
|
1 2 3 4 5 6 7 8 9 10 |
[In ] : #cvを用いてクロスバリデーションを実行 scores = cross_val_score(Ridge, boston_features, boston_target, cv=cv) #結果を表示 print(scores) print("R-squared_Average : {0:.2f}".format(scores.mean())) |
|
1 2 3 4 5 6 |
[Out ] : [0.58364982 0.67498977 0.62322026 0.79457322 0.77713899] R-squared_Average : 0.69 |
|
1 2 3 4 5 6 7 8 9 10 |
[In ] : #cvを用いてクロスバリデーションを実行 scores = cross_val_score(LinReg, boston_features, boston_target, cv=cv) #結果を表示 print(scores) print("R-squared_Average : {0:.2f}".format(scores.mean())) |
|
1 2 3 4 5 6 |
[Out ] : [0.58922238 0.67790515 0.62474713 0.79455314 0.7751921 ] R-squared_Average : 0.69 |
以上の結果から、今回の分類に関しては、Ridgeモデル、線形モデルの方がLassoモデルよりも優れていることを確認できました。なお、ここではクロスバリデーションについて紹介しましたが、モデルの評価と選択のための手法は他にもあります。こちらの記事ではハイパーパラメータチューニングという手法についてまとめてありますので、併せてご覧ください。
まとめ
いかがでしたでしょうか。scikit-learnの基本的な使い方はお分かりいただけたかと思いますが、本稿でご紹介したscikit-learnの機能はほんの一部にすぎません。scikit-learnを使いこなせるようになれば基本的な機械学習の実装は扱えると思うので、公式サイトも頼りに色々な手法を試してみてください。
また、機械学習で用いられている数学や統計の基礎について学びたい方には、こちらの無料コースがオススメです。
さらに、それぞれの機械学習アルゴリズムについてより詳しく学びたいという方は、ぜひ、以下のコースをご利用ください。

